Coding Interview
[IT] Data Engineer 기술 인터뷰 준비를 위한 이론 + English
눈가락
2025. 8. 20. 22:24
0. 인터뷰 질문 및 답변(설명)
1. 영어로 표현해보고 싶은 문장 Korean Sentence for me to want to speak in Eng
2. 영어 번역 (by Gemini) English sentence by Gemini
| 빅데이터란 |
전통적인 데이터베이스 관리 도구로 처리, 저장, 분석하기 어려운 규모·속도·다양성을 가진 데이터 단순히 데이터가 많다고 해서 빅데이터는 아니며, 처리·저장·분석의 어려움이 존재하는 데이터 빅데이터 특징 - Volume(규모) : 데이터 양이 매우 큼 - Velocity(속도) : 데이터가 빠르게 생성되고, 실시간/근실시간 처리가 필요 - Variety(다양성) : 구조적/반구조적/비구조적 데이터가 혼합 - Veracity(신뢰성) : 데이터 품질, 정확성, 일관성 문제 - Value(가치) : 데이터를 활용해 비즈니스 가치를 창출할 수 있어야 함 3V 중 Velocity + Volume 가 핵심임. 즉, 대규모 데이터를 빠르게 처리할 수 있어야 함 |
'규모', '속도', '다양성' 속성을 가진 데이터 Data characterized by its 'volume', 'velocity', and 'variety'. Data that exhibits the properties of volume, velocity, and variety. Data that is big in volume, fast in velocity, and diverse in variety. |
처리, 저장, 분석의 어려움이 존재하는 데이터 Data that poses challengeS for processing, storage, and analysis. Data that is difficult to process, store, and analyze. |
실시간/근실시간 처리가 필요하다. This requires real-time or near real-time processing. |
| data engineering 이란 무엇이고 왜 필요한가 |
데이터 엔지니어링(Data Engineering) 은 조직 내에서 데이터를 수집, 저장, 처리, 변환하여 분석가, 데이터 과학자, 비즈니스 의사결정자들이 활용할 수 있는 형태로 제공하는 일련의 과정 데이터 엔지니어링이 필요한 이유는 다음과 같음 1. 데이터 품질 보장 - 불완전하거나 중복되거나, 다양한 포맷으로 존재하는 원천 데이터를 정제하여 일관된 스키마를 갖는 신뢰성있는 데이터로 변환하여 제공 2. 데이터 접근성 향상 - 적절한 파이프라인을 통해 다양한 소스(DB, 로그, API, 스트리밍 등)의 데이터를 중앙화 - 덕분에 사용자(분석가나 데이터 과학자)가 데이터에 손쉽게 접근하여 쿼리하고 활용 가능 3. 확장성과 효율성 확보 - 데이터는 계속 증가하기 때문에 확장 가능한 저장소(HDFS, Data Lake, Cloud Storage)에 효과적으로 저장 - 분산 처리 시스템(Spark, Flink 등)을 통해 대량 데이터를 효율적으로 처리 4. 비즈니스 가치 창출 지원 - 잘 설계된 데이터 파이프라인을 통해 데이터로부터 인사이트를 얻는데 기여 |
데이터 엔지니어링이란, 데이터를 수집, 저장, 처리, 변환하여 사용자에게 제공하는 과정이다. Data Engineering is the process of ingesting, storing, processing, and transforming data to make it available to users for analysis. |
분석가, 데이터 과학자들은 이러한 데이터를 이용하여 비즈니스 의사결정을 한다. Analysts and data scientists use this data to make business decisions. |
원천 데이터는 불완전하다. Raw source data is often incomplete, unreliable, or inconsistent. 중복되거나, 포맷이 다양할 수 있다. It can have issues like duplicates or diverse formats. 그래서 원천 데이터를 신뢰성있는 데이터로 변환해야 한다. Therefore, this raw data must be transformed into a reliable and trustworthy format. |
사용자들이 데이터에 쉽게 접근할 수 있어야 한다. It is essential that users can easily access the data. The data must be easily accessible to users. |
| data engineer 는 무엇이고 왜 존재해야 하는가 |
데이터 엔지니어(Data Engineer) 는 조직에서 발생하는 방대한 데이터를 안정적으로 수집·저장·처리하여 분석가, 데이터 과학자, 제품 팀, 경영진 등 다른 사람들이 데이터를 활용할 수 있게 만드는 사람 데이터 엔지니어가 존재해야 하는 이유는 다음과 같음 1. 데이터 파이프라인 구축과 자동화 - 로그, 트랜잭션 DB, IoT 센서, 외부 API 등 다양한 소스로부터 데이터를 안정적으로 가져와 정해진 규칙에 따라 변환하고, 분석 및 모델링에 맞는 스토리지에 적재하는 데이터 파이프라인을 설계, 구현, 운영 및 자동화 2. 데이터 품질과 신뢰성 보장 - 데이터는 잘못 수집 될 가능성이 존재함(중복, 누락, 지연 등) - 데이터 엔지니어는 모니터링, 데이터 검증(Validation), 품질 규칙(Data Quality Rules) 등을 통해 정확하고 일관성 있는 데이터를 제공하여 신뢰성을 보장함 3. 확장 가능한 데이터 인프라 관리 - 데이터 엔지니어는 분산 처리 프레임워크(Spark, Flink), 클라우드 스토리지, 데이터 레이크, 데이터 웨어하우스 등을 활용해 대규모 데이터를 확장성 있게 처리·저장하고 성능 및 비용 최적화 진행 4. 데이터 활용을 위한 기반 제공 - 데이터 엔지니어는 “사용자가 데이터를 사용하기 좋게 만들어 전달” 함으로써 다른 역할들이 본질적인 업무(분석, 모델링, 의사결정)에 집중할 수 있게 함 - 데이터 엔지니어는 비즈니스 가치를 창출 과정의 핵심 역할을 수행 - 조직이 데이터 중심적으로 운영되기 위해 꼭 필요한 존재 만약 데이터 엔지니어가 없다면, 데이터 과학자와 분석가는 매번 데이터 정제부터 시작해야 하고, 시스템이 확장되지 못해 결국 조직의 데이터 활용은 병목에 걸리게 될 것 데이터 엔지니어는 이 문제를 해결할 수 있음 |
데이터 엔지니어는 데이터 파이프라인을 설계하고, 구현하고, 운영하고, 또 자동화한다. Data engineers design, build(or alternative to implement), maintain, and automate data pipelines. |
데이터는 잘못 수집 될 가능성이 존재한다. Data can be incorrectly or improperly ingested. 따라서, 데이터 엔지니어는 데이터 품질과 신뢰성을 보장해야 한다. Therefore, data engineers must ensure data quality and reliability. 정확하고 일관성있는 데이터를 제공하여야 한다. Data engineers must ensure data quality and reliability by providing accurate and consistent data. |
데이터 엔지니어는 대규모 데이터를 확장성있게 처리 및 저장하고, 데이터 파이프라인의 성능 및 비용을 최적화한다. Data engineers process and store massive datasetS(or large-scale data) in a scalable and efficient manner, while also optimizing data pipeline performance and cost. while also : 동시에.. |
만약 데이터 엔지니어가 없다면, 사용자들은 매번 데이터 정제를 해야한다. Without data engineers, users would be forced to transform and clean the data themselves every time. |
데이터 플랫폼이 확장되지 못하면 데이터 활용에 병목이 걸리게 된다. A non-scalable data platform will become a bottleneck for data utilization. If the data platform is not scalable, it will create bottlenecks for data utilization. |
| 분산 프로그래밍이란 무엇이고 왜 필요한가 |
분산 프로그래밍(distributed programming)이란, 하나의 컴퓨터에서 처리하기에는 크거나 복잡한 작업을 여러 대의 컴퓨터(노드)에 나누어 실행하고, 그 결과를 조합하여 하나의 완성된 결과를 얻는 프로그래밍 패러다임 여러 물리적 혹은 가상 서버가 네트워크를 통해 협력하여 하나의 시스템처럼 동작하는 방식 이 방식이 필요한 이유는 크게 세 가지로 볼 수 있음 1. 확장성(Scalability) - 분산 프로그래밍을 통해 작업을 여러 서버로 분할하면, 더 많은 서버를 추가하는 것만으로 처리 능력을 확장할 수 있음 2. 성능(Performance & Throughput) - 하나의 연산을 여러 노드에서 병렬적으로 처리하기 때문에 응답 시간이 짧아지고 전체 처리량(throughput)이 커짐 - 실시간 데이터 처리, 머신러닝 모델 학습, 대규모 로그 분석 같이 많은 데이터를 빠르게 처리해야하는 상황에서 중요함 3. 신뢰성과 장애 허용(Fault Tolerance) - 특정 노드가 고장 나더라도 전체 시스템이 멈추지 않고 나머지 노드가 작업을 이어받을 수 있음 |
분산 프로그래밍을 통해, 하나의 컴퓨터에서 처리하기엔 복잡한 작업을 여러 서버에 나누어 실행하고 그 결과를 조합한다. Distributed programming allows us to take a complex task that would be challenging to run on a single machine, divide it, execute the parts across multiple servers, and then combine the results. |
하나의 연산이 여러 노드에서 병렬로 처리되기 때문에, 응답 시간이 짧아지고 전체 처리량이 올라간다. By processing a query across multiple nodes in parallel, we can decrease response time and increase total throughput. |
많은 데이터를 빠르게 처리해야하는 상황에서 분산 프로그래밍을 사용한다. Distributed programming is used in situations that require processing massive datasets quickly. |
특정 노드가 고장나더라도, 전체 시스템이 멈추지 않는다. 나머지 노드가 실패한 작업을 이어서 진행할 수 있다. Even if a node fails(or goes down), the entire system does not stop. The remaining nodes can continue the failed task, providing fault tolerance. |
| 분산 프로그래밍이 직면하는 어려움이 있다면 |
- 네트워크 지연(latency) : 데이터 이동 시간 (네트워크)이 성능에 큰 영향을 주며, 노드간 정합성, 일관성 이슈가 발생할 수 있음 - 클러스터 관리, 장애 처리 로직 실행에 비용이 소모됨 - 분산된 데이터를 어떤식으로든 올바르게 처리하고 연산할 수 있는 방법이 필요함. 따라서 Hadoop, Spark 같은 도구가 필수 - 디버깅 난이도 : 분산된 시스템은 로컬 환경과 달리 원인을 추적하기 어려워 모니터링 도구가 필수 |
클러스터 관리, 장애 처리 로직 실행에 비용이 소모된다. It costs to maintain cluster and run fault handling logic. There is overhead associated with cluster management and executing fault-tolerance logic. |
분산된 데이터를 어떤식으로든 올바르게 처리할 수 있는 방법이 필요하다. 그래서 데이터 처리 플랫폼 사용이 필수적이다. We need a reliable way to correctly process distributed data, which is why using a data processing platform is essential. |
분산 환경에서는 이슈의 원인을 추적하기가 어렵다. It can be challenging to trace the root cause(or track the root cause) of issues in a distributed environment. |
| 분산 환경에서 데이터 consistency (일관성, 정합성)을 보장하는 방법 |
< 일관성 > 데이터 일관성을 보장하는 방법은 설계 철학에 따라 다름 - 강한 일관성(Strong Consistency) : 트랜잭션이 끝나면 모든 노드가 동일한 값을 갖도록 보장(예: 전통적인 RDBMS, ZooKeeper) - 최종적 일관성(Eventual Consistency) : 시간이 지나면 모든 노드가 동일한 값에 수렴 (예: Cassandra, DynamoDB) 어떤 수준의 일관성을 선택할지는 시스템의 요구사항(속도 vs 정확성)에 따라 달라짐 < 강한 일관성 > 정확성을 중시할 때 사용 쓰기 연산을 모든 복제본(replica)에 전송하고 모든 복제본이 ACK(승인 응답)을 보내야만 commit 완료하는 동기식 복제를 사용 쓰기 트랜잭션이 끝날 때까지 해당 데이터에 대한 읽기/쓰기 lock 유지(lock 이 존재하는 동안 클라이언트에게 응답하지 않음) 혹은, 분산 합의 알고리즘(다수 노드가 특정 값에 합의했을 때 만 클라이언트에 응답) < 최종 일관성 > 속도를 중시할 때 사용 모든 복제본이 "언젠가는" 동일한 상태로 수렴하게 되며, 클라이언트는 최신 값이 아닌 약간 오래된 값을 볼 수 있음 쓰기 요청을 먼저 리더 노드에 적용하고, 이후 다른 팔로워 노드들이 비동기적으로 업데이트하는 비동기식 복제를 사용 노드 간 주기적으로 상태를 교환해 결국 전체 클러스터가 같은 데이터로 수렴하는 Gossip Protocol 을 사용하기도 함 동시에 업데이트가 발생하면 최신 타임스탬프가 존재하는 쪽을 응답하여 해결 강한 일관성 구현은 보통 트랜잭션 레벨에서 (락/합의 알고리즘 기반) 강제. 최종 일관성 구현은 보통 스토리지/복제 레벨에서 (비동기, 지연 전파, conflict resolution) 보장. 강한 일관성은 트랜잭션이 끝나야 클라이언트 응답 (느리지만 정확). 최종 일관성은 빠르게 응답하고, 나중에 백그라운드에서 동기화 (빠르지만 중간에는 불일치). 여기서 CAP 이론과 연관된 부분이 나옴 C(consistency) 가 만족되면 강한 일관성이라 사용자가 응답받지 못하는 상황이 생겨서 A(Availability) 가 만족되지 않고, A 가 만족되면 최종 일관성이라 사용자가 오래된 값을 응답받을 수 있어서 C 가 만족되지 않음 |
< 정합성 > 분산 환경에서 데이터가 여러 노드 사이를 오가다 보면 손실, 중복, 변조, 순서 꼬임 등이 생길 수 있음 1. 무결성(Integrity) 보장 - 데이터를 보낼 때 체크섬/해시값(SHA-256, MD5 등)을 함께 전송 - 수신 측에서 데이터와 해시를 다시 계산해 비교 → 전송 중 변조/손상 여부 확인 2. 일관성(Consistency) 보장 - ACK 기반 전송. 송신 측이 데이터를 보낸 후, 수신 측의 확인 응답(ACK)을 받아야 전송 성공으로 간주 - Idempotency (멱등성) 을 보장하도록 만듦. 동일 데이터를 여러 번 전송하더라도, 수신 측에서 중복 반영되지 않도록 처리 예를 들어, 메시지에 고유 ID(UUID, offset 등)를 붙여서 중복 제거 3. 순서(Ordering) 보장 - Sequence Number / Offset. 각 메시지에 순서 번호를 붙여서 수신 측이 순서 번호를 이용하여 정렬하여 사용 예를 들어, Kafka 파티션 offset 4. 재전송 전략 (Retry & Exactly-Once / At-Least-Once / At-Most-Once) - At-least-once: 데이터가 최소 한 번은 도착 (중복 가능). - At-most-once: 데이터가 중복 없이 도착 (손실 가능). - Exactly-once: 중복도, 손실도 없는 전달. (Kafka + Transaction, Spark Structured Streaming 등에서 지원). |
강한 일관성은 트랜잭션이 끝나면 모든 노드가 동일한 값을 갖도록 보장한다. 정확성을 중시할 때 사용한다. Strong consistency guarantees that all nodes will have the same value after a transaction is committed. It is used in systems where data integrity and correctness are prioritized over performance. |
최종적 일관성은 시간이 지나면 모든 노드가 동일한 값에 수렴한다. 정확성보다 응답 시간을 중시할 때 사용한다. Eventual consistency guarantees that all nodes will eventually converge to the same value over a period of time. It is often used in systems where response time and availability are prioritized over data consistency. |
