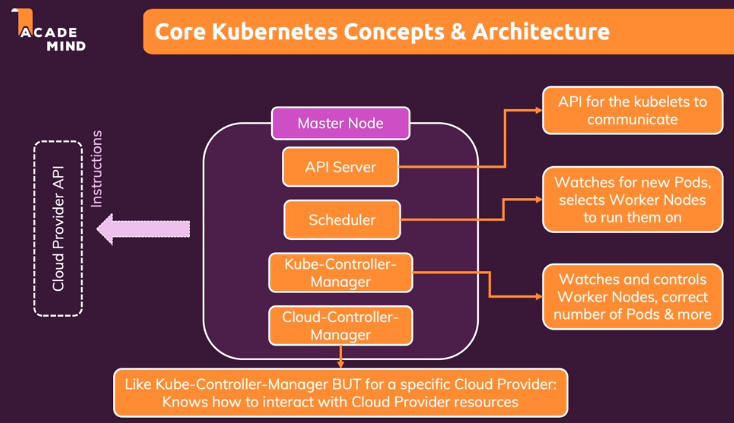
< First-Class 함수 >
First-Class 함수 : 프로그래밍 언어가 함수(Function)를 first-class 시민으로 취급하는 것
함수가 다른 함수의 인자로 전달될 수 있고, 함수의 결과로 리턴될 수 있고,
변수에 함수를 할당하거나 list 등의 구조 안에 함수를 할당하는 것이 가능하다는 말임
< closures >
closure : 자신의 영역 밖에서 호출된 함수의 변수값과 레퍼런스를 복사하고 저장한 뒤,
이 캡처한 값들에 액세스할 수 있게 도와줌
free variable : 코드블럭안에서 사용은 되었지만, 그 코드블럭안에서 정의되지 않은 변수
| def outer_func(): message = 'Hi' def inner_func(): print(message) return inner_func my_func = outer_func() my_func() # Hi 가 출력됨 |
my_func 에서 __closure__ 라는 속성을 확인할 수 있으며, __closuer__ 는 tuple 임
__closuer__ 에는 cell 이라는 요소가 포함되어있으며
이 cell.cell_contents 를 열어보면 "Hi" 라는 글자가 있음
클로저는 지역 변수와 코드를 묶어서 사용하고 싶을 때 활용
클로저에 속한 지역 변수는 바깥에서 직접 접근할 수 없으므로 데이터를 숨기고 싶을 때 활용
< Iterator, Genrator, Decorator >
- Iterator : 요소가 복수인 컨테이너 타입 객체들(list, tuple, set, dironary, string)에서
각 요소를 하나씩 꺼내 반복적으로 처리할 수 있도록 하는 방법을 제공하는 객체
list, tuple 등의 객체들이 갖는 __iter__() 함수를 통해 Iterator 구현이 가능함
| mytuple = (1,2,3) myit = iter(mytuple) print(next(myit)) #1 print(next(myit)) #2 print(next(myit)) #3 |
- Generator : Iterator 의 한 종류이며, 메모리를 효율적으로 사용하면서 반복을 수행하도록 돕는 객체
미리 요소를 리스트에 만들어 놓고 꺼내는 것이 아니라,
yield 및 __next__() 함수를 통해서 필요할 때마다 접근/생성하여 요소를 빼냄
| def yield_test(): for i in range(5): yield i print(i,'번째 호출!') print(type(yield_test())) # <class 'generator'> yield 가 사용되면 generator 가 되나 봄 t = yield_test() print(t.__next__()) # 0 print(t.__next__()) # 0 번째 호출! 1 print(t.__next__()) # 1 번째 호출! 2 print(t.__next__()) # 2 번째 호출! 3 print(t.__next__()) # 3 번째 호출! 4 #print(t.__next__()) #Error |
함수 내에서 yield 함수를 사용하여 값을 지정해두면,
추후 __next__() 를 통해 값을 불러올 수 있음
__next__() 함수가 실행되면, 내부에서 yield 를 실행하고 멈추며, 다시 실행하면 멈춘 곳부터 다시 실행
yield 키워드 위치에서 함수가 끝나지 않은 유휴 상태로 대기함
이렇게 generator 를 사용하면, 필요할 때 마다 해당 객체를 통해 요소를 반환할 수 있음
함수를 완전 실행시키는 것이 아니라, 일부를 실행시키고 일시 정지하기 때문에, 함수의 재사용성이 높아지고
전체 요소를 메모리에 저장할 필요가 없어 비용효율적임
- Decorator : 기존의 코드에 여러가지 기능을 덧붙여 실행하는 파이썬 구문
이미 만들어져 있는 기존의 코드를 수정하지 않고
(기존 코드와 새로 추가한 코드가 혼합된 래퍼(wrapper) 함수를 이용하여) 여러가지 기능을 앞뒤에 추가하기 위해 사용함
