https://youtu.be/quzbmlYO7Rc?si=VmDoQ5gdQ-_V-EZp&t=2103
< 데이터 모델링이란 >
DB 사용자들이 필요로 하는 정보들을 도출하기 위해
최적의 자료 저장 구조가 되도록 데이터베이스, 테이블을 설계하는 기법
다르게 말하면, BI 팀에서 원하는 정보를 쉽고 빠르게 쿼리할 수 있도록
최적의 테이블 구조를 설계하는 것 (최적의 테이블 관계를 구축해두고, 데이터 IO 도 빠르게 할 수 있도록 설정해두고)
데이터의 논리적인 모델링을 진행하기 위해 아래 개념을 사용
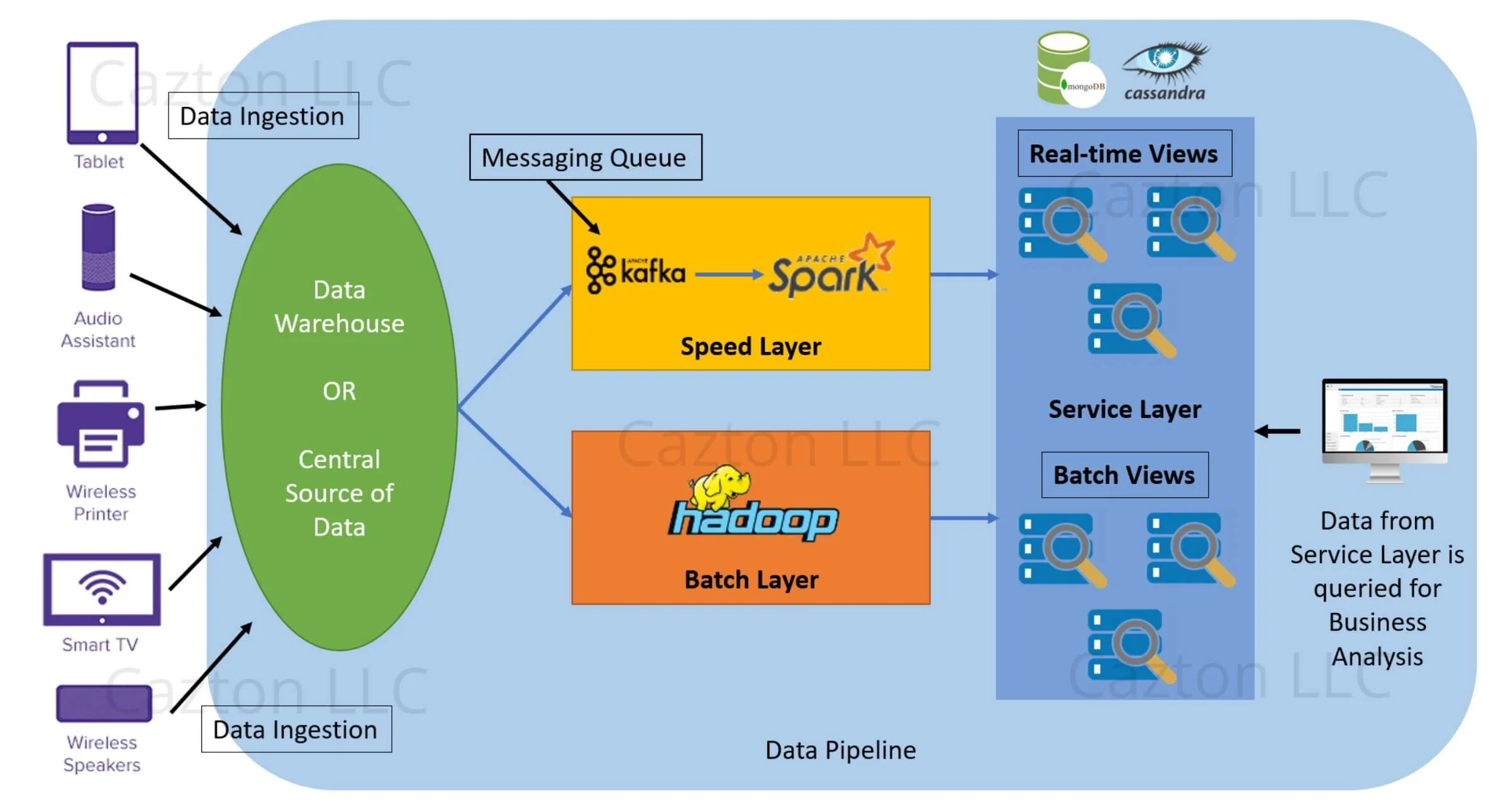
- Entity(개체) : 테이블. ex) 학과 테이블, 학생 테이블
- Relationship : 테이블 간 관계. ex) 학생이 듣는 과목 코드(FK)-학과 코드(PK)
- Attribute : 테이블의 스키마. ex) 학생 테이블에는 학번, 이름, 주소, 성별, 전공 등 (key 값을 포함)
- Identifier : 테이블의 key.
위 그림에서 네모박스는 Entity, 그리고 가장 첫 번째 속성은 PK
이 네 가지 개념을 잘 이해해두자
< 데이터 모델링 마인드 >
메모리를 효율적으로 사용해야 함
읽는 순서를 바꾸거나, fact table 을 어떻게 설계하는지에 따라 메모리 효율이 달라짐
메모리 효율이 좋아지면 다른 사용자와 공유할 메모리가 더 많아지고 더 많은 일을 처리할 수 있게 됨
< 논리 데이터 모델링 >