노드 간 주기적으로 상태를 교환해 결국 전체 클러스터가 같은 데이터로 수렴하는 것을 Gossip Protocol 이라고 한다. Gossip Protocol is a decentralized communication protocol where nodes periodically exchange state information, eventually causing all nodes in the cluster to converge to the same data. |
동시에 업데이트가 발생하면, 최신 타임스탬프가 존재하는 쪽을 응답하여 해결한다. When a conflict occurs due to simultaneous updates, it can often be resolved by using the data with the latest timestamp. |
이것들은 CAP 이론과 연관되어 있다. These are associated with CAP theory. These concepts are related to the CAP theorem. C(consistency) 가 만족되면, 사용자에게 응답을 주지 못 하는 상황이 생겨서 A(Availability) 가 만족되지 않는다. If Consistency (C) is prioritized, the system may become unavailable (A) as it waits to ensure all nodes are consistent. A(Availability) 가 만족되면, 사용자가 오래된 값을 응답받을 수 있어서 C(consistency) 가 만족되지 않는다. If Availability (A) is prioritized, the system may provide an outdated or inconsistent state to users (violating C). |
분산 환경에서 네트워크를 통해 데이터가 여러 노드 사이를 오가다 보면 데이터 손실, 중복, 변조(왜곡), 순서 꼬임 등이 생길 수 있다. In a distributed environment, as data is transferred across the network, it can be susceptible to issues such as data loss, duplication, corruption, and out-of-order delivery (out-of-order data). |
데이터를 보낼 때 체크섬/해시값을 함께 전송한다. A sender sends data along with a checksum or hash value. 수신 측에서 데이터와 해시를 다시 계산해 비교하여, 전송 중 발생했을 변조/손상 여부를 확인한다. The receiver re-calculates the hash value and compares it to the one received to verify that the data was not corrupted during transfer. |
송신 측이 데이터를 보낸 후, 수신 측의 확인 응답을 받아야 전송 성공으로 간주한다. A sender considers a transmission successful only after receiving an acknowledgment (ACK) from the receiver. |
멱등성을 보장하도록 만들면, 동일 데이터를 여러 번 전송하더라도, 수신 측에서 중복 반영되지 않는다. By implementing idempotency, duplicate messages can be processed without causing unintended side effects, even if the sender transmits the same data multiple times. |
각 메시지에 순서 번호를 붙여서 수신 측이 순서 번호를 이용하여 정렬하여 사용하도록 한다. Messages can be sent with a sequence number, which allows the receiver to correctly order them and handle out-of-order delivery. |
| 만약 데이터 크기가 작은 상황에서도 분산 프로그래밍을 사용하는 게 옳은가 |
No. 데이터 크기가 작거나 처리 속도가 그리 중요하지 않다면 단일 서버 환경이 더 효율적일 수 있음 - 분산 시스템의 오버헤드 : 클러스터 관리, 스케줄링 오버헤드, 네트워크 통신, 장애 처리 로직 등은 작은 데이터에서는 오히려 성능 저하를 초래 |
분산 환경에서 작은 데이터를 처리하는 것은 오히려 성능 저하를 초래할 수 있다. Processing small data in a distributed environment could cause performance issues. In a distributed environment, processing small data can actually lead to a reduction in performance. Processing small data in a distributed environment can be inefficient and cause a negative impact on performance. Processing many small files in a distributed system can cause significant overhead and lead to performance degradation. |
| 초기 data pipeline 을 구축할 때 고려해야 할 사항들 |
1. 데이터 품질 (Data Quality & Schema Design) - 정합성(Consistency) : 데이터 손실, 중복, 왜곡 등이 발생하지 않아야 함 - 스키마 관리 : 처음 설계할 때 스키마 진화를 고려해야 함. 그렇지 않으면, 이후 컬럼 추가·타입 변경 시 장애가 발생 - 데이터 유효성 검증 : Null 값, 중복 등의 이상치 처리 로직을 설계 단계에서 고려 2. 확장성 (Scalability) - 꾸준히 증가하는 데이터를 처리하기 위해, 처음부터 분산 처리(예: Spark, Kafka, Flink)나 클라우드 기반 아키텍처를 고려 - 워크로드 다양성 : 데이터 파이프라인이 만들어낸 데이터가 하나의 용도로 쓰이지 않고 여러 워크로드(ML, BI, 알람 등)로 사용되는 설계 고려 여기서 말하는 '워크로드'란, '시스템이 처리해야 하는 작업의 종류'. 예를 들어 배치 작업, 스트리밍 작업, BI 분석작업 등 3. 안정성 & 장애 대응 (Reliability & Fault Tolerance) - 재처리 가능성 : 실패했을 때 데이터를 처음부터 다시 처리할 수 있도록 idempotent 설계 해야 함 (at-least-once 등) - fault tolerence : 하나의 노드에서 실패한 처리를 다른 노드에서 처리할 수 있도록 하여, 작업 자체가 실패하지 않도록 함 - 모니터링 & 로깅 : Airflow/Grafana/Prometheus 같은 모니터링 시스템을 구축하여 장애 원인 분석 4. 비용 & 성능 (Cost Efficiency) - 데이터 저장소(S3) 비용, 컴퓨팅 비용(EMR), 네트워크 전송 비용 고려 - 데이터 중복 저장을 최소화, 압축·파티셔닝·파일 포맷(Parquet) 적용 5. 보안 & 거버넌스 (Security & Governance) - 접근 제어(Access Control) : 민감 데이터를 RBAC/ABAC 로 제어 - 데이터 카탈로그 & 계보(Lineage) : 어떤 데이터가 어디서 왔고, 어디에 쓰이는지 추적 가능해야 함 - 규제 준수 : GDPR, 개인정보 보호법 등 규제 대응을 초기부터 고려 데이터 거버넌스란, 데이터의 품질·보안·책임을 관리해서, 믿을 수 있는 데이터를 제공하기 위해 설계된 제도/체계/규칙 예를 들어, 은행에서 (데이터 거버넌스의 일환으로) 아래와 같은 규칙, 제도를 세워둠 - 꼭 필요한 직원만 고객의 비밀번호에 접근할 수 있음 - 거래 로그가 잘못되었을 때 책임지고 고치는 사람은 누구누구팀 - 사용자 계정은 하나 이상 만들 수 없음 - 'account' 라는 용어의 정확한 정의를 세워둠. 팀마다 서로 다른 의미로 사용하지 않도록. RBAC(Role-Based Access Control) : 사용자가 어떤 역할을 갖고 있는지에 따라 접근 권한을 부여하는 방식 예를 들어 데이터 엔지니어는 data warehouse 테이블 업데이트 가능하지만 데이터 분석가는 불가능 단순한 접근 제어에 사용됨. 설계 관리가 수월함 ABAC(Attribute-Based Access Control) : 사용자의 속성, 리소스의 속성, 환경 속성 등 속성을 기준으로 접근 권한을 부여하는 방식 예를 들어 사용자 직급이 data engineer 이고 접속 ip 가 한국이고 평일 낮 시간대 조건에서만 warehouse 에 접근 가능 정교하고 세부적인 접근 제어에 사용됨. 설계 관리가 복잡함 |
데이터 손실, 중복, 왜곡 등이 발생하지 않도록 설계해야 한다. The system should be designed to prevent data loss, duplication, and corruption. We must design the system to prevent issues like data loss, duplication, and corruption. |
데이터 유효성을 검증한다. We must validate data for quality and integrity. Null 값 처리, 중복 처리 등 이상치 처리 로직을 설계 단계에서 고려한다. This includes designing robust logic to handle edge cases like null values, duplicates, and other outlierS during the implementation phase. |
데이터가 하나의 용도로 쓰이지 않고 여러 워크로드로 사용되는 설계 고려한다. Design for reusability, so that data can be used for multiple workloads instead of a single one. 여기서 말하는 '워크로드'란, '시스템이 처리해야 하는 작업의 종류'를 의미한다. In this context, a 'workload' refers to the type of work a system is designed to handle. |
데이터 중복 저장을 최소화하고, 압축 및 파티셔닝이 가능한 파일 포맷을 적용하여 디스크 용량을 효율적으로 사용한다. Optimize disk space usage by reducing data duplication and utilizing file formats that support compression and partitioning. |
민감 데이터 접근을 RBAC/ABAC 로 제어한다. Control access to sensitive data using RBAC (Role-Based Access Control) or ABAC (Attribute-Based Access Control). |
데이터 거버넌스란, 믿을 수 있는 데이터를 제공하기 위해 미리 약속한 규칙이다. Data governance is a set of policies and procedures established to ensure the availability, usability, integrity, and security of a company's data assets. |
예를 들어, 은행에서는 데이터 거버넌스의 일환으로 아래와 같은 규칙을 세울 수 있다. For instance, as part of its data governance, a bank might establish the following policies |
팀마다 서로 다른 의미로 사용하지 않도록 'account' 라는 용어의 정확한 정의를 세워둔다. Establish a precise definition for the term 'account' to ensure every team uses the term consistently. |
사용자가 어떤 속성을 갖고 있는지에 따라 접근 권한을 부여한다. 이것은 RBAC 보다 세분화된 접근 제어 방식이다. ABAC grants access permissions based on a user's attributes, making it a more fine-grained (or granular) access control model than RBAC. |
| 스키마 진화를 지원하는 방법 |
Avro/Hudi/Iceberg 같은 포맷을 사용하여 스키마 진화를 지원 새로 생성된 컬럼을 처리하게 되는 경우, `nullable`로 추가하면 기존 데이터와 호환됨 (기존 row 들은 모두 null 로 채워짐) 이렇게 스키마 진화가 발생했을 때도 기존 방식 그대로 잘 동작하도록 만드는 것을 'backward compatibility 전략'이라고 함 필드/컬럼이 삭제되거나 타입이 변경된 경우 호환성을 깨트릴 수 있으므로, soft delete 처리 등의 관리 전략이 필요함 컬럼의 타입이 변경되는 경우는 어떻게 해야 할까 Iceberg, Hudi 등은 자동 변환 기능을 제공하지만 자동 변환이 불가능한 경우에는 alter table 등으로 타입을 변경해주어야 함 기존 컬럼과 호환이 안 되는 아예 다른 타입으로 바뀌었다면, 새 컬럼을 생성 컬럼의 이름이 바뀌는 경우엔 테이블에서 직접 rename 을 하면 됨 backward compatibility : 하위호환성 forward compatibility : 상위호환성 |
컬럼이 사라지거나, 타입이 변경되거나, 새로 추가되는 것을 스키마 진화라고 부르며, 이런 경우들을 대처해야 한다. The addition, removal, or modification of a column is known as schema evolution, and we must have a strategy to manage these changes. |
컬럼이 새로 추가되는 경우, 컬럼을 nullable 로 만들어 기존 데이터와 호환되도록 한다. When adding a new column, it should be made nullable to ensure backward compatibility with existing data. 기존의 row 들에 null 을 채우는 방식으로 대처할 수 있다. This can be handled by backfilling null values for older records. |
컬럼이 삭제되거나 타입이 변경되면 호환성을 깨뜨릴 수 있다. Removing a column or changing its data type can break compatibility. |
| 장애 대응을 위한 '재처리 기능' 구현 방법 |
Kafka 같은 메시지 큐를 사용하여 offset 기반 재처리 (offset 에서 다시 읽고 처리) Spark/Flink에서는 체크포인트(Checkpoint)를 활용 DB에서 `UPSERT` (update + insert) 를 활용 새로운 데이터를 가져왔을 때 이미 동일 데이터가 존재하면 update, 존재하지 않으면 insert 를 실행하여 중복없이 재처리 하게 됨 (재처리로 생성된 새데이터를 DB 에 적용할 때 upsert 로 처리하면, 기존 데이터 유무에 따라 중복 없이 처리된다는 뜻) 그리고 Hudi/Iceberg의 merge-on-read 방식을 사용해서 upsert 의 효율을 높임 Merge-on-Read (MOR) : 새로운 트랜잭션이 delta 로그 파일(작은 파일) 에 기록됨 데이터를 읽을 때 "기존 데이터 파일 + delta 로그"를 합쳐서(merge) 읽음 Copy-on-Write (COW) : 새로운 데이터(트랜잭션)가 들어오면, 기존 파일을 통째로 다시 씀 delta 가 없기 때문에 읽기가 빠르고 단순하지만, 업데이트가 많을수록 비용이 커짐 |
재처리로 생성된 새데이터를 DB 에 upsert 로 처리하면, 중복 없이 처리된다. Using an upsert operation, we can process new data from a re-processed batch without creating duplicate records. |
새로운 트랜잭션이 delta 로그 파일에 기록된다. New transactions are recorded in the delta log. 사용자는 기존 데이터 파일과 delta 로그를 합친 결과를 읽는다. Users read the merged result of the existing data files and the delta log. |
새로운 트랜잭션이 들어오면, 기존에 존재하는 해당 파일을 통째로 다시 쓴다. New transactions replace the corresponding files. With each new transaction, the corresponding data file is completely replaced. delta 가 없기 때문에 읽기가 빠르고 단순하지만, 업데이트가 많을수록 비용이 커진다. It's fast and simple to read without delta files but the more updates there are, the higher the cost becomes. Reading is fast and simple without a transaction log, but the cost of frequent updates and modifications can be very high. |
| Hudi/Iceberg의 merge-on-read/upsert가 재처리에 유리한 이유 |