대개 로그를 남기는데 사용되거나, 프로그램의 성능 테스트(실행 시간 측정)하기 위해서도 많이 쓰임
기존 코드 중간에 뭔가 넣는 작업은 할 수 없고,
단지 작업의 앞 뒤에 추가적인 작업을 손쉽게 넣어 사용하도록 하는 역할만 함
| def decorator_function(original_function): def wrapper_function(): print('{} 함수가 호출되기전 입니다.'.format(original_function.__name__)) # 꾸미고 싶어 추가한 부분 return original_function() return wrapper_function def display_1(): #수정하고 싶지 않은 함수 display_1 print('display_1 함수가 실행됐습니다.') display_1 = decorator_function(display_1) # display_1 함수를 인자로 넘기고 래퍼함수를 받음 display_1() |
일반적으로는 @ 를 사용하여 데코레이터 함수와 연결한다고 함
| def decorator_function(original_function): # original_function 에 display_1 이 들어감 def wrapper_function(): print('{} 함수가 호출되기전 입니다.'.format(original_function.__name__)) return original_function() return wrapper_function @decorator_function def display_1(): # 꾸미고 싶은 대상. display_1 이 decorator_function 의 인자( original_function )로 들어감 print('display_1 함수가 실행됐습니다.') # display_1 = decorator_function(display_1) display_1() |

복수의 데코레이터를 동시에 사용하면, 아래쪽 데코레이터부터 실행되는데
첫번째 데코레이터를 통해 리턴받은 래퍼 함수 대상으로 다시 두번째 데코레이터가 실행됨
import functools.wraps 의 wraps 를 (데코레이터 내부의) 래퍼 함수에 @ 로 걸어줌
< REPL >
REPL : Read-Eval-Print-Loop
인터프리터 언어인 python 는 REPL 이 기본
< magic method >
매직 메소드란, 클래스안에 정의할 수 있는 스페셜 메소드.
클래스를 (int, str, list 등의) 파이썬 빌트인 타입(built-in type)과 같이 작동하도록 만들어 줌
클래스를 만들때 항상 사용하는 __init__이나 __str__는 가장 대표적인 매직 메소드
__init__ 메소드는 class 의 instance 를 생성할 때 자동으로 실행됨
int(3)+2 를 실행하면 5가 나오는데, 그 이유는 '+' 가 매직메소드인 __add__() 를 호출하여
int(3).__add__(2) 를 실행하기 때문
직접 만든 class 의 +, -, <, init 등의 매직 메소드들을 커스터마이징하여
원하는 기능대로 동작할 수 있도록 만들면 편함
< 클래스 변수 >
클래스의 인스턴스가 아닌, 클래스 자체에 붙어있는 변수
| class MyClass: class_var = "Hi!" def __init__(self): print(MyClass.class_var) print(self.class_var) my_class = MyClass() |
self.class_var 로 접근 가능함
python 은 네임스페이스를 찾을 때 아래와 같은 순서로 찾기 때문.
인스턴스 네임스페이스(self.class_var) 로 찾아서 없으면
바로 위 클래스 네임스페이스(MyClass.class_var) 로 찾음

__init__ 함수를 통해 인스턴스 변수를 설정하는 방법 외에
아래와 같이 직접 인스턴스를 통해 변수를 집어넣는 방법도 있음
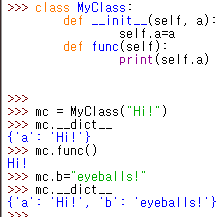
클래스 변수는 해당 클래스의 인스턴스들끼리 공유하는 전역변수처럼 사용이 가능......

