Spark Documentation 문서 번역을 한 번 해보려고 한다.
눈가락번역기의 번역 상태가 많이 좋지 않으니 양해 바람.
번역 대상 문서 : https://spark.apache.org/docs/latest/tuning.html
Memory Management Overview
메모리 관리 개요
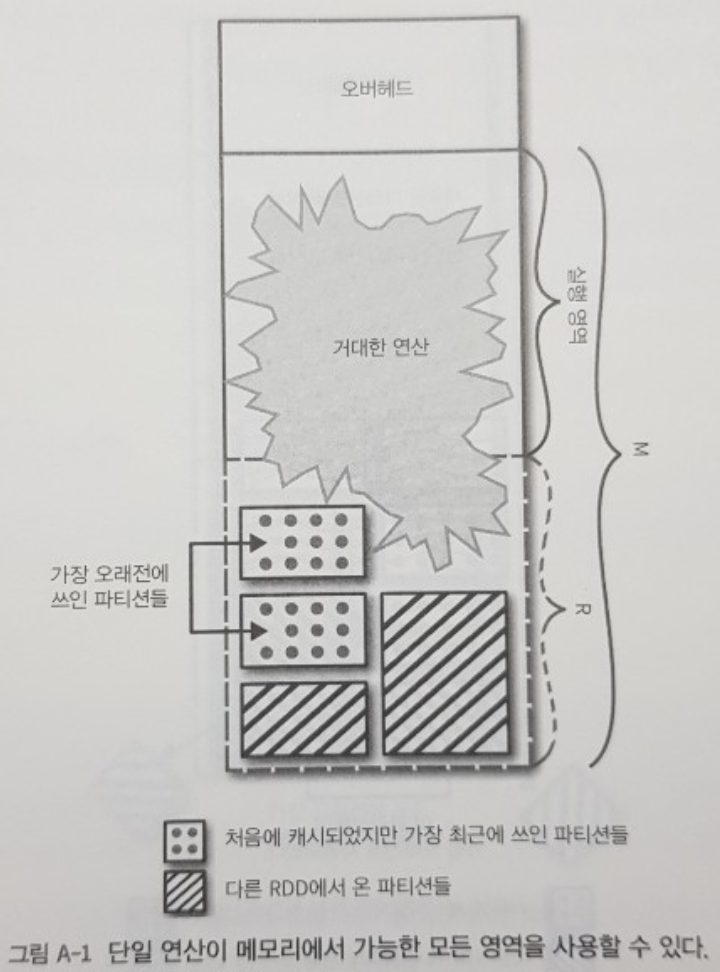
Memory usage in Spark largely falls under one of two categories: execution and storage.
Spark 에서 메모리 사용은 넓게 다음 두 카테고리 중 하나에 속한다. 실행execution과 저장storage
Execution memory refers to that used for computation in shuffles, joins, sorts and aggregations,
"실행 메모리"는 셔플이나 조인, 정렬, 집계 계산을 위해 사용되는 메모리다.
while storage memory refers to that used for caching and propagating internal data across the cluster.
반면 "저장 메모리"는 클러스터 전체에 내부 데이터를 캐싱하고 전파하는 데 사용되는 메모리다.
In Spark, execution and storage share a unified region (M).
Spark 에서, 실행과 저장은 하나의 통합된 공간을 공유한다 (위 그림의 M 부분)
When no execution memory is used, storage can acquire all the available memory and vice versa.
만약 실행 메모리가 사용되지 않는다면, 저장 메모리는 가용한 메모리를 모두 얻을 수 있으며, 그 반대도 마찬가지다.
Execution may evict storage if necessary, but only until total storage memory usage falls under a certain threshold (R).
실행은 필요하다면 저장을 밀어낼 수 있지만, 전체 '저장 메모리' 사용률이 특정 threshold 를 넘긴 상태여야 저장을 밀어낼 수 있다.(위 그림의 R 부분)
In other words, R describes a subregion within M where cached blocks are never evicted.
다른 말로 하면, R 은 M 의 하위 공간이며, 캐싱된 데이터가 절대 밀리거나 사라지지 않는 공간이다.
Storage may not evict execution due to complexities in implementation.