upsert 는 기존 row를 덮어쓰면서 새로운 row를 합치는 기능 따라서 중복 없이 깨진 데이터를 부분 재처리 가능 merge on read 는 delta file 을 이용하여 '업데이트' 된 부분만 따로 쓸 수 있음 전체 데이터를 rewrite하지 않아도 되는 구조를 갖기 때문에 부분 재처리에 효율적임 즉, 깨진 데이터만 보완할 수 있음 예) 2025-08-27 batch에서 1000 개의 row가 누락 → 원천 데이터로 upsert 실행 → 기존 데이터와 합쳐 정확한 상태 복원 MOR 을 구체적인 예시로 이해해봄 기존 데이터 (base file) [ user_id=1, value=100 ] [ user_id=2, value=200 ] 새로운 데이터 (upsert) [ user_id=1, value=110 ] <- update [ user_id=3, value=300 ] <- insert Merge-on-Read 저장 방식 base file: [ user_id=1, value=100 ], [ user_id=2, value=200 ] log file: [ user_id=1, value=110 ], [ user_id=3, value=300 ] 쿼리 시 merge → 최종 결과 [ user_id=1, value=110 ] [ user_id=2, value=200 ] [ user_id=3, value=300 ] 만약 Merge on read 가 아닌 다른 저장 모드, 이를테면 Copy on write 를 사용하게 된다면 특정 row 하나만 잘못되어도, 그 partition 전체 파일을 다시 쓰게 됨 데이터 양에 비례하여 비용과 시간이 크게 증가하고, 그에 따라 대용량 배치/스트리밍 환경에서 재처리 지연 발생, 추가로 중복 쓰기 및 lock 충돌 가능성이 커짐 예를 들어 Partition: 1,000,000 row 잘못된 row: user_id=1234, 1 row MoR: - delta file에 1 row upsert - 쿼리 시 base + delta merge → 정합성 유지 - 전체 1,000,000 row rewrite 불필요 Copy-on-Write: - partition 전체 1,000,000 row rewrite - 하나의 row 수정 위해 전체 재처리 - 비용 & 시간이 매우 높음 |
upsert 를 이용하면, 중복 없이 깨진 데이터만 재처리 가능하다. An upsert operation allows us to efficiently reprocess only the incorrect or corrupted records, preventing the creation of duplicates. |
MOR 은 전체 데이터를 rewrite하지 않고, 깨진 데이터만 보완할 수 있어 효율적이다. The Merge-on-Read (MOR) approach is highly efficient for handling updates to invalid records because it avoids rewriting the entire dataset. |
데이터 양에 비례하여 비용과 시간이 크게 증가하고, 그에 따라 대용량 데이터 처리 환경에서 재처리 지연이 발생한다. The cost and time required for re-processing(여기까지 주어) scale with the volume of data, which can lead to significant retry latency in a big data environment. scale with ~ : ~에 비례하여 변화한다. The cost and time are proportional to the volume of data. : 비용과 시간은 데이터 양에 비례한다. The cost and time increase in proportion to the volume of data. : 비용과 시간은 데이터 양에 비례하여 증가한다. The cost and time go up with the volume of data. : 비용과 시간은 데이터 양에 따라 올라간다. The cost and time are a function of the volume of data. : 비용과 시간은 데이터 양에 따라 결정된다. |
중복 쓰기 및 lock 충돌 가능성도 커진다. This approach also grows the risk of write duplication and lock conflicts. |
| data pipeline 에서 정합성이 깨졌을 때 복구하는 방법 |
데이터 정합성이 깨졌다는 것은, - 원천 데이터와 파이프라인을 통과한 후의 데이터가 불일치 - 일부 데이터 누락/중복 깨진 정합성을 복구하기 위해 1. 재처리(Reprocessing) - 동일한 원천 데이터를 다시 파이프라인에 투입하여 재연산 - 배치 파이프라인의 경우, 특정 날짜의 배치 데이터를 다시 실행 (Airflow DAG에서 2025-08-27 데이터 배치를 다시 trigger) - 데이터 레이크 환경의 경우, Hudi/Iceberg의 merge-on-read 또는 upsert를 활용해 기존 데이터를 덮어쓰기 2. 롤백(Rollback) - 문제가 발생하기 전의 안정적인 상태로 데이터/파이프라인을 되돌리는 방법 - Hive 테이블 스냅샷을 이용하여 이전 버전으로 복원 (Kafka Offset rollback: 잘못 처리된 메시지를 다시 읽도록 설정) - 이미 처리된 downstream 데이터 (전체 데이터) 까지 영향을 주므로 주의 필요 3. 증분 수정(Incremental Correction) - 깨진 데이터만 식별하여 부분적으로 수정하는 방법 - 오류가 발생한 row 을 식별한 후 UPDATE/UPSERT 적용 - 전체 데이터를 재처리하지 않아 리소스 효율이 좋지만, 깨진 데이터를 정확히 식별하는 로직이 필요함 4. 정합성 깨짐 예방 (위 '분산 환경에서 정합성 보장 방법' 참고) - 정합성 깨짐을 미리 방지하는 설계 적용 - 체크섬, row count 비교, schema validation 등 (Airflow에서 pipeline 끝마다 data quality check task 추가 등) - Hudi/Iceberg 등의 ACID 지원 저장소 사용 (ACID 를 통해 DB 시스템 레벨에서 데이터 트랜잭션을 보호함) 재처리 : 오류 원인이 데이터 자체일 때, 특정 시점 배치를 재연산해야 하는 경우 롤백 : 시스템 버그나 잘못된 파이프라인 로직으로 전체 데이터가 오염된 경우 |
데이터 정합성이 깨졌다는 것은, 원천 데이터와 파이프라인을 통과한 후의 데이터가 불일치한다는 것과, 일부 데이터의 누락/중복을 의미한다. A break in data consistency means that the data at the end of the pipeline does not match the source data, often due to issues like data loss, corruption, or duplication. |
배치 파이프라인의 경우, 특정 날짜의 배치 데이터를 다시 실행하여 재연산한다. In batch pipeline, we can re-process batch data on a specific date. In a batch pipeline, it's common to re-process the data for a specific date if an issue is found. |
스냅샷을 이용하여, 문제가 발생하기 전의 안정적인 상태로 데이터를 되돌리는 방법을 롤백이라고 한다. A rollback is the process of restoring data to a previous, stable state using snapshots, typically after a data corruption event. |
부분적인 수정을 위해, 깨진 데이터를 정확히 식별하는 로직이 필요하다. To perform partial updates, we need logic to precisely identify the invalid records. |
Airflow dag 끝마다 data quality check task 를 추가한다. It is a best practice to add data quality check tasks to the end of Airflow DAGs. |
ACID 를 통해 DB 시스템 레벨에서 데이터 트랜잭션을 보호할 수 있다. ACID properties ensure the integrity of data transactions at the database system level. |
| 스토리지 시스템에서 ACID 가 중요한 이유 |
데이터베이스 트랜잭션의 신뢰성과 안정성, 무결성을 보장하기 위해 ACID가 필요함 ACID 를 통해 데이터 무결성을 유지하고, 장애 발생 시에도 데이터 손실이나 불일치를 방지하며, 여러 사용자가 동시에 접근하더라도 정확한 결과를 얻도록 보장 - 데이터 손실 방지 (Atomicity) 네트워크 문제나 시스템 오류 발생 시, 트랜잭션이 부분적으로만 실행되고 중단되는 상황을 방지하여 모든 데이터를 안전하게 보존 - 데이터 무결성 유지 (Atomicity, Consistency) 데이터베이스에 비정상적인 상태가 발생하지 않도록 모든 트랜잭션이 '모두 성공하거나 모두 실패'하도록 보장하여 데이터의 정확성과 일관성을 유지 - 정확한 동시성 제어 (Isolation) 여러 사용자가 동시에 데이터를 조작할 때, 각 트랜잭션은 다른 트랜잭션의 작업에 영향을 받지 않고 독립적으로 실행 이를 통해 데이터의 충돌을 방지하고 올바른 결과를 도출 - 예측 가능한 시스템 작동 (Durability) 장애나 오류가 발생해도 데이터베이스는 이전의 안정적인 상태로 복구되거나 정상적인 상태를 유지 - 개발 편의성 데이터베이스 자체에서 ACID 속성을 보장하기 때문에, 개발자는 복잡한 데이터 정합성 관리를 신경 쓰지 않고 개발에 집중 |
데이터베이스 트랜잭션의 신뢰성과 안정성, 무결성을 보장하기 위해 ACID가 필요하다. ACID is a set of properties that ensures the reliability, integrity, and consistency of database transactions. |
ACID 는 트랜잭션이 부분적으로만 실행되고 중단되는 상황을 방지하여 모든 데이터를 안전하게 보호한다. ACID properties prevent transactions from being partially executed or interrupted, which ensures the safety and integrity of the entire dataset. |
여러 사용자가 동시에 실행한 각 트랜잭션들은 서로의 작업에 영향을 받지 않고 독립적으로 실행된다. Transactions from multiple users run in isolation (or independently) without impacting one another (or each other) 이로써 데이터 충돌이 방지되고 올바른 결과를 도출할 수 있게 된다. This prevents data conflicts and ensures that all transactions produce valid results. |
개발자는 복잡한 데이터 정합성 관리를 신경 쓰지 않고 개발에 집중할 수 있다. ACID properties allow developers to focus on application logic without having to worry about complex data integrity and consistency management. |
| data engineering 에서 중요한 다섯가지 |
- 데이터 신뢰성 reliability : 데이터 및 분석 결과가 정확하고 믿을 수 있음 - 복구 능력 recoverability / resilience : 데이터, 시스템 등에 이슈 발생시, 빠르게 복구 (fault tolerance) - 확장성 scalability : 데이터량이 10배 늘어나도 감당할 수 있는 아키텍처를 설계, 구축, 운영 - 유지보수성 maintainability : 코드/파이프라인을 복잡하지 않도록 설계하고 시스템을 자동화, 로깅/모니터링을 통해 상황 파악 용이 - 재현 가능성 reproducibility : 재현하여 결과 검증. 일관적인 재현은 신뢰성도 높임 |
데이터량이 10배 늘어나도 감당할 수 있는 아키텍처를 설계, 구축, 운영해야 한다. We must design, build, and operate an architecture that can scale to handle a 10x increase in data volume. scale to handle : 처리할 수 있도록 확장하다. |
현상을 재현하고 비교함으로써 결과를 검증한다. We can validate (or verify) our results by reproducing the issue and comparing the outcomes. |
| 클러스터 scale out 할 때 고려해야 할 사항들 |
1. 네트워크 - scale out 으로 인해 노드가 많아지면 노드 간 shuffle (데이터 교환) 비용 증가 - 네트워크 대역폭/지연이 성능 병목이 될 수 있음 - 고속 네트워크 사용, 추가 노드의 물리적인 위치 고려 2. 리소스 관리 - 노드 수가 많아질수록 스케줄러(YARN)의 자원 관리 부하가 늘어남 - YARN resource manager 에 자원 추가 3. 스토리지 아키텍처 - HDFS 의 경우 새로 추가된 노드로 데이터를 리밸런싱하여 데이터를 고르게 분배함 이 때 throttle (초당 최대 50mb 까지만 데이터 리밸런싱) 설정도 고려 (background 에서 천천히 리밸런싱) - Hive 의 경우 partition 값 재설정이나, salting 을 추가하는 방식을 고려 - 분배 과정은 네트워크와 IO 를 많이 사용하므로 운영 외 시간에 진행 참고 : https://eyeballs.tistory.com/280 4. 장애 허용성 (Fault Tolerance) - 노드 수가 많아질수록 장애 확률이 높아짐 - 장애 발생 시 빠르게 복구할 수 있는 구조 재검토 고려. 'replication factor 수' 등 5. 비용 - 클러스터 노드 늘리면 비용도 증가 - Scale-out vs Scale-up 비교하여 선택, Autoscaling 활용 |
백그라운드에서 초당 최대 50mb 까지만 데이터 리밸런싱하도록 throttle 을 설정한다. Configure a throttle on data rebalancing to limit it to a maximum of 50 MB/s in the background. |
| Scale-out 후 데이터 리밸런싱을 하지 않으면 발생하는 문제 |
새로 추가된 노드에는 데이터가 거의 없기 때문에, 해당 노드에 task 가 할당되면 데이터 로컬리티가 깨지게 됨 그로 인해 네트워크로 인한 오버헤드가 발생 When tasks are assigned to newly added nodes, data locality is lost because those nodes don't yet contain any data. Consequently, significant network overhead occurs as data must be transferred to them. |
| Scale-out 시 성능이 항상 선형으로 증가하지 않는 이유 |
네트워크 병목(shuffle 비용 증가), 작업 스케줄링 오버헤드, 데이터 로컬리티 손실 등의 단점이 존재하기 때문 This is due to several disadvantages, including increased network overhead from shuffling, higher task scheduling overhead, and a loss of data locality. |
| scale-up 과 scale-out 을 선택하는 기준 |
워크로드 특성, 비용 구조, 운영 복잡성을 종합적으로 고려하여 선택함 1. 워크로드 특성 - Scale-up 적합 : 단일 노드에서 높은 메모리/CPU 성능이 필요한 경우. 예) OLTP DB, 대규모 in-memory 연산 - Scale-out 적합 : 작업을 여러 노드로 분산 가능할 때. 예) 빅데이터 ETL, 로그 처리, 웹 서비스 2. 비용 - Scale-up : 하드웨어 단가가 급격히 증가(“성능 대비 비용 비효율”) → 고성능 서버는 몇 배 비싸도 성능은 선형적으로 늘지 않음 - Scale-out : 저렴한 서버를 여러 대 쓰므로 장기적으로 경제적 3. 운영 복잡성 - Scale-up : 관리가 단순하지만, 단일 장애점(SPOF) 위험이 큼 - Scale-out : 장애 분산이 가능하지만, 클러스터 운영관리/데이터 분산 전략 필요해서 더 복잡한 관리가 필요 더 높은 안정성을 위해 Scale-out 선택 가능 4. 확장성 측면에서, scale up 보다 scale out 의 한계가 더 넓음 Scale-up은 단순성/즉각 성능, Scale-out은 확장성/가용성이라는 특징이 있음 “현재 병목 지점이 어디인지”에 따라 선택이 달라질 수 있음 |
“현재 병목 지점이 어디인지”에 따라 선택이 달라질 수 있다. Decision could be changed depending on where the bottleneck is. The optimal approach depends on where the current bottleneck lies. |
| data pipeline 종단 간 테스트, 품질 테스트를 구축, 구현하는 방법 |