...그럼 클래스 변수는 메모리에 올라와 있다는 말이 됨
< 인스턴스 메소드, 클래스 메소드, 스태틱 메소드 >
인스턴스 메소드 : 인스턴스를 통해서만 호출이 됨
인스턴스 메소드의 첫 번째 인자로 인스턴스 자신을 자동으로 전달
관습적으로 이 인수를 ‘self’라고 칭함
클래스 메소드 : 클래스 변수와 마찬가지로, 클래스 내 모든 인스턴스가 공유 가능한 메소드
클래스 메소드는 ‘cls’인 클래스를 인자로 받고,
(모든 인스턴스가 공유하는 클래스 변수 같은) 데이터를 생성, 변경 또는 참조하기 위한 메소드
| < 클래스 메소드를 사용하지 않은 버전 > | < 클래스 메소드를 사용한 버전 > |
 |
 |
클래스 메소드에서 사용되는 cls 는 클래스 자기 자신을 의미함.
따라서 위의 오른쪽 예제처럼, 클래스 메소드를 호출함으로서 (클래스를 리턴받아 ) 클래스를 만드는 게 가능
팩토리 메소드 역할을 함
클래스 변수를 업데이트해야 한다면, 클래스 메소드를 이용해서 업데이트하는 게 좋다고 함
데이터 검사나 다른 부가 기능 추가가 용이해서
스태틱 메소드 : 위의 두 메소드와는 다르게, 인스턴스나 클래스를 첫 번째 인자로 받지 않음
스태틱 메소드는 클래스 안에 정의되어, 클래스 네임스페이스 안에 있을뿐
일반 함수와 전혀 다를게 없음
클래스와 연관성이 있는 함수를 클래스 안에 정의해두고
클래스나 인스턴스를 통해서 호출하여 편하게 사용
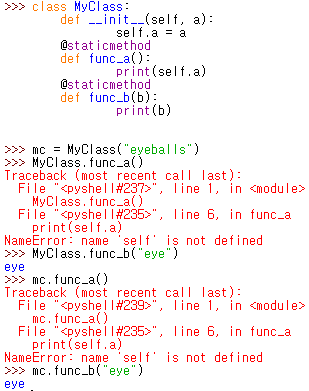
staticmethod 인 func_a 와 func_b 를 통해
staticmethod 에서는 self 에 접근이 불가능하다는 것과
staticmethod 는 클래스 및 인스턴스를 통해 호출 가능하다는 것을 확인
추가로 staticmethod 는 클래스 변수에도 접근 가능함
자바의 static method 와 동일하다고 보면 될 듯
staticmethod 는 클래스와 연관된 순수함수를 설정할 때 사용하고,
classmethod 는 (위 예제처럼) 팩토리 메소드로 사용하거나, 클래스 변수를 변경할 때 사용
(그렇다고 staticmethod 가 클래스 변수를 변경하지 못하는 건 아님)
< 클래스 속성(인스턴스 변수들) 확인하는 방법 >
__dict__ 를 사용하여 확인 가능
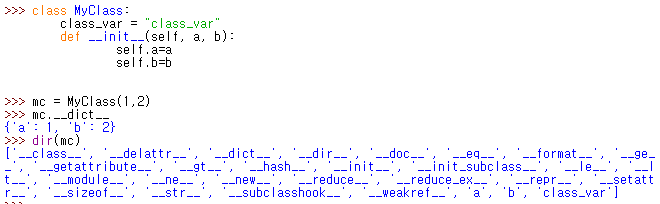
위 예제에서 볼 수 있듯이
클래스 변수는 보이지 않고 인스턴스 변수만 확인 가능
dir() 는 해당 객체로 사용 가능한 내장 함수 리스트를 보여줌
< 오버라이딩에서 사용하는 super >
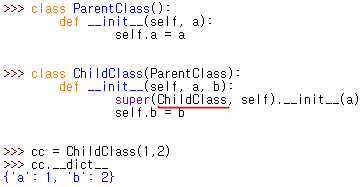
부모 클래스의 메소드를 호출할 때 사용하는 super 에 자기 자신의 클래스를 넣어줘야 함....