저장공간은 구현의 복잡성 때문에 실행 공간을 밀어내지 않는다.
This design ensures several desirable properties.
이러한 디자인은 몇 가지 특징들을 가져온다.
First, applications that do not use caching can use the entire space for execution, obviating unnecessary disk spills.
첫째, 캐싱 기능을 사용하지 않는 applications 는 실행을 위해 전체 메모리 공간을 사용할 수 있고, 그에 따라 불필요한 디스크 스필을 방지할 수 있다.
Second, applications that do use caching can reserve a minimum storage space (R) where their data blocks are immune to being evicted.
두번째, 캐싱 기능을 사용하는 applications 는, 캐싱 데이터가 메모리에서 밀리거나 사라질 걱정 없는 최소 저장공간을 R 자리에 예약해둘 수 있다.
Lastly, this approach provides reasonable out-of-the-box performance for a variety of workloads without requiring user expertise of how memory is divided internally.
마지막으로 이러한 접근법은, 메모리가 내부적으로 어떻게 구분되는지 알아야 하는 전문 지식의 유무와 상관없이, 다양한 작업부하에 대해 이미 합리적인 퍼포먼스를 제공한다.
여기서 말하는 out-of-the-box performance 는, 사용자의 추가 설정 없는 순정 상태 메모리의 성능을 말한다고 이해하면 편함.
즉, 사용자가 전문 지식을 갖추고 메모리 이곳 저곳 옵션을 준 게 아님에도 불구하고, 처음부터 기본 성능 자체가 합리적이라는 의미.
Although there are two relevant configurations, the typical user should not need to adjust them as the default values are applicable to most workloads:
관련된 설정값이 두 개가 있지만, 대부분의 유저는 이 옵션값들을 업데이트없이 그냥 기본값으로 두고 사용하는데 그럼에도 대부분의 작업에서 적용될 수 있다.
- spark.memory.fraction expresses the size of M as a fraction of the (JVM heap space - 300MiB) (default 0.6).
spark.memory.fraction 는 M의 크기를 JVM 힙 스페이스 - 300mb 의 비율로 나타낸다. 기본 0.6
The rest of the space (40%) is reserved for user data structures, internal metadata in Spark, and safeguarding against OOM errors in the case of sparse and unusually large records.
남은 공간(0.6에서 남은 공간은 0.4, 즉 40%) 사용자 데이터 구조, Spark 내부 메타데이터, 그리고 혹시모를 희소하고 비정상적으로 큰 데이터에 의한 OOM 에러 방지를 위해 예약된다. - spark.memory.storageFraction expresses the size of R as a fraction of M (default 0.5).
spark.memory.storageFraction 은 R 의 크기를 M의 비율로 나타낸다. 기본 0.5
R is the storage space within M where cached blocks immune to being evicted by execution.
R 은 M 내에 저장데이터를 저장하기 위한 공간이며, 이 공간에서는 실행에 의해 캐시 데이터가 밀려사라지지 않는다.
The value of spark.memory.fraction should be set in order to fit this amount of heap space comfortably within the JVM’s old or “tenured” generation.
spark.memory.fraction 값은 JVM 의 old 나 tenured 세대 데이터 내의 힙스페이스 양을 맞추기 위해 설정되어야 한다.(???)
See the discussion of advanced GC tuning below for details.
아래 GC 튜닝에 대해 더 자세히 의논한 부분을 확인하라.
Determining Memory Consumption
메모리 소비 알아내기
The best way to size the amount of memory consumption a dataset will require is to create an RDD, put it into cache, and look at the “Storage” page in the web UI.
dataset 이 필요로하는 메모리 소비양을 측정할 가장 좋은 방법은 RDD 를 만들어서 캐싱한 후 WebUI 에서 "Storage" 페이지 부분을 확인하는 것이다.
The page will tell you how much memory the RDD is occupying.
이 페이지는 RDD 메모리가 얼마나 많은 공간을 차지하는지 보여줄것이다.
To estimate the memory consumption of a particular object, use SizeEstimator’s estimate method.
특정 객체의 메모리 소비양을 추정하려면, SizeEstimator 의 estimate 메소드를 사용하라.