테스트 목적 정의 - 신뢰성(reliability) 과 재현 가능성(reproducibility) 보장 - 데이터 파이프라인이 입력 → 변환 → 출력 전 과정에서 예상대로 동작하는지 검증 - 오류 발생 시 빠르게 원인 파악 및 복구 가능하도록 지원 테스트 유형 및 구현 방법 1. 단위(Unit) 테스트 - 각 ETL/ELT 변환 함수나 Spark/Hive 작업 단위로 테스트 - 예시 : Spark DataFrame 변환 함수가 올바르게 컬럼을 계산하는지 검증 - 도구 : pytest, unittest, Spark 자체 테스트 API 2. 통합(Integration) 테스트 - 파이프라인에서 여러 컴포넌트(Hadoop, Hive, Kafka, Airflow 등)가 연동되는지 검증 - 예시 : Kafka → Spark Streaming → Hive 테이블 적재까지 데이터 흐름 확인 - 도구 : pytest + Docker Compose 등으로 미니 클러스터 환경 구성 3. 종단(End-to-End) 테스트 - 실제 운영 환경과 유사한 데이터와 조건으로 전체 파이프라인 동작 검증 - 원본 데이터 적재, ETL/Streaming 처리, 출력하여 데이터 스키마 및 값이 의도한대로 나타났는지 검증 - 자동화 : Airflow DAG 내 테스트 태스크, CI/CD 파이프라인 연동하여 자동화하고 실패시 알람 4. 품질(Data Quality) 테스트 - 데이터 정확성, 완전성, 유일성, 일관성 체크 - Constraint 기반 검증 : null 여부, 고유키, foreign key - Rule 기반 검증 : 값 범위, 타입, 포맷 - 예시 도구 : Great Expectations, Deequ, dbt tests 5. 모니터링 및 Alert - 테스트 결과를 운영 환경에서도 지속 확인 - 실패 시 자동 알림, 재처리 가능하도록 설정 단위/통합/종단 테스트를 모두 구축하는 것이 좋음 단위 테스트로 로직 오류를 잡고, 통합 테스트로 시스템 간 인터페이스를 검증하고, 종단 테스트로 실제 운영과 유사한 환경에서 최종 검증을 진행 각 단계가 서로 다른 목적과 범위를 가지고 있으므로 상호보완적임 |
파이프라인에서 여러 컴포넌트가 연동되는지 검증한다. Validate that multiple components in the pipeline are properly integrated. |
데이터 스키마 및 값이 의도한대로 나타났는지 검증한다. Validate that the data schema and values are as intended. |
단위 테스트로 로직 오류를 잡고, 통합 테스트로 시스템 간 인터페이스를 검증하고, 종단 테스트로 실제 운영과 유사한 환경에서 최종 검증을 진행한다. Unit tests are used to verify logic, integration tests are used to validate the interface between systems, and end-to-end tests are used for final validation in an environment that simulates production. |
각 테스트들은 서로 다른 목적과 범위를 가지고 있으므로 상호보완적이다. Each type of test has a different purpose and scope, making them complementary to one another. |
| datalake 와 datawarehouse 의 용도 차이 |
< 데이터 레이크 (Data Lake) > 1. 정의 : 다양한 형태의 원천 데이터를 원본 그대로 저장하는 중앙 저장소 2. 데이터 특성 - 구조화(SQL), 반구조화(JSON, XML), 비구조화(logs, 이미지). 모든 형태의 데이터가 저장될 수 있음 - 스키마 온 리드(Schema on Read) : 데이터를 저장할 때 스키마를 정의하지 않고, 데이터를 읽어서 사용할 때 필요에 따라 스키마 정의 3. 용도 - Raw 데이터 장기 보관 - 실험적 분석, ML/AI 모델 학습을 위한 feature 추출 (원시 데이터를 탐색하고 실험적인 분석을 수행하는 DS, BA 등의 사용자들이 활용) feature 추출 후 정제된 DW 데이터를 학습에 사용하는 경우도 있고, 비정형 데이터의 경우 Data Lake 에서 곧바로 가져가서 학습하는 경우도 있음 4. 장점 : 유연성, 비용 효율적, 모든 데이터 유형 수용 5. 단점 : 구조화된 분석/쿼리 성능은 상대적으로 낮음, 거버넌스를 통한 데이터 품질 및 접근 관리 필요 6. 기술 스택 : HDFS, S3 등 < 데이터 웨어하우스 (Data Warehouse) > 1. 정의 : 구조화된 데이터를 분석 목적에 맞게 변환(ETL/ELT) 후 저장 2. 데이터 특성 - 주로 테이블/컬럼 구조, 정제된 데이터 (비즈니스 분석에 최적화 된 형태) - 스키마 온 라이트(Schema on Write) : 데이터를 저장하기 전에 엄격한 스키마(테이블 구조)를 정의하고, 데이터를 해당 스키마에 맞게 변환하여 저장 3. 용도 - 비즈니스 인텔리전스(BI) 보고서(비즈니스 의사 결정을 위함), 대시보드 - 분석을 위한 OLAP 쿼리 4. 장점 : 쿼리 성능 우수, BI 활용 최적화 5. 단점 : 데이터 타입/스키마 제한, 유연성 낮음 6. 기술 스택 : Redshift, BigQuery, Snowflake, Teradata와 같은 MPP(Massively Parallel Processing) 데이터베이스 보통 수집한 Raw 데이터를 Data Lake에 저장하고, ETL/ELT로 정제 후 결과를 Data Warehouse에 적재하는 방향으로 사용됨 데이터 레이크는 원시 데이터의 저장 및 실험적 분석을 위한 공간으로 데이터 웨어하우스는 비즈니스 분석 및 보고를 위한 최종적인 데이터 소스로 활용됨 계층적 데이터 아키텍처 : Data Lake → Data Warehouse → BI/ML |
Data lake 는 Raw 데이터를 장기 보관하고, ML/AI 모델 학습을 위한 feature 추출하는 용도로 사용된다. A data lake is used for long-term storage of raw data and for feature extraction to support ML/AI model training. |
Data lake 는 다양한 형태의 데이터를 수용할 수 있어서 유연하다. Data lake is flexible because it can store data with many different formats. A data lake is highly flexible as it can accommodate data of various formats. |
Data lake 는 분석이나 쿼리 성능은 상대적으로 낮고, 거버넌스를 통한 데이터 품질 관리가 필요하다. A data lake is not optimized for high-performance analytics or queries and requires a strong data governance framework to ensure data quality. |
Data warehouse 는 테이블 구조를 갖으며, 데이터 저장시 스키마를 엄격하게 정의한다. A data warehouse has a structured, tabular format and enforces a strict schema for all data upon ingestion. |
Data warehouse 는 분석을 위한 OLAP 쿼리를 실행하거나 대시보드, 보고서를 작성하기 위해 사용된다. Data warehouse is used to execute OLAP query for analysis and generate dashboards or reports. A data warehouse is used for high-performance OLAP queries, and for building dashboards and reports. |
주로 수집한 Raw 데이터를 Data Lake에 저장하고, ETL/ELT로 정제 후 결과를 Data Warehouse에 적재하는 방향으로 사용된다. Typically, raw data is first ingested into a data lake, then transformed via ETL/ELT, and finally loaded into a data warehouse. |
| 데이터 레이크와 데이터 웨어하우스를 설계할 때 고려해야 할 점 |
1. 데이터 레이크 - 확장성(Scalability) : 페타바이트급 이상의 대용량 데이터를 효율적으로 저장하고 관리할 수 있어야 함 (HDFS, S3) - 다양한 데이터 형태 지원 : 정형, 비정형, 반정형 데이터를 모두 수용할 수 있는 유연한 스키마리스(schema-less) 설계 - 데이터 거버넌스 : 데이터가 원시 상태로 저장되므로, 메타데이터 관리, 접근 제어, 데이터 품질 관리를 위한 명확한 거버넌스 정책이 필요 2. 데이터 웨어하우스 - 분석 용이성 : 비즈니스 분석가들이 SQL을 통해 손쉽게 데이터를 탐색하고 분석할 수 있도록, 스타 스키마(Star Schema)나 스노플레이크 스키마(Snowflake Schema)와 같은 분석에 최적화된 구조로 데이터를 모델링 - 성능(Performance) : 대용량 데이터에 대한 쿼리 성능을 보장하기 위해, 컬럼 기반(Columnar) 스토리지, 인덱싱, 파티셔닝 등의 최적화 기법을 적용 - 비용 효율성 : 분석 용도에 맞게 데이터를 최적화하여 불필요한 비용이 발생하지 않도록 관리 |
페타바이트급 이상의 대용량 데이터를 효율적으로 저장하고 관리한다. It efficiently stores and manages large-scale data at the petabyte scale and beyond. |
명확한 거버넌스 정책이 필요하다. It requires a clear and robust data governance policy. |
| 데이터 레이크하우스(Data Lakehouse) 란 |
데이터 레이크하우스는 데이터 레이크와 데이터 웨어하우스의 장점을 결합한 새로운 아키텍처 데이터 레이크의 장점 : 저렴한 비용으로 다양한 형태의 데이터를 저장하고, 데이터 과학 및 머신러닝 워크로드를 지원 데이터 웨어하우스의 장점 : SQL 기반의 고성능 쿼리를 제공 데이터 레이크하우스는 데이터 레이크 위에 데이터 웨어하우스의 기능을 추가하여, 별도의 ETL/ELT 과정 없이 데이터 레이크하우스의 데이터를 바로 SQL로 분석할 수 있음 (이게 핵심) Apache Hudi, Apache Iceberg와 같은 table format 기술들이 ACID를 제대로 보장해주면서 Data Lake를 DW처럼 쓸 수 있도록 구현 가능 Data Lakehouse에는 데이터 중복, 누락, 정제 부족, 스키마 변경 같은 데이터 이상 문제가 있음 품질 문제는 Hudi, Iceberg 등(의 ACID 제공)으로 조금은 해소됨 그럼에도 정제 부족 문제는 남아있기 때문에, 별도의 정제 과정이 필요함 전회사에서는 Data Lake 와 Data Lakehouse 를 따로 두었음 Raw Data 를 Data Lake 에 적재하고, 별도의 정제 과정을 거친 데이터를 Data Lakehouse 에 넣음 Data Lakehouse 는 s3 와 hudi 를 이용하여 구현되었고, Athena 를 통해 쿼리가 실행됨 |
그럼에도 불구하고 Data Lakehouse 에는 정제 부족 문제는 남아있기 때문에, 별도의 정제 과정이 필요하다. Despite its advantages, a Data Lakehouse still requires a separate transformation phase to address potential data quality or cleanliness issues. address : (문제·상황 등에 대해) 고심하다[다루다] |
Hudi, Iceberg 가 ACID 를 제공하기 때문에 품질 문제는 조금은 해소된다. Quality issues are somewhat mitigated because Hudi and Iceberg provide ACID compliance. |
| 기존 회사에서 사용하던 것은 왜 warehouse 가 아니고 lakehouse 인가? |
왜 웨어하우스가 아닌가? 전통적인 데이터 웨어하우스(DW)라면: • 데이터는 대부분 정형(Structured) 으로 적재됨 (RDB 형태) • 스키마는 엄격하게 사전에 정의됨 (Schema-on-Write) • 데이터 저장소는 보통 전용 DB 엔진 (예: Redshift, Snowflake, BigQuery 내부 스토리지) • 저장과 쿼리가 tightly coupled (저장소=쿼리엔진) 전 회사에서 사용했던 ODS 테이블의 구조는 전용 DB 스토리지가 아니라 S3 같은 Object Storage를 기반으로 하고, 스키마도 고정이 아니라 Hudi의 schema evolution을 통해 유연하게 다루고 있음 따라서 DW 전형과는 다름 왜 레이크하우스인가? 1. 저장소: • Raw data도 S3에 저장 (데이터 레이크 역할) • Hudi 테이블도 S3에 저장 (트랜잭션 + 메타데이터 관리 추가. 쿼리 엔진과 연결된 전용 저장소가 아님) 2. 테이블 포맷 (Hudi): • ACID 지원 (upsert, merge) • Schema evolution 지원 (새 컬럼 자동 반영, null 패딩) • 증분 읽기 가능 3. 메타스토어: • AWS Glue Catalog 사용 (Spark/Hive/Athena/Presto 같은 쿼리 엔진에서 공통 활용 가능) 4. 분석 및 접근: • Athena 같은 SQL 엔진으로 직접 쿼리 가능 • 데이터 분석가가 그대로 접근 가능 (DW와 유사한 사용 경험 제공) • 동시에 raw data도 SQL on S3(Athena schema-on-read) 방식으로 접근 가능 즉, Lake의 유연성 + Warehouse의 관리/쿼리 기능이 결합된 구조 = Lakehouse. 정리 • 웨어하우스: 전용 DB, 강한 스키마 제약, 비정형데이터 다루기 어려움 • 레이크: 모든 데이터를 Raw로 던져놓는 저장소, SQL 분석에는 추가 작업 필요 • 레이크하우스 (전 회사에서 사용했던 구조): • S3 기반 레이크 위에 Hudi 테이블 (Lakehouse format) 구축 • Glue Metastore + Athena로 분석 가능 • Schema evolution 및 raw data 병행 사용 가능 |
| Data Lakehouse 에서 사용되는 Hudi와 Iceberg 가 ACID 를 제공할 수 있는 이유 |
HDFS, S3 같은 오브젝트 스토리지는 Append-Only + Eventually Consistent 구조임 동시에 여러 writer 가 작업하면 데이터 깨짐 발생 가능함 UPDATE, DELETE, MERGE 같은 명령(트랜잭션)을 안전하게 지원하지 못함 결과적으로 ACID(원자성, 일관성, 고립성, 지속성) 보장 불가능 스토리지 레벨에서 ACID 를 지원하려면 Hudi/Iceberg 를 사용해야 함 이 둘은 모두 메타데이터 레이어와 스냅샷 관리를 통해 ACID를 지원할 수 있음 1. 원자성(Atomicity) Commit 단위의 메타데이터(Manifest, Timeline, Snapshot)를 관리 쓰기 작업은 Commit Log(Write-Ahead Log)를 통해 기록 쓰기 실패 시 WAL undo 를 통해 복구 ("부분 업데이트" 방지 = Atomicity) (2) 일관성(Consistency) 테이블 스키마, 파티션, 파일 경로 등을 메타데이터 레이어에서 관리 모든 reader/writer 는 동일한 메타데이터(최신 commit snapshot)를 기반으로 동작 이로 인해 모든 reader 는 동일한 데이터를 보게 되므로 일관성이 유지됨 (3) 격리성(Isolation) MVCC (Multi-Version Concurrency Control) 기법 사용 Reader 는 특정 시점(snapshot)의 데이터만 읽음 Writer 가 새로운 commit 을 진행해도 Reader 는 방해받지 않음 여기서 말하는 MVCC (Multi-Version Concurrency Control)란, DB나 테이블 포맷에서 동시에 여러 Reader/Writer가 접근할 때 충돌을 줄이는 기법임 MVCC 의 핵심은 데이터의 여러 버전(snapshot)을 동시에 유지하는 것 Reader 는 “자신이 시작할 때 존재하던 버전(snapshot)”만 읽음 Writer 가 새로운 데이터를 commit해도 Reader는 방해받지 않음 (=새로운 데이터를 쓰던말던 reader 는 자신이 시작할 때 존재하던 버전의 데이터만 읽음) writer 를 실행해도 기존 데이터가 덮어쓰여지지 않고 유지되기 때문에 reader 는 고정적인 데이터를 읽을 수 있음 결과적으로 Reader 는 일관성 있는 스냅샷을 보장받고, Writer 는 자유롭게 새로운 commit을 진행하게 됨 여러 버전을 쭉 유지하게 되므로, 저장 공간이 계속 차게 됨 따라서 compaction(파일을 정리하는 작업)이 주기적으로 필요함 (4) 지속성(Durability) Commit 후에는 메타데이터와 데이터 파일이 안정적으로 저장(S3, HDFS) 커밋 로그와 manifest 파일이 남아 있어 장애 복구 가능 예시) S3 에 저장된 테이블에서 DELETE id=100 실행 시, Hudi/Iceberg는 바로 파일을 수정하지 않고, 새로운 commit 으로 삭제 정보(메타데이터) 를 기록하고 스냅샷을 생성함 Reader는 "해당 commit 이후 snapshot"을 읽으므로 삭제 반영된 데이터만 조회 장애가 발생하면 commit log 를 기반으로 재처리함(ACID 보장) Hudi, Iceberg 모두 자체적으로 메타데이터를 관리함 (참고 https://eyeballs.tistory.com/684) Hive Metastore, Glue Catalog 같은 외부 메타스토어를 사용하여 메타데이터를 관리할 수 있음 이 경우, Spark 등의 외부 쿼리 엔진이 접근해서 데이터를 쿼리할 수 있게 됨 참고) - WAL이란? https://eyeballs.tistory.com/514 |