논리 데이터 모델링은 Entity(테이블) 를 파악하는 작업으로 시작
Entity 란, 정보를 갖고 있거나 그에 대한 정보를 알아야 하는 유무형의 사물이나 객체
"정보를 갖고 있는 thing" 이라고 이해하면 됨
< Entity 특성 >
Entity 는 2 가지 특성이 존재함. 이 두 가지 특성이 없으면 Entity 가 아님
이 두 가지 특성은 데이터의 '무결성'을 지키기 위한 최소한의 안전장치가 됨
- 상호 배타성(Mutual Exclusivity) : 모든 인스턴스는 하나의 Entity에만 속해야 함
하나의 데이터(Instance)는 논리적으로 단 하나의 엔티티에만 소속되어야 함.
Entity 간의 경계가 모호하면 데이터가 중복되고 정합성이 깨지게 됨
예를 들어, A table 에 내 이름 정보가 있는데 B table 에도 내 이름 정보가 있으면 안 됨
(이런 경우 테이블 하나를 PK-FK 로 묶어 사용해서, 중복된 정보를 줄여야 함)
'커피'라는 정보가 음료table 에도 들어갈 수 있고 각성제table 에도 들어갈 수 있는데 이렇게 만들면 안 됨
나중에 커피 정보 찾을 때 어떤 테이블에서 찾아야 하는지 모르게되니까
- 식별성(Identifiability) : Entity 내에 포함된 모든 인스턴스들은 유일한 식별자에 의해 식별 가능해야 함. PK 말하는 거임
Entity 는 무조건 PK 를 포함해야 함. 그래서 row(instance) 를 유일하게 식별해낼 수 있어야 함
식별성을 갖추지 못하면, 데이터 update, delete 를 할 수 없게 됨
동일한 값을 갖는 여러 instances 에서 내가 원하는 것만 업데이트 할 수 없게 되니까
< Entity 유형 >
Entity 는 3 가지 유형으로 존재함
- Fundamental Entity : 특정 범주에 속하지 않는 기본 개념(특성) 정보를 포함하는 Entity
정보 처리를 위해 기본적으로 존재하는 코드성 Entity
물리적 실체가 있음 (사람, 물건)
다른 Entity 에 의존하지 않고 독립적으로 생성될 수 있어야 함
예를 들어, 강사 Entity - 가르치는 강의가 없어도 시스템에 등록될 수 있음
상품 Entity, 고객 Entity, 계좌 Entity 등
- Conceptual Entity : 업무 처리를 위한 무형의 개념/과정을 체계화 시킨 Entity
눈에 보이진 않지만, 데이터를 분류하거나 관리하기 위한 규칙을 정의할 때 사용되는 Entity
예를 들어, 강의 카테고리 Entity - 프로그래밍, 자료구조 등 '카테고리' 자체는 보이지 않지만 강의를 논리적으로 구분지어줌
구독 플랜 Entity - 서비스의 정책을 (실체는 없지만) 데이터화함
부서 Entity - 눈에 보이지 않지만 A부서, B부서 등 체계화 가능
전공 Entity, 학기 Entity, 등급 Entity, 거래 상태 Entity 등
- Associate/Intersection Entity : 두 개 이상의 Entity 를 결합할 때 사용되는 Entity.
두 Entity(Entity 종류에 상관없음) 사이에서 일어나는 '이벤트'를 기록하는 Entity
예를 들어, 수강신청(Enrollment) - 학생 Entity 와 강의 Entity 를 같이 묶어주는 역할
장바구니 - 고객Entity 와 상품Entity 를 묶어주는 Entity
결제내역 - 고객 Entity 와 주문 Entity 를 묶어주는 Entity (이력이 저장됨)
Associate Entity 는 Entity 와 Entity 간 M:N 관계를 연결짓기 위해 사용됨
(RDB 는 Associate Entity 없이 M:N 를 표현할 수 없음)