안 그러면 에러가 남
< underscore(_) 사용법 >
1. Python Interpreter 에서 마지막에 실행된 결과값으로 사용
| >>> 10 10 >>> _ 10 >>> _ * 3 30 |
2. 값을 무시하고 싶을 때 사용
| x, _, y = (1, 2, 3) # x = 1, y = 3 x, *_, y = (1, 2, 3, 4, 5) # x = 1, y = 5 for _ in range(1, 4): print(_) # 1,2,3 이 출력됨 |
3. private 으로 만들고 싶을 때 사용
가령 _로 시작하는 변수와 메소드를 갖는 모듈을 from module import * 로 임포트 한다면
_ 로 시작하는 변수, 메소드는 임포트에서 무시됨
(하지만 직접 module._... 을 통해 접근은 가능하여, 진정한 private 접근 제어는 아님)
| def __init__(self): pass _a = "a" #private 변수. import * 에서 제외됨 b = "b" def _echo(self, x): #private 메소드. import * 에서 제외됨 print x def func(self): print("eyeballs") |
4. 매직메서드에 사용
__init__, __len__ 등
__file__ 은 현재 파이썬 파일의 위치를 나타내며
__eq__ 은 'a == b' 같은 식이 수행될 때 호출되는 메소드
5. 맹글링 규칙을 이용하여 오버라이드를 피하기 위해 사용
맹글링이란, 컴파일러나 인터프리터가 변수/함수명을 그대로 사용하지 않고
일정한 규칙에 의해 변형시키는 것을 의미함
파이썬의 맹글링 규칙중에는 다음과 같은 규칙이 있음
"속성명이 double underscore (__) 로 시작한다면, 이때 속성명 앞에 _ClassName 을 붙임"
| class MyClass: a = "a" __d = "d" #맹글링 대상 def b(self): pass def __c(self): #맹글링 대상 pass dir(MyClass()) ['_MyClass__c', '_MyClass__d', ... 'a', 'b'] |
이게 어디서 유용한가?
상속받은 자식클래스에서 동일한 이름의 변수/함수명을 사용하고 싶은데, 오버라이딩은 하기 싫을 때 사용함.
< Asterisk(*) 이해하기 >
1. 곱셈(2*3 = 6) 및 제곱(2**3 = 8) 에 사용
2. 리스트형 컨테이너 타입의 반복 확장에 사용
| >>> zero_list = [0]*10 >>> zero_list [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] >>> zero_tuple = (0,)*10 >>> zero_tuple (0, 0, 0, 0, 0, 0, 0, 0, 0, 0) |
3. 가변인자 (Variadic Parameters)에 사용
packing : args, kwargs 를 통해 컨테이너 타입 형태로 데이터(가변인자)를 받는 것
*args : positional arguments 를 받음. arguments 몇개 받는지 모르는 경우 사용. 튜플 형태로 넘어옴

**kwargs : keyword argument 의 약자. keyword arguments 를 받음
args 와 동일한 역할을 하며 key, value 를 함께 전달해야 함. key value 형태가 아니면 에러가 남
dict 형태로 넘어옴

두 가지 모두 함께 쓸 수 있음. args 가 먼저 와야하며, 함수 사용할때도 args 인자가 먼저 와야 함

4. 컨테이너 타입 데이터(list, tuple, dict) 를 unpacking 할 때 사용
unpacking : 컨테이너 타입 데이터를 (가변인자나 변수에 넣기 위해) 앞에 * 를 붙이는 것
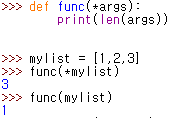 |
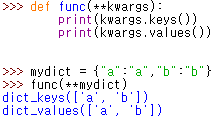 |
또한 리스트 혹은 튜플을 unpacking 한 후 다른 변수에 packing 하여 넣기도 함
| numbers = [1, 2, 3, 4, 5, 6] # unpacking의 좌변은 리스트 또는 튜플의 형태를 가져야하므로 단일 unpacking의 경우 *a가 아닌 *a,를 사용 *a, = numbers # a = [1, 2, 3, 4, 5, 6] *a, b = numbers # a = [1, 2, 3, 4, 5] # b = 6 a, *b, = numbers # a = 1 # b = [2, 3, 4, 5, 6] a, *b, c = numbers # a = 1 # b = [2, 3, 4, 5] # c = 6 |
< print 대신 logging 을 사용하는 이유 >
1. 로깅 레벨 조정 가능 (debug, info, warning, error, critical)
2. stdout 뿐 아니라 file 로 로그를 저장할 수 있음
3. 로깅 포맷 편집 가능 (파일 이름, 라인 넘버, 로그 메세지, 프로세스/스레드 이름, 시간 등)
4. 시간에 따라 로그 파일 생성 가능. 가령 5분 단위로 로깅하여 파일을 생성
< Trailing comma >
리스트나 튜플을 만들 때 가장 마지막에 넣는 comma ( , )
사람의 실수를 방지하기 위해 넣음
< Comprehension >
Comprehension : iterable한 오브젝트를 생성하기 위한 방법 중 하나.