MVCC (Multi-Version Concurrency Control) 기법 사용하여, Reader 는 특정 시점(snapshot)의 데이터만 읽는다. Using a Multi-Version Concurrency Control (MVCC) approach, a reader only sees a consistent snapshot of the data from a specific point in time. |
Reader 는 “자신이 시작할 때 존재하던 버전(snapshot)”만 읽는다. The reader only sees the version of the data that existed when its read operation began. Writer 가 새로운 데이터를 commit해도 Reader는 방해받지 않는다. A new commit by a writer does not disrupt the reader's operation. disrupt, disturb 둘 다 '방해하다'. |
결과적으로, Reader 는 일관성 있는 스냅샷을 보장받고, Writer 는 자유롭게 새로운 commit을 진행하게 된다. As a result, the reader is guaranteed a consistent snapshot, while the writer is free to make new commits without disruption. |
여러 버전을 유지하면 저장 공간이 계속 차게 되므로 compaction 작업을 주기적으로 진행해야 한다. Since maintaining multiple versions can consume significant storage space, compaction operations must be run periodically. |
Hudi, Iceberg 모두 자체적으로 메타데이터를 관리한다. Both Hudi and Iceberg maintain their own metadata. |
Hive Metastore, Glue Catalog 같은 외부 메타스토어를 사용하여 메타데이터를 관리하면 Spark 등의 외부 쿼리 엔진이 접근해서 데이터를 쿼리할 수 있게 된다. By managing metadata with external metastores like Hive Metastore or Glue Catalog, these formats enable external query engines such as Spark to access and query the data. |
| Hive 와 Data Warehouse 의 차이 |
Hive는 원래 Data Lake 위에서 동작하는 SQL 엔진 즉, S3/HDFS 같은 원시 데이터(Parquet, ORC, CSV 등) 위에 "메타데이터(스키마)"만 정의해 두고, 실제로 쿼리를 실행할 때 데이터를 읽으면서 스키마를 적용함. 그래서 Schema on Read 가 적용됨 전통적인 DW(Snowflake, Redshift, Teradata)는 데이터를 적재할 때 스키마를 엄격히 강제함 (회사에서 쓰던 게 DW 가 아니었구나..... 구분하자면 Data Lakehouse 인 듯) 즉, 데이터를 넣는 순간부터 정합성이 보장되고, 품질 관리 됨 그래서 Schema on Write 가 적용되며, BI, 리포팅 등 "신뢰할 수 있는 데이터"가 필요한 분석 환경에서 유리함 엄밀히 말하면 Hive는 Data Warehouse 자체라기보다는 DWH 역할을 흉내낼 수 있는 Query Engine임 Hadoop/Hive 초기에는 “빅데이터 DW 대체제”라는 포지셔닝이 있었기 때문에, Hive를 기반으로 DW 아키텍처를 구현했다고 많이 불렀으나 Hive는 실제로는 Schema on Read 기반이라, 전통적 DW의 "강력한 Schema on Write 보장"과는 다름 |
데이터를 읽으면서 스키마를 적용하는 것을 Schema on Read 라고 부른다. The practice of applying a schema when data is read is called Schema-on-Read. |
데이터를 넣는 순간부터 정합성이 보장되고, 품질 관리가 된다. Data integrity and consistency are enforced, and quality is managed from the moment data is ingested. |
| datalake 와 datawarehouse 를 함께 사용하면 얻는 이점 |
- 미가공 데이터와 변환 데이터에 다른 방식의 접근 제어를 사용할 수 있어, 데이터 거버넌스가 쉬워짐 - 변환을 통해 중요한 비즈니스 지표를 활발하게 개발하고 미리 계산할 수 있음 - 파이프라인의 구성 요소 각각을 훨씬 쉽게 확장할 수 있음 |
| data warehouse 를 선택하는 기준 |
- 확장성 : 스토리지를 늘려 데이터를 더 많이 저장하고, 컴퓨팅 리소스를 늘려 데이터를 빠르게 처리할 수 있어야 함 - 가격 - 접근성 : 사용자가 쉽게 접근해야 함 - 속도 : 처리 속도가 일정해야하고 필요 이상이어야 함 - 유지보수성 |
| spark 및 spark job 을 튜닝하는 방법들 |
Spark 튜닝은 크게 자원(Resource), 실행계획(Execution Plan), 데이터 포맷/파티셔닝 세 가지 관점에서 접근할 수 있음 1. 자원(Resource) 튜닝 - Executor 메모리 크기, CPU(Core) 개수, Executor 개수 조정하여 자원 추가 - Shuffle spill을 줄이기 위한 메모리 설정 (spark.memory.fraction 등) - Parallelism 조정 (`spark.default.parallelism`, `spark.sql.shuffle.partitions`) 2. 실행계획 최적화(Logical/Physical Plan) - Catalyst Optimizer가 제공하는 자동 최적화 활용 (Filter pushdown, Project pruning) - Wide Transformation 최소화=셔플 최소화 (e.g. `groupByKey` 대신 `reduceByKey`, `mapPartitions` 활용) - Broadcast Join, Sort-Merge Join 등 적절한 Join 전략 선택 groupByKey : 모든 데이터를 shuffle해서 메모리에 올리므로 네트워크 I/O 오버헤드 및 OOM 위험도가 올라감 reduceByKey : shuffle 전에 미리 local reduce(combine)를 수행하여 네트워크 I/O 오버헤드 낮아짐 둘 다 동일한 결과를 내놓지만, reduceByKey 가 (MapReduce 에서 하는 것처럼) combiner 추가 수행하여 더 효율적임 3. 데이터 포맷 / 저장 방식 - Columnar format (Parquet, ORC) 사용 → I/O 효율성 - Partitioning & Bucketing → 특정 쿼리 성능 개선 - Caching & Persistence → 반복 사용되는 DataFrame 재활용 Job 병목 구간에 따라 튜닝 방법이 달라짐 - Out of Memory 발생 → 메모리 추가, executor 개수 조정 - Shuffle 수행 시간이 길어짐 → 파티션 수 조정, Skew 해결 (salting, broadcast join) - I/O 병목 → Parquet/ORC 사용, column pruning - 같은 데이터 반복 조회 → 꼭 필요한 부분만 Cache/Persist 사용 - Skew 발생(특정 키를 기준으로 shuffle 한 이후, 일부 파티션만 과도하게 커지게 되는 현상) → 예를 들어 100개의 partitions 에 row가 각각 even하게 100개씩 존재하는 상황에서 → 이 100개 partitions 대상으로 shuffle 이 발생하고 결과를 보니 → 1번~99번 partitions 에는 단 1 개의 row 만 존재하고 하나의 파티션(100번 partition) 에 나머지 9901 개의 row 가 존재하게 됨 → 이것을 'key skew' 라고 부르며, 100번 partition을 처리하는 task만 엄청 오래 걸리고 메모리 과부하, GC 이슈가 발생할 수 있음 → 이를 피하기 위해 분산기준(key)에 Salting 기법 적용, Broadcast Join 적용(shuffle 을 피하기 위함), Skew Join Hint 사용 실무에서는 "이론적으로 가능한 모든 튜닝"을 적용하기보다 Job 프로파일링을 먼저 진행하여 우선적으로 튜닝 할 부분을 찾음 병목이 어디 있는지 관찰하고 → 거기에 맞는 방법을 적용! 예를 들어 - Spark UI → Stage별 task 시간, Shuffle Read/Write 양, Skew 발생 여부 확인 - 로그 분석 → GC 빈도, OOM 에러 여부 확인 |
"이론적으로 가능한 모든 튜닝"을 적용하기보다, Job 프로파일링을 진행한 후 그에 맞는 최적화 실행한다. Instead of applying every theoretical tuning technique, it's more effective to first profile the job and then apply targeted optimizations. |
| Spark에서 Cache와 Checkpoint의 차이 |
Cache : DataFrame/RDD 중간 데이터를 execution memory/disk에 저장 cache 를 진행한 이후, df를 사용하는 연산 진행시 데이터를 읽거나 변환하지 않고 메모리에 적재된 cache 를 직접 가져와서 연산 진행 cache 가 계보 자체를 끊어주진 않음 데이터 복구 시 계보를 전체적으로 역추적하는 대신 캐싱된 지점부터 재연산할 수 있게 하여 Driver의 복구 부담을 줄여줌 Checkpoint : 계보가 너무 길어질 때, 데이터를 저장하면서 계보를 제거하기 위해 사용 RDD lineage 정보를 끊고, HDFS 같은 안정적인 스토리지(disk)에 저장. 이후 장애 복구할 때 사용 주로 성능 최적화할 때 Cache 사용 주로 복구 안정성을 높일 때 Checkpoint 사용 참고 : https://eyeballs.tistory.com/206 |
메모리에 적재된 cache 를 이용하여 연산을 진행한다. We can use cache in memory to execute queries. We can use an in-memory cache to speed up computations. |
계보를 전체적으로 역추적하지 않고 df 를 복구한다. Df can be restored without backtracking the entire lineage. A DataFrame can be restored without recomputing the entire lineage. |
복구 안정성을 높일 때 Checkpoint 를 사용한다. Checkpointing can be used to increase the stability of a recovery process.....? |
| Skew Join Hint 란 |
Spark SQL 3.0+ 에서 제공하는 기능 join 시 skewed key 를 자동으로 감지하고, 문제의 키를 갖는 데이터를 여러 task 로 나누어 처리하는 최적화 기법 즉, 특정 key 에 대한 "partition 을 쪼개서 분산" 처리함으로써 skew 문제를 줄임 SELECT /*+ SKEW('transactions') */ t.user_id, t.amount, u.country FROM transactions t JOIN users u ON t.user_id = u.user_id; 위처럼 주석으로 /*+ SKEW('transactions') */ hint 를 주면, Spark 은 실행 시점에 skew key (예를 들어 t.user_id=1) 를 자동 탐지하고 이 키의 데이터를 여러 파티션으로 나누고, 네트워크를 통해 서로 다른 executor 에 전송, 분배 또한 users 테이블에서 skew key(u.user_id=1) 를 갖는 row 를 모아서 각 executors 에 전송, 분배 각 executors 은 '넘겨받은 파티션'과 '복제된 users 테이블의 row' 를 갖고 있게 됨 이 둘을 이용하여 local join으로 처리 (마치 broadcast join 한 것 처럼) 원래 방식 (Skew 발생) --------------------------------- Executor1: [t.user_id=1 → 100만 건] + [u.user_id=1 → 1건] // 매우 무거움 Executor2: [다른 key...] Executor3: [다른 key...] 최적화된 Skew Join --------------------------------- Executor1: [t.user_id=1 → 10만 건] + [u.user_id=1 복제] Executor2: [t.user_id=1 → 10만 건] + [u.user_id=1 복제] Executor3: [t.user_id=1 → 10만 건] + [u.user_id=1 복제] ... Executor10: [t.user_id=1 → 10만 건] + [u.user_id=1 복제] → 각 executor가 parallel 하게 처리하여 전체 속도 향상 다른 일반 키들은 기존처럼 처리 결과적으로, skewed key 하나가 전체 성능을 망치는 문제를 피할 수 있음 참고로 (key skew 와 다르게) Node 간 데이터 불균형은 Uneven Data Distribution 또는 Data Locality Issue 라고 불리며 (위와 같이 shuffle 시 나타나는 key skew 처럼) 'skew' 라고 부르지 않음 |
| 클러스터의 자원(memory, cpu) 가 부족한 상황에서 job 을 최적화하는 방법들 |
클러스터의 자원이 부족하기 때문에, 최대한 자원을 효율적으로 사용해야 함 1. Shuffle / Skew 최적화 - Skew key 처리 → salting, skew join hint, broadcast join 활용 - Shuffle 데이터 줄이기 : 네트워크/디스크 I/O 감소 → 불필요한 컬럼 제거(`select`) : project pushdown → 중복 데이터 제거(`dropDuplicates`, `distinct`) → 조인 전 필터링(`filter pushdown`) 2. 메모리 최적화 - Serialization → KryoSerializer 사용 (Java serializer 대비 메모리 효율 ↑, 성능 ↑) - GC 부담 줄이기 → 적절한 partition 수 조정, persist(storage level 선택) - DataFrame API 사용 → RDD 대비 Catalyst 최적화 + Tungsten 메모리 관리 혜택 3. CPU 사용 최적화 - Partition 수 조정 (`spark.sql.shuffle.partitions` 튜닝) 너무 적으면 → executor CPU 코어가 놀고 있음 너무 많으면 → task scheduling 오버헤드 ↑ - UDF 줄이기 - 가능하면 SQL 내장 함수 사용 (벡터화된 연산이 CPU 효율 ↑) 4. Cluster Resource 효율화 - Broadcast Join → 큰 shuffle 방지, 작은 테이블을 각 executor 로 전송 - Adaptive Query Execution (AQE) → 실행 중 partition 수 자동 조정, skew 자동 감지 후 split - Cache/Persist 전략적 사용 → 반복적으로 참조하는 데이터는 캐싱, 단 메모리 부족시 오히려 악영향 → selective caching 필요 5. I/O 최적화 - Columnar Format 사용 (Parquet/ORC) - 필요한 컬럼만 읽음 (I/O ↓, 메모리 ↓) - Predicate Pushdown → 필터 조건이 storage layer 로 내려가서 불필요한 데이터 로딩 방지 참고 AQE : https://eyeballs.tistory.com/245 - 동적 셔플 파티션 통합 Dynamically coalescing shuffle partitions : 작은 크기의 파티션들을 합침 - 동적 전환 조인 전략 Dynamically switching join strategies : 실행 중간에 조인 전략을 더 효율적인 것으로 바꿈 - 스큐 조인을 동적으로 최적화 Dynamically optimizing skew joins : skew 파티션을 나눠서 조인 |
AQE 기술을 통해, 작은 파티션들이 하나의 파티션으로 뭉쳐서 사용된다. Using AQE, multiple small partitions can be coalesced into a single, larger partition. 이를 통해 IO 오버헤드, 스케줄링 오버헤드 등을 만드는 작은 파일 이슈를 피할 수 있다. This helps to avoid the 'small file issue,' which causes problems like I/O and scheduling overhead. |
| data pipeline 에서 데이터 정합성(품질, 유효성)을 유지하는 방법들 |