M:N 관계 예: 한 명의 학생은 여러 강의를 들을 수 있음(1:N).
하나의 강의는 여러 학생들에 의해 수강됨(M:1)
이 둘을 연결하는 '수강신청' Entity 는 M:N이 됨.
이 Associate Entity 는, 양 쪽 Entity로부터 PK 를 FK 로 가져와서 자신의 PK 로 사용하고, 연결 정보를 row 로 표현함
M:N 관계를 엉성하게 모델링해두면, 최악의 경우 CARTESIAN JOIN 이 발생할 수 있고 성능 악화로 이어짐
반대로 말하면, Catesian product 를 피하는 방법으로 associate entity 를 사용할 수 있음
Fundamental Entity 는 데이터의 근간(Master)
Conceptual Entity 는 데이터의 분류 및 정의
Associate Entity 는 의존적관계 및 트랜잭션 기록
데이터 모델링을 처음 시작할 때, Fundamental Entity 를 먼저 찾고
그 주변에 Conceptual Entity 를 세우고,
마지막으로 둘 사이의 상호작용을 Associate Entity로 정의해볼 수 있음
특히 Associate Entity는 Fact Table의 모태가 되는 경우가 많음
예를 들어, 수강신청 Entity에 수강료, 신청일시 같은 측정값(Measure)이 붙기 시작하면 Fact 데이터가 됨
< Entity 구분 >
PK-FK 로 연결된 두 Entity 를 부를 때, 상위 Entity, 하위 Entity 라고 부르는 경우가 있음
영어로는 Super Type Entity, Sub Type Entity
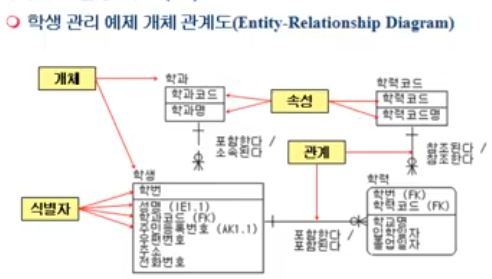
상위 Entity : 다른 Entity에 의해 PK 가 FK 로 사용된(연결된) Entity. 위 예제에서 '고객 Entity', '부서 Entity', '특기 Entity'
하위 Entity : FK 를 갖고있는 Entity (=다른 Entity의 PK 를 FK 로 가지고 있는 경우). 위 예제에서 '계좌 Entity', '사원 Entity'
하위 Entity 가 상위 Entity 가 될 수 있음 (하위 Entity 가 다른 Entity와 관계를 맺게되는 경우)
위 예제에서
고객Entity 가 상위, 계좌Entity 가 하위,
계좌Entity 가 상위, 거래Entity 가 하위
즉, 계좌Entity 처럼 Entity 는 상위도, 하위도 될 수 있음
모든 Entity 는 관계로 맺어지므로, 모든 Entity 들은 상위/하위로 구분이 지어지게 됨
< Entity 정의 >
Entity 명칭, Entity 설명, Entity 범주(카테고리), 약어 및 동의어, 데이터 출현 건수 및 예상 변화 등을 고려하자
예를 들어,
Entity 이름 : 단수의 의미있는 이름으로 명명
상호배타성 : 하나의 정보는 하나의 Entity 에 들어가도록(필요한 정보 찾을 때 어떤 Entity에 있는지 바로 알 수 있도록)
크기 및 사용성 : Entity의 총 길이, 사용 빈도, 메모리 사용량 등을 고려. 성능을 올리기 위함
정규화 : 얼마나 정규화 되어있는지
...
< Entity 사례들 >
1.

a) 공통 코드 Entity 에 0으로 시작하는 코드는 전산실, 1로 시작하는 코드는 방송실,..
이렇게 하면, 공통 코드 Entity 를 읽고 프로그래밍으로 '0으로 시작하는가? 전산실' 이렇게 따로 처리를 해줘야 함
데이터 처리할 때는 추가적인 프로그래밍 없이 쿼리를 할 수 있어야 함
따라서, 하나의 Entity 에 여러 의미를 갖도록 하지 말자
b) 공통 코드 Entity 를 프로그래밍 없이 관계를 맺어서 사원 테이블에 적용하려고 하면, 관계가 너무 복잡해짐
이것도 안 좋은 설계임. 관계가 너무 복잡해지지 않도록 하자
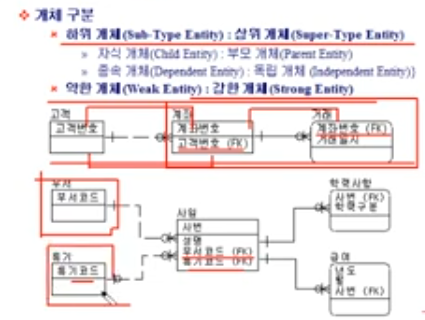
c) 부서, 직종 등을 각각의 Entity 로 잘게 나눠서, 각각 관계를 맺도록 함
쿼리 퍼포먼스는 a, b 에 비해 좋을지 모르나,
Entity 가 늘어나면 늘어날수록 관리하기가 힘들어짐
따라서, 논리적 모델링에서 Entity 가 늘어나는 경우도 고려해야 함
d) 핵심적인 Entity 만 따로 만들어두고(부서, 직종, 직위), 나머지들은 공통 코드 Entity 로 하나로 묶어서 사용
이러면 Entity가 늘어나는 일을 방지할 수 있음