for 문과 if 문이 혼합된 단 한 줄의 코드로 iterable 한 객체를 생성할 수 있음
4 종류가 있으며, 예제는 아래와 같음
- List Comprehension
- numbers = [n for n in range(10)] # [0,1,2,3,4,5,6,7,8,9]
- evens = [n for n in range(10) if n%2==0] # [0, 2, 4, 6, 8]
- Set Comprehension
- evens = {n for n in range(10) if n%2==0} # {0, 2, 4, 6, 8}
- Dict Comprehension
- example = {k:v for k,v in (('a',1),('b',2))} # {'a': 1, 'b': 2}
- Generator Expression
- 한 번에 모든 원소를 반환하지 않음. 한 번 실행 할 때 원소 하나만 반환

< if __name__ == "__main__":의 의미 >
eye.py 라는 이름의 파이썬 파일이 아래와 같이 존재하는 경우
| < eye .py > def echo(a): print(a) if __name__ == "__main__": echo("Hello eyeballs!") |
이 eye .py 를 직접 실행하면 eye .py의 __name__ 변수에는 "__main__" 값이 저장됨
따라서 if __name__=="__main__" 의 값이 True 이므로 echo("Hello eyeballs!") 를 실행함
만약 파이썬 쉘이나 다른 파이썬 모듈에서 eye 를 import 하는 경우
import eye
from eye import echo
eye.py의 __name__ 변수에 eye.py의 모듈 이름인 "eye" 가 저장됨
따라서 if __name__=="__main__" 의 값이 False 이므로 echo("Hello eyeballs!") 를 실행하지 않음
즉, if __name__=="__main__" 는 python 모듈을 직접 실행할 때
수행하는 코드를 넣는 부분임
< 특정한 위치에 존재하는 모듈 import 하기 >
import sys
print(sys.path)
위 명령어로 나오는 path 들은 python lib 가 설치되어있는 위치들임
이 sys.path 에 원하는 모듈이 존재하는 path 를 추가하면, 해당 모듈은 import 가 가능하게 됨
sys.path.append("/my/module/path")
< package 에 포함된 __init__.py 용도 >
1. 해당 dir 가 패키지의 일부임을 알려주는 역할
2. 해당 패키지 내 모듈에서 사용 가능한 공통 변수 및 함수를 넣을 수 있음
3. 해당 패키지 내 모듈에서 공통적으로 import 해야 할 다른 모듈을 import 해두어, 미리 import 할 수 있음
4. 해당 패키지 내 모듈에서 먼저 실행되어야 하는 공통 코드(이를테면 초기화 코드 등) 를 넣을 수 있음
< 일부러 에러 발생시키기 >
raise NotImplementedError
< GIL >
python global interpreter lock 에 대해 반드시 공부
참고
https://mingrammer.com/underscore-in-python/
https://mingrammer.com/understanding-the-asterisk-of-python/
'눈가락' 카테고리의 다른 글
| [AWS EMR] step 추가하여 shell command 실행하는 방법 (0) | 2024.05.07 |
|---|---|
| Gradle 공부 필기 (0) | 2024.04.01 |
| [JAVA] enum 간단한 샘플 코드 (0) | 2023.08.20 |
| [JAVA] Generic 간단한 샘플 코드 (0) | 2023.08.20 |
| [리뷰] 페어페딕7 카키 한 달 사용 후기 (1) | 2023.01.07 |