1. Schema Enforcement (스키마 강제 적용) - Parquet, Avro, Delta, Hudi 같은 포맷에서 스키마를 정의하고, 파이프라인 단계에서 유효하지 않은 레코드는 reject/logging 처리 2. Idempotency (멱등성 보장) - 동일한 데이터가 여러 번 처리되어도, 테이블의 최종 상태는 동일하게 유지하도록 설계 중복된 데이터를 구분할 key(PK) 가 반드시 필요함. 그리고 해당 데이터의 최신성 판단을 위한 key(event_time) 이 필요함 PK 가 같지만 내용이 다른 데이터를 처리하는 상황이 발생할 수 있기 때문에 날짜(event_time)나 kafka offset, sequence time 등을 기준으로 최신성을 판단 위와 같이 데이터에 PK 와 최신성 판단을 위한 컬럼이 갖춰졌다면, 이제 upsert 를 지원하는 테이블에 넣으면 되는데 그것이 바로 Hudi 임 upsert 방식을 사용하는 Hudi를 사용하면 굉장히 쉽게 멱등성 구현이 가능함 3. Deduplication (중복 제거) - 필요하다면, ETL 단계에서 primary key 기준 중복 제거(logical deduplication)를 적용 4. Data Validation (데이터 유효성 검사) - row-level constraint(NULL 체크, 범위 체크), referential integrity(참조 무결성) 체크 5. Monitoring & Alerting (모니터링/알림) - 파이프라인 실행 건수, row count, checksum(hash), 데이터 지연(latency)을 모니터링하여 이상 징후 탐지 6. Transactional Guarantees (ACID 보장) - Hudi/Delta Lake/Iceberg 같은 transactional data lakehouse 기술을 이용해 ACID(원자성, 일관성, 격리성, 지속성) 확보 |
모니터링을 통해 이상 징후를 탐지한다. We can check outliers by monitoring. We can detect anomalies through continuous monitoring. |
How do you ensure data integrity and quality in your data pipelines? Data integrity and quality are important for reliable data engineering. Best practices include:
|
| Spark 의 mergeSchema 옵션이란 |
여러 Parquet 파일에 걸쳐 있는 서로 다른 스키마를 병합하여 하나의 DataFrame으로 로드하는 기능 옵션 true : 각 Parquet 파일의 스키마를 취합하고, 각 파티션에 없는 컬럼은 null로 채워 일관된 하나의 스키마를 가진 DataFrame 생성 이는 스키마 진화(schema evolution)를 지원한다는 의미가 됨 데이터 소스의 스키마가 변경되어도 유연하게 데이터를 처리 가능 품질 관리 등의 이유로,스키마를 강제로 관리해야 하는 상황에서는 꺼야하는 옵션 |
각 Parquet 파일의 스키마를 합치고, 각 파티션에 없는 컬럼은 null로 채워 일관된 하나의 스키마를 가진 DataFrame 생성한다. We can create a DataFrame with a unified schema by merging the schemas from multiple Parquet files and filling any missing columns with null values. |
| 확장 가능한 data pipeline 을 설계하는 방법 |
1. Hadoop, Spark, Flink 같은 분산 처리 프레임워크를 사용하여, 데이터 및 연산 처리를 여러 노드에서 병렬로 실행 2. 스토리지와 컴퓨팅을 분리 데이터 레이크 기반으로 S3, HDFS, Lakehouse(Hudi, Iceberg) 등을 활용하여 스토리지만 독립적으로 확장 가능 컴퓨팅 클러스터도 필요할 때 독립적으로 확장 가능 3. 메시지 큐나 스트리밍 플랫폼을 사용 Kafka, Kinesis 같은 시스템을 사용하면 데이터가 늘어나도 kafka 파티션 수를 늘려서 소비자 그룹이 확장 가능 4. 새로운 요구 사항 충족을 위해 스키마 진화, 모듈화된 DAG 설계 등을 통해 새로운 요구 사항에 유연하게 대처 |
스토리지와 컴퓨팅 노드를 분리하여, 각각이 독립적으로 확장 가능하도록 설계한다. We design the architecture to separate storage and compute resources, allowing each to scale independently. |
| 데이터가 갑자기 10배로 증가하면 생기는 병목 지점과 대응 방법 |
카프카의 경우, 데이터양이 늘어난 만큼 처리량도 늘어야 쌓인 데이터들을 빠르게 처리할 수 있기 때문에 브로커 및 파티션 수를 늘려야 함 카프카의 처리량은 파티션 수에 비례함 (파티션 수에 따라 컨슈머에 의해 병렬 처리 가능해지기 때문) 브로커 수도 늘어나야 디스크 IO 및 네트워크가 분산되어 처리량이 높아질 수 있음 |
Data Lake 의 경우, small file problems 가 발생할 수 있기 때문에 배치 사이즈를 적절하게 적용(128mb ~ 512mb)하고 파티션 전략도 적절한지 재검토 compaction job 을 운영하는 것이 좋음 |
Spark 의 경우, executor 수를 늘리고 master node 의 메모리도 늘림 (rdd, 메타데이터 등을 위해) 늘어난 데이터양에 맞춰 partition 수를 조정하고 data skew 처리(salting 등) 하고 join 전략을 조정함 (broacast join 적극 활용) 보통 병목은 shuffle 단계에서 발생 위에서 말한 것처럼 partition 수 조정 및 skew 해결 기법으로 병목 완화 storage I/O가 병목이 되기도 함 parquet/orc 같은 columnar format과 압축을 활용하여 병목 완화 |
hudi 의 경우, upsert 비용이 올라갈 수 있음 upsert 시 발생하는 index lookup(동일한 데이터가 이미 존재하는지 검색) 및 update 비용이 높아지는 것임 이를 위해, record index 를 사용하는 게 좋은 전략이 될 수 있음 record index 는 PK 를 partition path 에 매칭해둔 정보를 별도의 메타데이터로 저장해두기 때문에 upsert 스캔 비용이 O(1) 에 가까움 (PK 에 따라 파티션이 바뀌지 않는다면, 기본값인 bloom index 를 사용해도 무방) |
Iceberg 의 경우, spark 가 작은 파일들을 대량으로 저장해서 small file problems 가 발생하면 그 작은 파일들 하나하나마다 메타데이터를 관리해야하므로 오버헤드가 될 수 있음 이를 방지하기 위해, 작은 파일을 큰 파일로 합치는 compaction 을 진행 |
scale up 보다는 scale out 이 진행되어야 함 auto scaling 되는 시스템이면 더욱 좋겠음 그리고 monitoring(LAG, latency 등), alarting 시스템도 활용 |
| "트래픽 10배 증가" 와 "데이터량 10배 증가" 의 차이 |
트래픽 10배 증가란 같은 종류의 데이터가 동시에 더 자주 들어오는 상황 예를 들면, 수강신청하는 날 서버로 들어오는 동일한 종류의 데이터가 많아져서 트래픽이 높아짐 kafka 입장에서, 기존에는 초당 1만개 이벤트만 처리하면 되었는데 트래픽이 10배 증가하면 초당 10만개 이벤트를 처리해야 함 처리량이 높지 않으면 kafka lag 이 증가하게 되기 때문에, partition 수를 증가시켜서 병렬성을 높여 처리량 증가 트래픽이 높아지면 동시에 얼마나 많은 요청이 들어오고, 이를 얼마나 빨리 처리할 수 있느냐가 관건이 됨 데이터량 10배 증가란 요청 빈도는 비슷하지만, 데이터 크기 자체가 10배 증가하는 상황 테이블 크기, 파일 크기가 폭증하게 될 것임 저장하는 데이터가 많아질테니, iceberg 는 메타데이터가 더 쌓이게 되고 테이블 크기가 늘어나서 쿼리 스캔 비용이 즐가하게 되고 small files problem 이 발생할 수 있음 이에 따라 파티션 크기/개수 조정, compaction 적용, 파일 사이즈 조정 등이 필요함 데이터양이 많아지면 저장되는 데이터의 크기 및 스캔해야 하는 데이터가 많아져서 IO 오버헤드를 처리하는 게 관건이 됨 트래픽 10배 증가 - 핵심 문제 : 동시성 / 처리 속도 - 병목 지점 : CPU, 네트워크, QPS - 해결 방향 : scale-out, autoscaling - 예시 : Kafka lag, API timeout 데이터량 10배 증가 - 핵심 문제 : 저장·스캔 비용 - 병목 : I/O, 파일 수, 메타데이터 - 해결 방향 : 파티션, 파일 크기, 설계 - 예시 : 쿼리 느려짐, 비용 폭증 |
| 확장성을 고려한 파이프라인 설계와 비용 효율성 간 균형 |
필요할 때만 리소스를 쓰는 on-demand 클러스터(AWS EMR, Databricks auto-scaling 등)를 활용하여 비용 조절 SLA에 따라 cold path(저비용 batch)와 hot path(고비용 real-time)를 분리하는 Lambda/Kappa 아키텍처를 적용하여 확장성과 비용 효율성 둘 다 챙길 수 있음 |
| 서비스 수준 협약(Service Level Agreement, SLA) 란 무엇이고 왜 필요하고 실무에서 어떻게 적용되는가 |
서비스 수준 협약(SLA) : 시스템, 서비스, 또는 데이터 파이프라인이 충족해야 하는 성능/품질 목표를 정의한 약속 고객이 회사에게 기대하는 서비스 수준, 혹은 서비스 제공자와 이용자 간의 합의사항을 기록한 중요한 문서 주로 가용성(Availability), 지연 시간(Latency), 처리량(Throughput), 데이터 신선도(Freshness) 같은 지표가 포함됨 SLA가 없으면 서비스 품질을 객관적으로 판단할 기준이 없고, 장애나 성능 저하가 발생했을 때 "이 정도는 괜찮다 vs 아니다" 판단 가능 예를 들어, 아래와 같은 SLA 를 설정할 수 있음 데이터 파이프라인의 경우 - 매일 오전 8시까지 전일 데이터를 적재 완료 - 실시간 이벤트 데이터는 5분 이내에 대시보드에 반영 웹 서비스의 경우 - 99.9%의 가용성 보장 (월간 약 43분 이하 다운타임 허용) API 서비스의 경우 - 95%의 요청은 200ms 이내에 응답 장애 발생 시 SLA 을 기준으로 빠르게 대응 우선순위를 정할 수 있고 성능 개선의 목표치도 명확해짐 SLA를 만족시키지 못하는 상황 발생시 - 장애 대응 프로세스를 가동해 복구에 집중 - SLA 위반 보고서(Postmortem)를 작성해 원인 분석 및 재발 방지 대책을 공유 예를 들어 실시간 스트리밍 파이프라인이 5분 SLA를 만족하지 못하고 20분 지연되는 상황 발생시 장애의 원인을 찾아 해결하고, 클러스터 리소스 확장, 데이터 파티셔닝 개선, 불필요한 ETL 단계 제거 등의 개선책 마련 |
SLA 란, 데이터 파이프라인이 충족해야 하는 성능/품질 목표를 정의한 약속이다. An SLA is an agreement that defines the performance or quality criteria that data pipeline should meet. An SLA is an agreement that defines the performance and quality targets a data pipeline must meet. |
SLA가 있어야 서비스 품질을 객관적으로 판단할 기준이 생기고, 성능 개선의 목표치도 명확해진다. An SLA provides a clear, objective standard for measuring service quality and defines concrete targets for performance improvement. |
매일 오전 8시까지 전일 데이터를 적재 완료 Complete to load the previous date data until every 8am. All previous day's data must be loaded by 8:00 AM daily. 실시간 이벤트 데이터는 5분 이내에 대시보드에 반영 Reflect the real time event data to the dashboard within 5 minutes. Real-time event data should be reflected on the dashboard within 5 minutes. 99.9%의 가용성 보장. 월간 약 43분 이하 다운타임 허용 Enssure 99.9% availability. Accept downtime for about 43 minutes per a month. Ensure 99.9% availability, allowing for no more than 43 minutes of downtime per month. 95%의 요청은 200ms 이내에 응답 Respond to 95% of all requests within 200ms. |
SLA를 만족시키지 못하는 상황 발생시, 우선적으로 장애 대응 프로세스를 가동해 복구한다. If the system fails to meet its SLA, the first priority is to restore service by activating the DR(disaster recovery) or fault-tolerance process. 그 후, SLA 위반 보고서(Postmortem)를 작성해 원인 분석 및 재발 방지 대책을 공유한다. Afterward, a postmortem report should be written to analyze the root cause of the SLA violation and share a plan for preventing future occurrences. |
| SLA와 SLO(Service Level Objective), SLI(Service Level Indicator)의 차이 |
- SLI (Service Level Indicator) : 서비스 품질을 실제 측정한 지표 (예: 한 달 평균 응답 시간은 100ms, 가용성은 99.1%로 측정되었군) - SLO (Service Level Objective) : 내부적으로 세운 목표치 (예: 적어도 가용성 99.95% 는 맞추자!) - SLA (Service Level Agreement) : 외부 고객/비즈니스와 합의한 약속 (예: 가용성 99.90%, 위반 시 보상해드리겠습니다) |
SLI 는 서비스 품질을 실제 측정한 지표를 의미한다. SLI means an indicator to measure the service quality. SLI stands for Service Level Indicator, and it refers to a quantifiable metric for measuring a specific aspect of a service's performance. quantifiable : 수량화된 |
한 달 평균 응답 시간은 100ms로 측정되었다. The average monthly response time was measured at 100ms. on average : 평균적으로 |
| at most once, at least once, exactly once 간 차이 및 구현(implement) 방법 |
참고 : https://eyeballs.tistory.com/m/714 |
| MPP 데이터베이스의 의미와 의의, 용도 |
MPP (Massively Parallel Processing) : 많은 노드가 병렬로 데이터를 처리하도록 설계된 데이터베이스 데이터와 쿼리를 여러 노드에서 분산 처리 CPU, 메모리, 디스크를 병렬 활용하기 때문에 대규모 데이터 처리 속도 향상 일반적인 단일 서버(DBMS)에서는 어려운 수 TB~PB급 빅데이터 분석 처리 가능 MPP 의 예 - HDFS(or S3) + Hive(or Presto) + Spark 조합 상용 제품(아래)과 비교해서 관리·최적화 난이도가 높음 - Snowflake, Redshift, Teradata 등의 Data Warehouse. 대규모 데이터를 분석하고 BI 보고서 작성하기 위함 - BigQuery, Amazon Redshift Spectrum. 웹/앱 로그, 이벤트, 센서 데이터 집계 및 분석 간략한 구조 : [ 클라이언트 쿼리 ] v [ Coordinator 노드 ] → 쿼리 분해, 각 노드로 분배 v [ Worker 노드 1..N ] → 각자 데이터 파티션 병렬 처리 v [ Coordinator 노드 ] → 결과 집계 후 반환 전통적 RDBMS(OLTP) MPP 비교 : - OLTP(RDB) : 트랜잭션 처리, 작은 row 단위 연산 최적화 - MPP : 대규모 분석용 OLAP, 집계/조인/복잡한 쿼리 처리 최적화 MPP 의의 : - 빅데이터 환경에서 복잡한 대용량 쿼리를 빠르게 처리 가능 - Data Warehouse, BI, 분석 보고서, ML 학습용 feature 추출 등에 적합 MPP에서 데이터 파티셔닝이 잘못되면 Node 간 데이터 불균형(Uneven Data Distribution) 발생해서 병목이 될 수 있음 작은 규모의 데이터나 쿼리, 실시간 OLTP를 MPP 에서 실행하는 것은 비효율적임 작업 스케줄링 오버헤드(분산 계획 수립 비용), join 쿼리 실행시 shuffle 로 인한 네트워크 비용, MPP 내 노드간 동기화 비용, ..... 등이 있음 |
| projection pushdown 과 predicate pushdown 의 의미 및 용도 차이 |