단일 사례를 각각의 Entity 로 만들면, 사례가 늘어날수록 Entity 도 같이 늘어나서 확장성이 떨어짐.
성능도 안 좋아지고 운영도 복잡해짐
따라서 단일 사례를 Entity 로 만들지 말고, 하나의 Entity 로 만들어서 관리하는 게 좋음

a) 품목 Entity 는 자주 자주 쿼리되는 Entity 임. 대중소구분 Entity 들이 모두 연결되어 있으니 성능이 좋지 않음
하지만 소구분Entity 가 없는 품목을 저장할 수 있음
b) 자주 쿼리되는 품목 Entity 하나의 Entity(소구분)만 연결되어 있어서 쿼리 성능이 좋으나,
대중소Entity 들의 PK가 계속 길어지는 단점이 발생

c) PK 가 길어지지 않도록, 상위 Entity 의 PK 만 유지함
하지만 만약, 품목 Entity 가 중구분Entity 와 join 해야하는 상황이 발생하면
반드시 소구분 Entity 와 join 해야 함
이것이 성능 상 단점이 될 수 있음
d) 그럼 소구분 Entity 를 join하지 않고 바로 중, 대구분 Entity 로 join할 수 있도록, 품목 Entity 에 대중소 FK를 모두 넣으면?
이건 가장 안 좋은 케이스
왜냐면 Circular Dependency/Relationship 가 발생하기 때문.
예를 들어,
- Entity A: Department (부서) -> 부서를 관리하는 '부서장(Employee)' 정보를 FK로 설정
- Entity B: Employee (직원) -> 직원이 소속된 '부서(Department)' 정보를 FK로 설정
이렇게 되면 A가 B를 참조하고, B가 다시 A를 참조하는 형태가 됨
Circular Dependency 를 만들면 어떤 일이 발생하는가?
- 데이터를 처음 넣을 때 문제가 발생
부서를 만들려면 부서장(직원)이 이미 있어야 하고, 직원을 만들려면 소속 부서가 이미 있어야 하니, 데이터를 넣을 수 없게 됨
- 데이터를 삭제 할 때 문제가 발생
- 쿼리 진행시 잘못하면 무한루프에 빠질 수 있음
만약 Circular Dependency 가 발생하면, 아래처럼 해결할 수 있음
- 위 예제에서 "부서장"이라는 관계를 별도의 Entity로 분리하거나 속성을 재정의함
Employee 테이블에서 dept_id는 유지.
Department 테이블의 manager_id 는 없애고, Department_History, Manager_Assignment 같은 Associate Entity를 만들어
"누가 언제부터 언제까지 어느 부서의 장이었는지"를 기록
- 플래그(Flag) 또는 상태값 활용
물리적인 FK 연결 대신, 비즈니스 로직으로 처리.
한쪽의 FK 연결을 끊고 Employee Entity 에 is_manager 같은 컬럼을 추가. 이렇게 논리적인 관계만 유지
Associate Entity 를 추가하여 Circular Relationship 이슈를 해결하는 예제
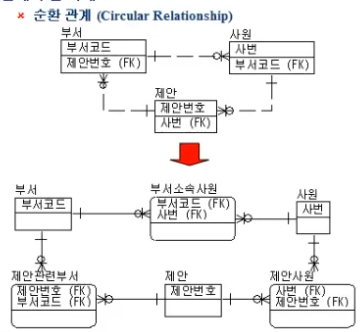