This is useful for experimenting with different data layouts to trim memory usage, as well as determining the amount of space a broadcast variable will occupy on each executor heap.
이것은 메모리 사용량을 줄이기 위해 서로다른 데이터 레이아웃들을 실험하는 데 유용하고, 또한 각 executor heap 에서 브로드캐스트 변수가 차지하게 될 공간을 파악하는 데 유용하다.
Tuning Data Structures
데이터 구조 튜닝하기
The first way to reduce memory consumption is to avoid the Java features that add overhead, such as pointer-based data structures and wrapper objects.
메모리 소비를 줄이는 첫번째 방법은, pointer 기반의 데이터 구조와 래퍼 객체 같이 오버헤드가 있는 Java feature 사용을 피하는 것이다.
There are several ways to do this:
이를 위한 몇 가지 방법이 있다.
- Design your data structures to prefer arrays of objects, and primitive types, instead of the standard Java or Scala collection classes (e.g. HashMap).
HashMap 같은 일반적인 Java/Scala 컬렉션 클래스 대신, 객체 배열이나 원시타입을 선호하는 데이터 구조를 디자인하라.
The fastutil library provides convenient collection classes for primitive types that are compatible with the Java standard library.
fastutil lib 는, Java 기본 lib 와 견줄만큼 편리한 원시타입 컬렉션 클래스들을 제공한다. - Avoid nested structures with a lot of small objects and pointers when possible.
가능하다면 많은 수의 작은 객체와 포인터들을 갖는 중첩 구조를 갖지 않도록 하라. - Consider using numeric IDs or enumeration objects instead of strings for keys.
문자열 형태의 key 값 대신, 숫자형태의 ID 혹은 열거형 객체 사용을 고려하라. - If you have less than 32 GiB of RAM, set the JVM flag -XX:+UseCompressedOops to make pointers be four bytes instead of eight.
만약 ram 이 32 gb 보다 작다면, 8바이트 포인터 대신 4바이트 포인터를 사용하도록 JVM flag -XX:+UseCompressedOops을 설정하라.
You can add these options in spark-env.sh.
이 옵션은 spark-env.sh 에 추가할 수 있다.
Serialized RDD Storage
직렬화하여 RDD 저장
When your objects are still too large to efficiently store despite this tuning, a much simpler way to reduce memory usage is to store them in serialized form, using the serialized StorageLevels in the RDD persistence API, such as MEMORY_ONLY_SER.
이러한 튜닝에도 불구하고, 효율적으로 저장하기에 객체 크기가 아직 너무 크다면, 메모리 사용률을 줄이는 아주 간단한 방법은 객체를 직렬화하여 저장하는 것이다. RDD persistence API 문서에 따르면, MEMORY_ONLY_SER 같은 직렬화StorageLevel 을 사용하면 된다고 한다.
Spark will then store each RDD partition as one large byte array.
그러면 Spark 는 각 RDD 파티션을 하나의 큰 바이트 배열로 저장 할 것이다.
The only downside of storing data in serialized form is slower access times, due to having to deserialize each object on the fly.
직렬화하여 데이터를 저장하면 생기는 단 하나의 불리한 점은 접근 시간이 느려진다는 것이다. 왜냐면 각 객체를 그때 그때 역직렬화해야 하기 때문.
We highly recommend using Kryo if you want to cache data in serialized form, as it leads to much smaller sizes than Java serialization (and certainly than raw Java objects).
캐싱된 데이터를 직렬화 하고싶다면, Kryo 를 추천한다. Kryo 로 직렬화한 결과는 Java Serialization, 그리고 원시 Java 객체보다 더 작은 크기를 갖게 되기 때문이다.
'English' 카테고리의 다른 글
| Study English 23.08.13 Tuning Spark 번역4 (0) | 2023.08.19 |
|---|---|
| Study English 23.08.12 Tuning Spark 번역3 (0) | 2023.08.19 |
| Study English 23.08.10 Tuning Spark 번역1 (0) | 2023.08.19 |
| Study English 23.08.09 : Monitoring and Instrumentation 번역2 (0) | 2023.08.19 |
| Study English 23.08.08 : Monitoring and Instrumentation 번역1 (0) | 2023.08.19 |