1. Projection Pushdown - SELECT 절에서 필요한 컬럼만 읽어오는 최적화 기법 즉, "전체 컬럼을 다 가져오지 말고 필요한 컬럼만 스토리지에서 가져오자"는 것. - 디스크/네트워크에서 불필요한 컬럼을 읽을 필요 없어서 I/O 비용 감소 - Spark/Presto/Athena 같은 엔진에서 DataFrame 크기가 줄어들어 메모리 절약 - 불필요한 컬럼 디코딩/역직렬화 과정을 줄여 CPU 효율이 좋아짐 - columnar 포맷하면 사용할 수 있는 최적화 기법. 반대로 columnar 이 아니라면 사용하기 힘든 기법임 예를 들어 SELECT user_id FROM big_table; - Projection Pushdown이 없으면 → big_table 의 모든 컬럼들을 다 읽고 메모리에 로드 후 그 중 필요한 컬럼 user_id만 사용 - Projection Pushdown이 있으면 → 스토리지 레벨에서 필요한 컬럼 user_id만 읽음 2. Predicate(Filter) Pushdown - WHERE 절의 필터 조건을 스토리지/소스 레벨에서 적용하는 최적화 기법 즉, "필요한 데이터만 필터링해서 가져오자"는 것. - 불필요한 데이터 로드를 하지 않기 때문에 네트워크/스토리지 I/O 비용 절감 - job 레벨에서 필터링하기 전에 소스(DB)에서 바로 필터링 진행. job 의 전체 쿼리 속도 향상 - 대신 스토리지 레벨에서 지원 가능한 조건이어야 함('문자열 해시값이 짝수인 것만 필터링' 이런건 힘들지도...) - 필터링 대상 row 수에 따라 최적화되는 정도가 달라짐 예를 들어 SELECT user_id, age FROM big_table WHERE country = 'KR'; - Predicate Pushdown이 없으면 → 테이블 전체를 읽고 메모리에 로드 후 country='KR' 조건 적용 - Predicate Pushdown이 있으면 → 스토리지 레벨에서 필터 적용. country='KR'에 해당하는 row만 읽음 Projection Pushdown : select 를 통해 컬럼(column) 줄이는 용도 Predicate Pushdown : where 를 통해 행(row) 줄이는 용도 Parquet 포맷 파일에서 데이터를 읽는 경우 - Projection Pushdown 적용하면, Parquet 파일에서 필요한 컬럼만 읽음 (columnar 포맷이라 가능) - Predicate Pushdown 적용하면, Min/Max 인덱스를 사용해 불필요한 Row 스킵 가능 partitioning 테이블 대상으로 쿼리 할 때도, predicate pushdown 기법이 적용될 수 있음 |
Predicate pushdown 은 WHERE 절의 필터 조건을 스토리지에 위임하는 최적화 기법이다. Predicate pushdown a optimizing strategy that delegates the filter condition from the where statement to storage. Predicate pushdown is an optimization strategy that delegates filter conditions from the query's WHERE clause to the underlying data source. underlying : 근원의, 근본적인, 여기서는 '기본적인' 으로 쓰임 |
대신 스토리지 레벨에서 지원 가능한 조건이어야 한다. However, this optimization is only effective if the filter condition is natively supported by the storage layer. '문자열 해시값이 짝수인 것만 필터링' 같은 조건은 적용되지 않는다. A condition such as 'filtering only those with even number of a string hash value' is not supported. 짝수만 필터링한다. Filter only even numbers. |
필터링 대상이 되는 row 수에 따라, 최적화되는 정도가 달라진다. The degree of optimization depends on the number of records that can be filtered out. |
| CI/CD 의미와 이것을 사용하는 이유 |
1. CI : Continuous Integration(지속적 통합) - 여러 개발자가 만든 코드를 지속적으로 공용 저장소에 통합하고, 자동 빌드와 테스트를 통해 코드 품질을 검증하는 과정 - GitLab CI, GitHub Actions, Jenkins 등으로 코드 푸시 → 빌드 → 유닛테스트 자동 실행 2. CD : Continuous Delivery/Deployment(지속적 제공/배포) - CI 이후 검증된 코드를 자동으로 스테이징 환경에 배포하거나, 심지어 승인 절차를 거쳐 프로덕션까지 자동 배포하는 과정 - 예) CI로 통합된 애플리케이션을 Docker 이미지로 빌드하고, ArgoCD나 Spinnaker를 통해 Kubernetes 환경에 자동 배포 - Continuous Delivery : 시스템에 의한 자동 배포는 스테이징(테스트) 환경에만. 사람이 승인 후 프로덕션에 배포 - Continuous Deployment : 승인 단계 생략하고 시스템이 프로덕션에 배포 CI/CD가 필요한 이유 - 효율성: 배포 속도가 빨라지고, 사람 손으로 하는 반복적인 작업이 줄어듦 - 안정성: 코드 변경이 자동으로 테스트되므로 버그가 초기에 빠르게 발견됨 - 일관성: 배포 환경에 따라 “내 로컬에서는 되는데 서버에서는 안 돼요” 문제 감소 - 빠른 피드백 루프: 코드 품질 문제를 즉시 확인 가능 CI/CD를 사용하지 않으면 - 개발자가 수동으로 빌드/배포 → 과정이 느리고 실수 발생 가능. - 테스트를 매번 수동으로 해야 하므로 버그가 늦게 발견됨. - 배포 절차가 표준화되지 않아, 같은 코드를 배포해도 환경마다 다르게 동작할 위험 있음. - 결과적으로 서비스 속도·품질·안정성 모두 저하. |
배포 절차가 표준화되지 않아, 같은 코드를 배포해도 환경마다 다르게 동작할 위험이 있다. Without a standardized deployment procedure, the same code can behave differently across various environments. |
| 동일한 timestamp 를 갖는 두 개의 서로 다른 데이터를 입수했을 때 처리 방법 |
동일한 timestamp 를 갖는 상황에서 서로 다른 데이터를 어떤 순서로 적용하는냐가 관건임 1. 추가적인 순서 기준 도입 timestamp 외에 sequence_number 같은 다른 기준을 추가함 예를 들어 DMS 를 통해 데이터를 입수한 경우, DMS 가 제공하는 AR_H_CHANGE_SEQ 값을 통해 업데이트 이벤트를 고유하게 식별할 수 있는 값이 만들어짐 이 값은 incremental 값을 갖고 있으므로, 트랜잭션의 순서를 알 수 있음 이 값을 통해 순서를 설정하고 차례대로 적용하면 됨 google drive>codes>etl_codes>20250404_004847.jpg google drive>wiki>troubleshootings>20250404_130158.jpg google drive>wiki>troubleshootings>20250404_130246.jpg 2. 정책을 미리 정해둠 Operation 우선순위 규칙을 정의해둠 '같은 timestamp라면 DELETE를 항상 우선 적용한다', '아니다, UPSERT를 항상 우선 적용한다' 등의 규칙 3. Ingestion 시스템 레벨에서 순서를 강제하게 만듦 예를 들어, kafka 에 데이터를 넣는 producer 가 무조건 데이터를 순서대로 넣도록 보장함 그럼 데이터를 입수하는 쪽에서는 timestamp 가 동일해도 "입수한 순서" 자체를 ground truth 로 삼고 처리하면 됨 |
동일한 timestamp 를 갖는 상황에서 서로 다른 데이터를 어떤 순서로 적용하는냐가 관건이다. When multiple events share the same timestamp, the key challenge is determining the correct order in which to process them. |
timestamp 보다 더 상세한 기준을 만들어 적용한다. In such cases, it is necessary to apply a more fine-grained ordering criterion than the timestamp alone. |
이 값은 업데이트 이벤트를 고유하게 식별할 수 있는 값이다. This value can be used to uniquely identify update events. |
데이터를 입수하는 쪽은 입수한 순서를 ground truth 로 생각하고 순서대로 처리한다. The data ingestion system assumes the order of arrival is the single source of truth and processes events accordingly. |
| 데이터를 입수할 때 사용되는, create_time(데이터가 생성된 시간)과 update_time(데이터가 업데이트 된 시간)의 용도 차이 |
1. create_time (데이터 생성 시각) - 특정 기간 동안 신규로 생성된 데이터를 추출=데이터 생성 시간으로 정리 (예: "이번 달 신규 가입자 수") - 데이터의 라이프사이클 관리 (예: 보관, 삭제 정책 적용 기준) 2. update_time (데이터 수정 시각) - 최신 데이터를 판별하는 기준으로 사용=최신 데이터가 필요할 때 사용 - CDC(Change Data Capture) 시스템에서 변경 감지 기준으로 사용 - 최근 변경된 데이터만 찾아서 동기화 (예: DW 적재, 캐시 업데이트) create_time 과 update_time 두 값을 이용하여 SCD(Slowly Changing Dimension) 관리 가능 (아래 설명) 예를 들면, 이 두 값을 활용하여 '유효 기간(Validity Period)'을 계산할 수 있음 |
| SCD(Slowly Changing Dimension) 란 |
데이터 웨어하우스나 데이터 마트에서 차원(Dimension) 데이터가 시간이 지남에 따라 어떻게 변화를 관리할 것인가를 다루는 개념 차원 테이블(Dimension Table) 의 속성이 변경될 때, 그 변경 사항을 어떤 방식으로 반영할지를 정의하는 전략 고객 정보, 제품 정보, 주소, 부서 같은 차원 데이터는 자주는 아니고 가끔씩 변하기 때문에 "Slowly Changing" 이라고 부름 주요 유형 (Type 0 ~ Type 3) 1. SCD Type 0 – 변경 없음 - 변경이 발생해도 원래 값을 그대로 둠. - 예시: 고객 이름을 바꾸더라도, 데이터 웨어하우스에는 최초 등록된 이름만 저장. 2. SCD Type 1 – 덮어쓰기 (Overwrite) - 변경 발생 시 기존 값을 그냥 덮어씀. 과거 데이터는 사라지고, 항상 최신 상태만 유지. - 과거는 중요하지 않고 최신 상태만 필요한 경우에 사용 - 예시: 고객 주소가 "서울" → "부산"으로 변경되면 차원 테이블에는 부산만 남음. "과거에 고객이 서울에 살았다"는 정보는 알 수 없음. 3. SCD Type 2 – 이력 관리 (History Tracking) - 변경 발생 시 새로운 row를 추가해서 이력 관리. - 과거 이력 분석이 필요한 경우 사용 - 보통 효력 시작일 (start_date) / 효력 종료일 (end_date) / is_current 같은 컬럼을 둠. - 예시 : 고객 주소가 "서울" -> "부산" 으로 변경되었다면 차원 테이블에는 두 가지 row 가 다 들어있게 됨 고객 주소 create_time update_time is_current eye 부산 1991-06-25 2025-11-04 Y eye 서울 1991-06-25 1991-06-25 N 4. SCD Type 3 – 제한된 이력 관리 - 변경 전/후 값을 컬럼으로 저장 - 예시 고객 현주소 전주소 eye 부산 서울 |
| 데이터 모델링이란? Can you explain the design schemas relevant to data modeling? (star, snowflake) |
https://eyeballs.tistory.com/m/735 |
| 데이터 모델링 예시 |
Spark + Hudi + Parquet + Partitioning 등 세부 사항을 포함해서 전자상거래 데이터를 처리하는 데이터 레이크하우스 기반 메달리온 아키텍처 파이프라인을 단계별로 설명 - 전자상거래 데이터가 Kafka, MySQL 등으로부터 입수됨 컬럼 설명 order_id 주문 ID user_id 고객 ID product_id 상품 ID quantity 구매 수량 price 상품 가격 order_timestamp 주문 시간 payment_method 결제 수단 shipping_address 배송 주소 product_category 상품 카테고리 product_brand 상품 브랜드 - bronze : 입수된 데이터는 Data Lake 에 원본 그대로 저장됨 S3 에 입수한 날짜를 기준으로 파티셔닝하여 저장할 것이며 압축 효과를 보기 위해 데이터 포맷은 columnar 인 Parquet 을 사용 s3://data-lake/bronze/orders/ingestion_date=2025-11-22/raw_json.parquet - silver : Data Lake 내 데이터를 분석용으로 정제하고 구조화 함 schema validation 하고 중복이나 왜곡을 제거함 schema evolution 이 지원되는 hudi,iceberg 로 테이블 포맷 설정 아래와 같이 팩트 테이블과 디멘전 테이블 2개로 정리 (star schema) < silver_orders (fact table) > 컬럼 설명 order_id 주문 ID (PK) user_id 고객 ID (FK) product_id 상품 ID (FK) quantity 구매 수량 total_price price * quantity order_timestamp 주문 시간 payment_method 결제 수단 < silver_users (dimension table) > 컬럼 설명 user_id 고객 ID (PK) name 고객 이름 email 이메일 signup_date 가입일 < silver_products (dimension table) > 컬럼 설명 product_id 상품 ID (PK) category 상품 카테고리 brand 상품 브랜드 price 단가 - gold : 특정 분석 목적에 맞춰 데이터 처리/조작 한 결과를 테이블에 씀 Silver fact/dimension 테이블에서 필요한 컬럼을 집계함 하루, 주, 혹은 월 단위로 집계 진행 주로 통계 대시보드를 보거나, 리포트를 하기 위한 용도 컬럼 설명 date 일자 total_orders 총 주문 수 total_revenue 총 매출 top_category 가장 많이 팔린 카테고리 top_brand 가장 많이 팔린 브랜드 |
| 인기있는 엔지니어링 도구를 선택해야 하는 이유 |
| 이건 내 생각을 적어보고 영어로 말할 수 있도록 해보자 |
| 회사에서 사용하던 data pipeline 설명 |
| 회사에서 해온 일들. 상황, 내가 한 일, 그리고 성과 |
| 현재 회사를 떠나, 캐나다에서 일 하고 싶은 이유 |
| 자동화 모델도 설계해보았고, (비용 줄이도록) 데이터 전체 점검하고 결과도 내놓았으나, 그렇구나 하고 말았음 -_-ㅗ 심지어 데이터 정합성 시스템을 추가하자고 말했는데 안 들음ㅗ |
| production database 를 datawarehouse 로 복사할 때 CDC 를 사용하는 이유, 이 과정에서 사용되는 WAL 의 의미 |
운영 DB(Production DB)에서 발생하는 트랜잭션(삽입/수정/삭제) 내역을 추적하여 Data Warehouse(DWH)에 반영할 때 CDC(Change Data Capture) 를 사용 운영 DB 전체를 주기적으로 Full Dump 하면 성능 부담이 크고, DWH 동기화 지연이 발생함 CDC는 변경분만 캡처하므로 리소스 절약 + 거의 실시간 동기화 가능 데이터 무결성을 유지하면서 운영 시스템 부하를 최소화할 수 있음 WAL(Write Ahead Log) 는 데이터베이스의 내구성(ACID의 D)을 보장하기 위한 로그 구조 DB에 변경이 발생하면 실제 데이터 파일에 반영하기 전에 WAL(로그)에 먼저 기록 CDC 시스템은 이 WAL을 읽어 변경 내역을 추적함 WAL 은 DB 엔진 수준에서 추적하기 때문에 가장 정확하고 실시간성이 뛰어남 MySQL의 binlog 가 WAL에 해당함 |
| 데이터 랭글링(Data Wrangling) 과 ETL 차이 |
1. ETL (Extract, Transform, Load) - 여러 원천 시스템에서 데이터를 추출(Extract) → 변환(Transform) → 적재(Load)하는 전통적 데이터 통합 방식 - 데이터 웨어하우스나 분석 환경에 정제된 데이터를 적재하여 분석·리포팅에 활용하기 위함 - 주로 배치 처리(batch) 위주 - 정형 데이터 중심 - 일관성과 표준화를 중시 2. 데이터 랭글링(Data Wrangling) - 다양한 원천에서 들어온 데이터 분석을 위해 분석가/데이터 사이언티스트가 데이터를 전처리·가공하는 과정 - 데이터 분석·모델링을 위한 준비 과정 - 주로 애드혹(ad-hoc) 처리. 분석 목적의 일시적/탐색적 데이터 처리 - 반정형/비정형 데이터도 포함 - 분석 목적에 따라 유연한 처리 가능 - 예를 들어, 데이터 과학자가 Kaggle에서 받은 고객 행동 데이터셋을 Pandas로 가공 |
| SQL DB 와 NoSQL DB 의 의미, 차이점, 장단점 |