위 구매의뢰 Entity 에서는 여러 자재를 가져올 수 있고(1:N)
자재 Entity 에서는 여러 구매의뢰에 매칭될 수 있음(M:1)
이렇게 발생되는 M:N 관계는 Associate Entity 등으로 반드시 처리해줘야 함
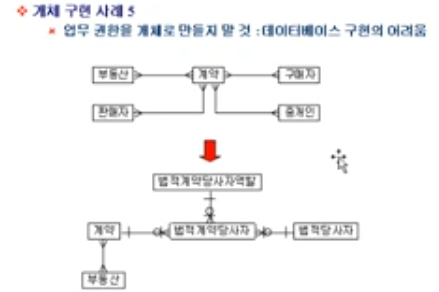
부동산매물 Entity, 판매자 Entity, 구매자 Entity.... 등등
다양한 역할을 모두 Entity 로 만들지 말라는 이야기임
역할이 추가되면? 예를 들어 중개인 Entity 가 추가되거나, 보험Entity 가 추가되면?
계약Entity 에 끝도없이 추가되기 때문에 관리가 복잡해짐
역할을 모두 Entity 로 만들지 말고,
Entity 하나에 몰아넣으라고 말하는 것 같음. 근데 정확하게 이해는 못 함....
추가될 수 있는 부분은 하나의 Entity 로 만들어보자

관계를 맺지 않은 Entity가 없도록 해야 함
모든 Entity 는 다른 Entity 와 관계를 맺어야 함

동의어를 따로따로 Entity 로 만들지 말아야 함
인사관리에서는 사원이라고 부르고
회계관리에서는 직원이라고 부르고
생산관리에서는 작업자라고 부르는데
사실 다 동일한 의미를 갖고 있잖아
그래서 하나의 Entity 를 만들고 공통으로 사용하는 방향이 좋음
특별한 취급이 필요하다면 위에 작업자 Entity 처럼 따로 만들어도 좋음
< Entity 관계 정의 >
두 개 이상의 Entity 간 명명된 의미있는 연결. 관계.
Entity와 Entity 간 연결은 식별자(PK, FK) 기준으로 설정됨
Entity 간 참조 무결성(Referential Integrity)을 유지하게 해 줌
참조 무결성 예) 자식 Entity 는 부모 Entity 가 갖지 않은 값을 가질 수 없음
예를 들어, 부모 Entity(부서)는 다음과 같음
| dept_id(PK) | dept_name |
| 10 | 데이터 엔지니어링부서 |
| 20 | 비즈니스 분석부서 |
자식 Entity(직원) 는 다음과 같음
| emp_id | emp_name | dept_id (FK) |
| 101 | 눈가락 | 10 |
| 102 | 머릿가락 | 10 |
| 103 | 손가락 | 20 |
이 때 부모 Entity 에 없는 값을 이용하여 자식 Entity 에 값을 넣을 수 없음
가령 104, 홍길동, 90 이런 값을 넣을 수 없음 (DB 에서 막음)
Entity 간 관계를 ERD 로 그릴 때 아래와 같은 기호를 사용

| (Mandatory/One): 선 위에 수직선 하나가 있으면 '1' 또는 '반드시 하나'. 숫자로 따졌을 때 하나만 연결됨.
"연결이 하나만 있을 수 있더라"
O (Optional/Zero): 동그라미는 '0'을 뜻하며, 관계가 없을 수도 있음
"연결이 없을 수 있더라"
> (Multiple/Many): 세 갈래로 갈라지는 모양(까마귀 발). '다수(Many)'
"연결이 여럿 있을 수 있더라"
최소 몇 개, 최대 몇 개가 가능한지 등을 보여주기 위해서 이런 notation 을 사용함


왼쪽이 사원 Entity 이고, 5개의 서로 다른 관계로 Entity 와 연결됨
- 1:1 관계 : 사원과 매니저. 사원과 성별
사원 한 명이 두 개 이상의 성별을 가질 수 없음. 그래서 1:1 관계가 됨.
반드시 하나의 instance 와만 매칭됨. 다수 매칭될 수 없음
사원과 이름의 경우, 이름이 바뀌는 경우가 발생할 수 있어서 1:N 관계로 생각될 수 있음
- 1:0, 1:1 관계 : 사원과 병역사항, 사원과 프로필사진 등
남사원은 병역 사항이 존재하고 여사원은 존재하지 않음
프로필사진이 있는 사원도 있고 없는 사원도 있음
- 1:1, 1:N 관계 : 사원과 프로젝트
사원 하나가 최소 하나 이상의 프로젝트에 참여할 수 있지만
프로젝트에 참여하지 않은 사원은 없음(1:0은 아님)
- 1:0, 1:1, 1:N 관계 : 사원과 성과
성과가 없는 사원이 존재할 수 있음
성과가 존재한다면 무조건 하나 이상 존재함
- 1:N 관계 : 사원과 학력
아래 ERD 를 보고 Notation 들을 이해해보자
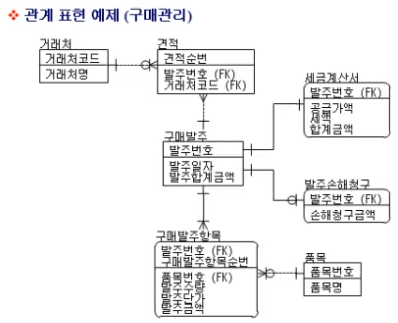

추가로, 신체사항Entity 와 병역사항Entity 는 1:1 관계이기 때문에
사원 Entity 자체에 넣어도 문제는 발생하지 않음
사원 Entity 는 수시로 IO 되고
신체사항, 병역사항은 1년에 두 세번밖에 IO되지 않는데
사원 Entity를 부를 때마다 신체/병역 사항이 계속 불린다면 이건 메모리 낭비가 될 수 밖에 없음
따라서, 자주 접근하지 않는 정보들은 1:1 관계의 Entity 로 만들어서 따로 빼두는 것이 좋음
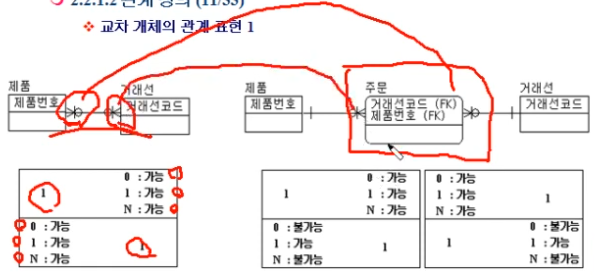

교차 관계를 Associate Entity 표현하는 것이 아주아주아주아주 중요함
양쪽 Entity 의 PK 를 묶은 FK 두 개를 Associate Entity 의 PK로 사용(이것은 Composite Key 라고 함)
그리고 notation 은, 위 이미지의 빨간 선과 같이 뒤집어서 연결해주면 됨
두 개의 FK 중 어느 것을 먼저 두느냐도 성능에 영향을 미침
동일한 두 개의 FK 가 Associate Entity 에 두 번 이상 들어가야 하는 경우가 발생하기도 함
Composite Key 를 PK 로 사용하면 두 번 이상 들어가게 만들 수 없음
이런 경우가 발생하면, 두 Entity 의 FK 중 하나를 Associate Entity 의 attribute 로만 참조하고,
Associate Entity PK 를 FK 하나+Surrogate Key 로 만들 수 있음
이렇게 Associate Entity 에 surrogate key 를 사용하는 경우도 발생함
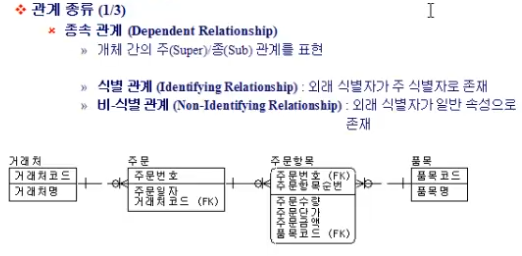
Identifying Relationship : Sub Entitry 가 갖는 FK 가 PK 로 사용됨
예) 주문Entity - 주문항목 Entity
Non-Identifying Relationship : Sub Entitry 가 갖는 FK 를 PK 로 사용되지 않고 attribute 로 사용됨
예) 거래처 Entity - 주문 Entity, 주문항목 Entity - 품목 Entity
FK 를 PK 로 사용할 지 말지 의사소통 할 때 사용하는 용어라고 함
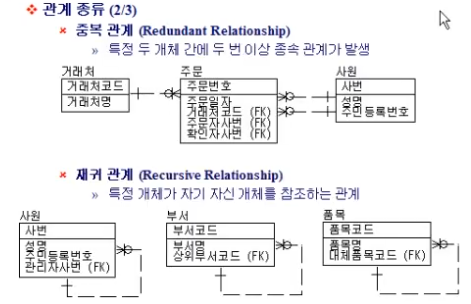
두 Entity 간 연결이 두 번 이상 발생하는 경우도 조재함
자기 자신과 연결되는 경우도 존재함
한 번 재귀는 괜찮지만, 서너번 이상의 재귀는 성능 하락으로 이어짐
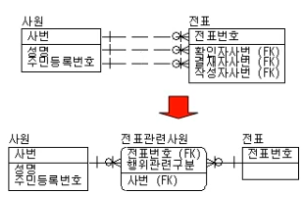
중복 관계는 Associate Entity 를 통해 해결 가능함
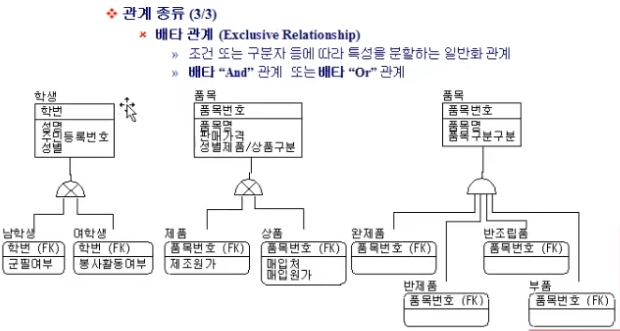
중간에 X 있는 것이 and, 없는 것이 or.
근데 DB 쿼리 작성할 때는 or 되도록 사용하지 말라고 함
and 로 바꿔서 처리하라고....
(물론 누가봐도 성능상 or 사용이 유리할 때는 or를 사용해야지)

< identifiers >
- SuperKey : 유일성을 보장하는 키 묶음. 키가 엄청 길어지는 것은 신경쓰지 않는 슈퍼맨임...
학번은 SuperKey가 됨
주민번호도 SuperKey 가 됨
학번+주민번호 도 SuperKey 가 됨
학번 + 주민번호 + 이름 도 SuperKey 가 됨
유일성만 보장한다면 어떻게 연결하던 SuperKey 가 됨
- CandidateKey : SuperKey 중에서 minimality 를 보장하는 키. CandidateKey 중에서 PK를 선택함
학번은 SuperKey 중에 가장 짧기 때문에 CandidateKey가 됨
주민번호도 가장 짧기 때문에 CandidateKey 가 됨
학번+주민번호는 짧지 않기 때문에 CandidateKey가 될 수 없음
SuperKey, CandidateKey 는 논리적인 개념일 뿐이고 DB 에 직접 쓰이지 않음
- PrimaryKey : CandidateKey 중에서 실제로 DB 에 사용되는 하나의 키
모든 Entity 에서는 PK 가 반드시 존재해야 함
PK 는 null 이 되지 말아야 하며, 모든 instnaces 를 구분할 수 있어야 함
가능한 짧게 만들어야 하며(indexing 성능 때문에) 단순하게 만들어야 함(너무 많은 컬럼 조합하지 말라는 말)
컬럼 하나로 만들거나, 두 개 컬럼 조합해서 만들거나, FK 랑 조합해서 만들거나, surrogatekey 랑 조합해서 만들거나
참고로, PK 는 업데이트가 가능함(!). update table set mypk = 0 where mypk = 1; 이 실제로 동작하는 말임
업데이트 된다고 해서 막 바꿔도 된다는 말은 아니고, PK 한 번 만들고나면 최대한 바꾸지 말아야 함
- AlternateKey : CandidateKey 중에서 PK 가 되지 못한 키.
sort, if, where 등에 자주 사용될 수 있으며, 자주 사용된다면 index 를 추가해서 사용함.
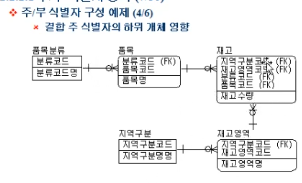

윗부분은 품목분류 Entity 와 품목 Entity 가 상하위 관계를 갖고
품목 Entity 와 재고영역 Entity 사이에 M:N 관계가 발생해서 재고 Associate Entity 를 만듦
근데 재고 Entity 의 PK 가 너무 커져버림
그래서 차라리 상위 Entity 에서부터 PK 를 줄여서,
Associate Entity 의 PK 가 줄어들 수 있도록 조치함
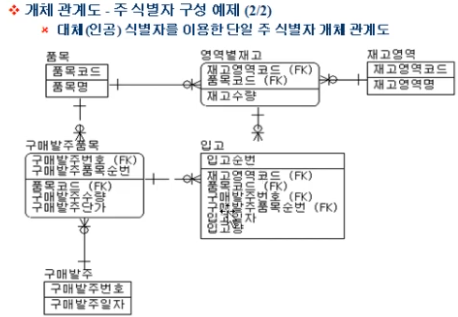
품목 Entity 와 구매발주 Entity 사이의 구매발주품목 Associate Entity 가 생성됨
근데 품목코드 FK 는 attribute 로만 사용되었고,
구매발주번호 FK( + 구매발주품목순번 surrogate key) 는 PK로 사용됨
이건 왜 이렇게 했는가? 구매발주Entity 와 구매발주품목Entity 를 자주 묶어서 쿼리한다는 걸 알고 있어서.
이렇게 Associate Entity 에서는, 자주 사용되는 FK 만 PK 로 올려서 사용하는 센스를 발휘할 수 있음
추가로, 입고 Entity 에서 모든 FK 를 다 attribute 로 내렸음.
모든 FK 를 PK로 사용하면 복잡해지기 때문에
PK 를 surrogate key 로 만들어두고 사용하는 예제임
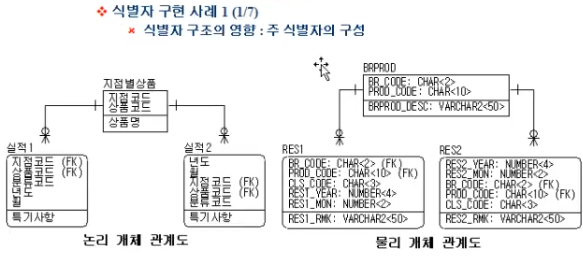
여러 컬럼의 조합으로 PK 를 만들 때, 조합 순서도 퍼포먼스에 영향을 끼침
실적1 Entity 는 지점코드-상품코드-분류... 순서이고
실적2 Entity 는 년도-월-지점코드-상품코드... 순서임


하지만 쿼리의 where 절에 무엇이 들어가냐에 따라 쿼리 성능이 달라짐
where 절에 '코드'가 포함되어있는데, 이 '코드'컬럼이 PK 의 앞쪽에 위치한 실적1Entity 의 성능이 더 좋음
즉, PK 를 구성하는 컬럼 중 앞쪽에 있는 컬럼으로 where 해야 성능이 좋다는 것을 이해하고 있어야 함

위 제품 Entity 보다는
아래 제품 Entity 가 더 나은 설계가 됨
'제품코드' 라는 컬럼은 제품구분,생산공장,순선이 모두 조합된 정보를 갖고 있음
'생산공장별로...' 라는 쿼리를 수행한다면
위 제품 Entity 는 PK 를 substring 으로 잘라서 사용해야하는데 이건 성능이 나오지 않음
아래 제품 Entity 처럼, 제품코드는 그대로 갖고있되
잘라서 써야하는 부분들(제품코드, 생산공장)을 attribute 로 또 만들어서 사용함
그럼 PK 를 substring 하지 않아도 되기 때문에 성능이 나옴
추가로, 제품코드, 생산공장 정보를 갖고 있는 Entity를 따로 만들면 나중에 쿼리할 때 좋음
예를 들어, 제품Entity 가 10만개 정보를 갖고 있고 제품구분Entity 는 10개 정보를 갖고있다고 하자
제품Entity 에서 1인 것을 찾아 full scan 하는 것보다,
제품구분코드 1인 것을 찾을 때, 제품구분 Entity 에서 먼저 1을 찾고 제품 Entity와 join해서 찾는 게 빠르다고 함
(join할 때도 full scan 하지 않나...?
index 가 없는데, 제품 Entity 에서 1을 수집할 때 join 으로 full scan 을 피할 수 있나?)
위와 비슷한 예제를 하나 더 살펴보자

제품 Entity 의 '제품코드'는 여러 컬럼의 조합으로 이루어짐(브랜드,복잡종류,년도,시즌.....)
a 는 쿼리할 때 PK 를 substring 으로 잘라써야하니 성능이 좋지 않고
b 는 PK 가 너무 길고
c 가 적절한 모델링이 될 수 있음
추가로 e 처럼 다른 Entity 를 설정하고 FK 로 연결하면 쿼리 성능이 더 좋아진다는 내용
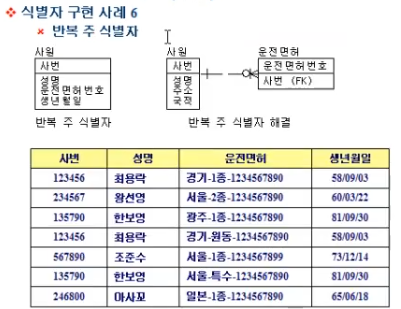
위 사원 Entity 의 경우, 사번 하나 당 운전면허번호가 하나만 들어오게 되어있음
만약 운전면허번호가 2개 이상이라면?
이런 경우, 운전면허번호를 위한 Entity 를 하나 더 만들어서 2개 이상의 정보를 넣을 수 있도록 하자
'눈가락' 카테고리의 다른 글
| [AWS] Complete AWS Certified Data Engineer Associate - DEA-C01 필기 (0) | 2025.11.25 |
|---|---|
| [Git] 내가 보려고 만든 git 명령어들 (0) | 2025.04.08 |
| [AWS] EMR, Athena, Glue, Lake Formation, DMS 필기 (0) | 2024.07.03 |
| [AWS EMR] step 추가하여 shell command 실행하는 방법 (0) | 2024.05.07 |
| Gradle 공부 필기 (0) | 2024.04.01 |