1. RDBMS - 행(Row)과 열(Column)로 이루어진 테이블 기반 저장 구조. - SQL(Structured Query Language)로 데이터 질의/조작 - 스키마(고정 구조)를 엄격하게 따름 - 강력한 ACID 지원 - 예: MySQL, PostgreSQL, Oracle, MS SQL Server 2. NoSQL DB (비관계형 데이터베이스) - 테이블 대신 유연한 구조: key-value, document, column-family, graph 등 다양한 모델 - 스키마가 고정적이지 않음 (Schema-less 또는 Flexible Schema) - 수평적 확장(Sharding, Partitioning)에 강함 - BASE 모델 지향 (Eventually Consistent) - 예: MongoDB, Cassandra, DynamoDB, Redis 1. RDBMS 장단점 - 장점: 강력한 무결성, 안정적인 트랜잭션 처리(ACID 보장), 표준화된 SQL - 단점: 확장성 제한(Scale-up 중심, 최근에는 sharding 기능이 추가되었으나 관리가 어려움), 스키마 유연성이 떨어짐 2. NoSQL 장단점 - 장점: 수평적 확장 용이, 비정형 데이터 저장 가능, 빠른 개발 속도 - 단점: 트랜잭션 처리 제약, 표준화 부족(DB마다 학습 필요), 데이터 일관성 약함 1. 무결성 (Integrity) 측면 - SQL DB → 강력함 (Foreign key, Constraint, ACID 보장) - NoSQL DB → 상대적으로 약함, 무결성은 애플리케이션 레벨에서 보장하는 경우 많음 2. 확장성 (Scalability) - SQL DB → Scale-up 중심 (비용 증가, 한계 존재) - NoSQL DB → Scale-out 중심 (노드 추가로 무한 확장 가능) 3. 일관성 (Consistency) - SQL DB → 강한 일관성 (Strong Consistency) - NoSQL DB → 최종적 일관성 (Eventual Consistency) 모델 지향 (특히 분산 환경에서) |
| 스트리밍 시스템에서 NoSQL 을 사용하는 이유 |
1. 빠른 쓰기 성능 - 스트리밍 데이터는 초당 수천~수백만 건의 이벤트가 들어오는데, RDBMS보다 NoSQL이 대량 쓰기에 적합함 - 예: Kafka → Consumer → Cassandra 에 저장 2. 수평 확장성(Scalability) - 데이터가 시간에 따라 폭발적으로 증가하므로, 샤딩/노드 확장을 통한 수평 확장이 필수 → NoSQL이 적합 3. 스키마 유연성 - 스트리밍 데이터는 스키마가 자주 바뀔 수 있음 - 예를 들어 IoT 센서 데이터에 새로운 필드가 추가되더라도 NoSQL은 대응이 쉬움 4. 실시간 조회(Real-time Query) - Redis, DynamoDB 같은 시스템은 낮은 지연(latency)으로 실시간 대시보드, 알림 시스템 등에 활용됨 사용자 행동 로그(클릭, 조회, 결제) 처럼, 무결성보다는 빠른 쓰기와 확장이 중요한 곳에서 NoSQL 사용됨 NoSQL 자체에서 무결성(ACID) 이 지켜지지 않기 때문에, 애플리케이션 레벨에서 무결성 추가 처리함 예를 들어, Kafka + Cassandra 에서는 이벤트 중복을 허용하고, downstream 에서 de-duplication 처리 NoSQL 이 단지 쏟아지는 이벤트를 받아내는 용도로 사용되는 것은 아님 NoSQL 을 이용하여 실시간 조회/집계하거나, 빠른 쿼리/검색을 해야하는 경우도 존재함 그래서 Kafka 와 NoSQL 이 함께 보완적으로 사용됨 |
| Why do we use clusters in Kafka, and what are its benefits? |
A Kafka cluster consists of multiple brokers that distribute data across multiple instances. This architecture provides scalability and fault tolerance without downtime. If the primary cluster goes down, other Kafka clusters can deliver the same services, ensuring high availability. The Kafka cluster architecture comprises Topics, Brokers, ZooKeeper, Producers, and Consumers. It efficiently handles data streams for big data applications, enabling the creation of robust data-driven applications. |
| What are the various modes in Hadoop? |
https://eyeballs.tistory.com/m/496 Hadoop mainly works in three modes:
|
| What issues does Apache Airflow resolve? |
Apache Airflow allows you to manage and schedule pipelines for analytical workflows, data warehouse management, and data transformation and modeling. It provides:
|
| Don't Repeat Yourself(DRY) 란 |
DRY(Don’t Repeat Yourself) 원칙은 "같은 로직, 지식, 정의를 중복하지 말라"는 소프트웨어 개발 원칙 중복된 코드를 작성하면 유지보수와 확장성이 떨어지고, 버그 발생 가능성이 커짐 DRY는 재사용성과 일관성을 높이고 유지보수 비용을 줄이기 위해 필요함 - ETL 파이프라인 : 동일한 데이터 정제 로직(예: 결측치 처리, 표준화 로직)을 여러 파이프라인에서 반복 구현하면, 수정 시 모든 파이프라인을 업데이트해야 함. 대신 공통 라이브러리(유틸 함수)나 모듈로 분리해두고 수정은 한 곳에서만 진행 - SQL 쿼리 : 동일한 join/where 조건을 여러 쿼리에 반복 작성하는 대신, 뷰(View) 또는 공통 CTE를 만들어 재사용 - Airflow DAG : 동일한 task 정의를 여러 DAG에서 중복 작성하는 대신, 공용 Operator/TaskGroup으로 분리해서 관리 지나친 추상화(모듈화)를 진행하면 코드가 이해하기 어려워지고 복잡도가 증가하기 때문에 적절한 수준에서 DRY를 적용해야 함 이와 반대로, WET(Write Everything Twice) 가 있음 성능 최적화나 운영 안정성이 더 중요한 경우에는 코드를 중복시켜서 단순화하는 전략을 쓰기도 함 대규모 스트리밍 시스템에서 중복 로직이 분산 노드에 존재하는 것이 오히려 유지보수성이 좋게 만들 수 있음 |
| cross-cutting concern 이란 |
소프트웨어에서 핵심 비즈니스 로직과는 직접적으로 관련 없지만, 여러 모듈이나 계층 전반에 걸쳐 공통적으로 필요하게 되는 기능 하나의 로직에서 필요한 게 아니라, 전반적인 로직에서 필요한 기능들 - 로깅 : 어떤 프로젝트, 어떤 모듈에서든 로깅은 모든 서비스에서 공통적으로 필요함 - 보안 - 모니터링 Cross-cutting-concern 을 구현하기 위해 AOP (Aspect-Oriented Programming) 나 공통 모듈을 라이브러리로 만들어 적용 AOP는 공통 기능을 모듈화해서 비즈니스 로직과 분리하는 것을 의미함 |
| facade 패턴이란 |
복잡한 내부 시스템(클래스, 모듈, 라이브러리 등)에 대해 단순화된 인터페이스를 제공(추상화 abstraction)하는 디자인 패턴 내부의 복잡한 로직을 감추고 클라이언트가 쉽게 접근할 수 있도록 일종의 "출입구(파사드)"를 제공하는 구조 클라이언트는 여러 하위 시스템을 직접 다루지 않음. Facade 객체 하나만 사용하여 해당 시스템 사용 내부 구조는 바뀌어도 외부 API(Facade)는 그대로 유지하기 때문에 변경에 유연함 복잡성을 숨겨서 유지보수성과 가독성 향상 마치, 우리가 Airflow 의 SparkSubmitOperator 를 사용하여 Spark 에 작업을 제출하지만 해당 Operator 내부 동작(Spark에 연결하고 작업을 제출하는 일련의 동작들)을 몰라도 되는 것과 같음 이와 비슷한 패턴으로, Adapter 패턴이 있음 - Adapter 패턴 : 호환되지 않는 인터페이스를 맞추기 위한 패턴 (예: 레거시 코드 연결) - Facade : 복잡한 시스템을 단순화하기 위한 패턴 (예: 단일 진입점 제공) |
| 테스트 대시보드에서 볼 수 있는 95% 99% 등 숫자의 의미 |
- 95퍼센타일(95th percentile) : 전체 측정값 중 95%의 값이 이 숫자 이하라는 뜻. 즉, 상위 5%만 그보다 큰 값. - 99퍼센타일(99th percentile) : 전체 측정값 중 99%가 이 숫자 이하, 상위 1%만 더 큰 값. 예를 들어 API 응답 시간 대시보드에서 아래와 같은 수치를 해석해보면 ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ 평균 응답 시간 = 200ms 95퍼센타일(P95) 응답 시간 = 400ms 99퍼센타일(P99) 응답 시간 = 800ms ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ - 전체 요청 중 95%는 400ms 이내에 끝남 - 99%는 800ms 이내에 끝남 - 최악의 1%는 800ms보다 느림 - 95% 의 사용자들이 400ms(0.4초) 이내에 응답을 받음을 보여줌 - 99% 의 사용자들은 800ms(0.8초) 이내에 응답을 받음을 보여줌 - 1% 의 사용자들은 응답받는 데 800ms 이상 걸리는 것을 보여줌 즉, 퍼센타일에 나타난 숫자는 '경계값(threshold:문턱)' 임 평균도 아니고 중위값도 아닌, 그냥 경계값 퍼센타일을 사용하는 이유는 다음과 같음 - 평균(mean) 값은 소수의 느린 요청(아웃라이어)에 크게 흔들려 신뢰하기 어렵기 때문에 사용하지 않음 - 하지만 퍼센타일은 "대부분의 사용자가 경험하는 지연(latency)"을 파악하기에 적합 그럼 중위값 사용하면 되지 않나...? 참고) - (우리가 흔히 말하는) 평균 : average (on average, above average, below average) - 산술 평균 : mean - 중위값 : median |
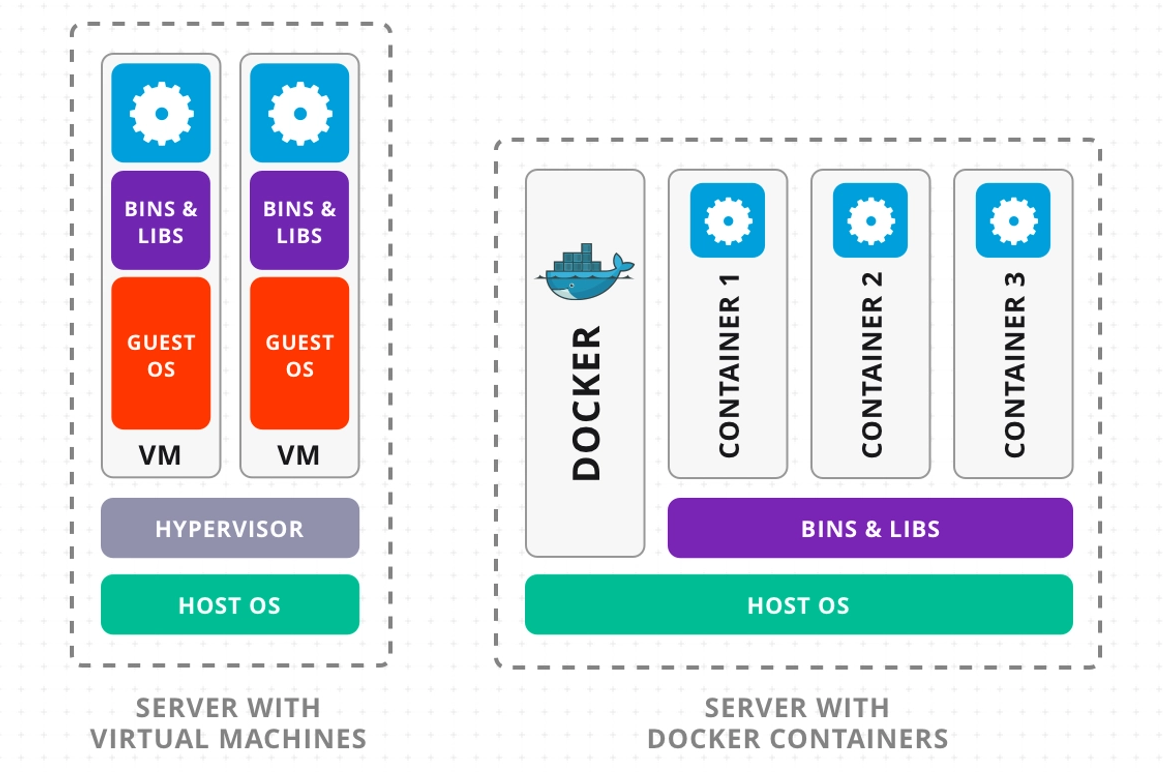
| hypervisor 와 docker 의 의미, 차이점, 장단점 |
1. Hypervisor(하이퍼바이저) - 물리 서버 위에서 여러 개의 가상 머신(VM)을 실행할 수 있게 하는 소프트웨어 계층 (OS 단위로 격리) - 호스트 OS 위 혹은 직접 하드웨어 위에 설치(타입1/타입2) - VM마다 자체 OS, 커널, 라이브러리를 갖고 독립 실행 - 강한 격리성, 각 VM이 완전히 독립적 - OS 단위로 다양한 환경 구성 가능 - 부팅/실행 오버헤드 큼 - 커널/OS 중복으로 인한 높은 리소스 사용량 참고 : 커널 설명 https://eyeballs.tistory.com/328 2. Docker(컨테이너) - OS 수준에서 애플리케이션과 라이브러리를 격리하여 실행할 수 있는 가벼운 컨테이너 (프로세스 단위로 격리) - 호스트 OS 커널 공유 - 각 컨테이너는 필요한 라이브러리/환경만 패키징하고 격리 - 가볍고 빠른 시작/중지 - 동일한 환경을 개발→테스트→운영에 재현 가능 - OS 격리는 약함 → 보안 취약점 존재 가능 - 완전한 OS 독립성은 제공하지 않음 |
| presto 란 무엇이고, 왜 인기있는 SQL 쿼리 엔진이 되었는지. Athena 에서 왜 presto 엔진을 사용하는지 |
Presto : 페이스북이 대규모 데이터 분석을 위해 개발한 실시간 분산 SQL 쿼리 엔진 (여기서 말하는 '실시간'이란, 쿼리 요청 즉시 결과를 반환하는 것을 의미함) SparkSQL 처럼 분산 클러스터 위에서 SQL 을 처리할 수 있는 데이터 처리 플랫폼 이라고 생각하면 됨 - 대화형 쿼리 성능 : Hadoop MapReduce 기반 Hive보다 훨씬 빠르게 결과를 반환할 수 있음(왜냐면 SQL 전용 엔진이라서) - 스토리지 독립성 : 데이터를 복사하거나 이동하지 않고도 HDFS, Hive, S3, Kafka, RDB 등 여러 데이터 소스에 대해 SQL로 질의 가능 - 확장성 : 수십~수천 노드로 확장 가능하며, 페타바이트 단위 데이터도 처리 가능 - 표준 SQL 지원 : ANSI SQL을 사용하므로 기존 SQL 사용자들이 쉽게 적응 AWS Athena 는 S3에 저장된 데이터를 바로 SQL로 질의할 수 있게 해주기 때문에 Presto 엔진을 사용함 Athena는 Presto를 기반으로 “즉시 쿼리 가능(Interactive Query-as-a-Service)”을 실현 Hive는 처리중에 나오는 중간 결과를 디스크에 저장하지만 Presto는 중간 결과물을 메모리에 저장하기 때문에 속도가 훨씬 빠름 presto 동작 과정을 이해하기 위해 간단한 예를 들어 봄 - Presto 의 coordinator, workers 가 YARN Resource Manager 로부터 container를 할당받아 실행됨 - 데이터는 HDFS 에 존재함 - 테이블 정의는 Hive Metastore 를 통해 읽어올 수 있음 - 사용자는 Prestor CLI(혹은 Athena, Hive+Presto) 등을 통해 쿼리를 실행함 - 실행된 쿼리는 Presto 의 Coordinator 가 받아서 파싱하고 최적화하고 실행 계획을 생성함 - 생성된 실행 계획은 Prestor 의 Worker 들이 받음 - 각 Worker 들은 HDFS 로부터 데이터를 직접 읽어와 쿼리 수행 (메모리 사용) - 쿼리 결과는 Client 에게 바로 보내줌 SparkSQL 이랑 똑같네 Spark SQL은 장기 실행되는 배치 작업이나 복잡한 데이터 파이프라인에 더 적합 Presto는 데이터 탐색이나 대시보드와 같은 즉각적인 분석 처리에 더 적합 |
| interactive query 실행시 presto 가 spark 보다 더 빠른 이유 |
1. - spark 는 실행하는 모든 연산을 dag 기반으로 작성한 후에, 분석하고 최적화함 따라서 쿼리 준비 단계에서부터 latency 가 증가하고있음 - presto 는 dag 최적화 단계가 거의 없음 2. - spark 는 쿼리 실행시 driver 가 stage/task 를 다시 스케줄링해야함 - presto 는 worker 들이 항상 살아있고, 쿼리 요청이 오면 스케줄링 없이 즉시 쿼리를 실행함 즉, 스케줄링하는 시간이 거의 없음 그래서 대용량 처리나 스트리밍 처리는 spark 를 사용하고, 대화형 쿼리 실행이나 sql 실행에는 presto 를 사용함 |
| Data Silo 란 |
Data Silo : 조직 내 특정 부서나 시스템에 데이터가 고립되어 있어 다른 부서나 팀과 공유되지 않는 상태 예를 들어, 마케팅팀은 고객 데이터를 CRM에 저장하고, 영업팀은 별도의 ERP에 저장하면서 서로 접근이 어려움 Data Silo 가 발생하면, 중복 데이터, 불일치, 협업 저하, 데이터 기반 의사결정 지연 등의 이슈를 일으킴 - 데이터 일관성 저하 – 부서별 데이터가 달라 분석 결과가 왜곡됨 - 중복 비용 발생 – 저장소, 인력 낭비 - 데이터 기반 의사결정 지연 – 전사적 인사이트 확보 어려움 - 협업 저해 – 부서 간 커뮤니케이션 장벽 Data Silo 이슈를 해결하기 위해 중앙 저장소를 구축하는 것이 좋음 - 데이터 레이크/웨어하우스/레이크하우스 통합 : 중앙화된 저장소 구축 데이터를 단일 진실의 원천 (Single Source of Truth)으로 관리 가능 - 데이터 카탈로그 도입 : 메타데이터 관리로 데이터 가시성 확보 (예: AWS Glue, DataHub) - 데이터 거버넌스 강화 : 표준화된 데이터 정의, 접근 권한 체계 수립 |
| 데이터 품질을 나타내는 기준 |
| - 최신성 : 최신 데이터가 맞는지. 업데이트가 생략되거나 잘못된 데이터가 없는지 - 분포 : 크기, 형식 등이 허용 범위 내에 있는 데이터인지 - 볼륨 : 모든 데이터를 수집/처리했는지. 빠뜨린 데이터는 없는지 - 스키마 : 스키마가 올바른지 |
| 데이터의 의도적 전송 (Intentional Transfer of Data, ITD) 란 |
ITD : 조직 내/외부 시스템 간, 명확한 목적과 계획을 가지고 데이터가 전송되는 과정 단순한 데이터 이동이 아니라, 특정 업무, 분석, 파이프라인 목적에 맞춰 설계된 전송 예를 들어, - 운영 DB → 데이터 레이크로 ETL/CDC를 통해 실시간/배치 데이터 전송 - 센서 IoT 데이터 → Kafka 토픽 → 스트리밍 파이프라인 → 분석 DB로 전달 - 외부 벤더에서 제공한 CSV → S3 → Spark ETL → DW 적재 |
| 데이터 메시(Data Mesh)란 |
데이터 메시 : 대규모 조직에서 데이터 관리와 거버넌스를 분산화하여, 각 도메인이 자신이 소유한 데이터를 제품(Product)처럼 책임지고 제공하도록 설계된 아키텍처 모든 데이터는 Data Lakehouse 등의 중앙 플랫폼에 존재하되, 데이터 관리만 각 도메인팀이 직접함 (예를 들어 A 도메인팀이 Atable 을 관리하고, B 도메인팀이 Btable 을 관리...) 핵심 아이디어: 데이터 소유권과 책임을 중앙 팀이 아닌 각 도메인 팀에 분산 목표: 데이터 접근성과 품질 향상, 스케일링 문제 완화 도메인 소유하기 때문에, 각 팀이 자체 데이터에 대한 책임을 가짐 데이터 제품화(Data as a Product)가 됨. 다른 팀이 사용할 수 있도록 문서화, 품질 관리/향상, SLA 준수 변경 사항이 발생해도 해당 도메인에서 바로 반영/관리 가능하기 때문에 민첩성(Agility)이 높아짐 간단한 예를 들어봄 - 마케팅 팀에서 고객 행동 데이터를 소유함. Hudi/Iceberg 기반으로 Lakehouse에 Marketing Table 에 넣어 관리함 - 영업 팀에서 주문/거래 데이터를 소유함. Lakehouse 에 Business Table 에 넣어 관리함 - Data Scientist는 공통 Lakehouse 플랫폼을 통해 두 팀의 데이터를 쉽게 join하고 분석 가능함 즉, Data Mesh + Lakehouse = 분산 책임 + 중앙 공유 플랫폼 |
| SSH(Secure Shell) 란 |
SSH는 네트워크를 통해 원격 컴퓨터에 안전하게 접근하여 제어하거나 데이터를 전송(scp)할 때 사용하는 암호화된 프로토콜 주고받게되는 모든 통신을 암호화하여 외부의 도청이나 해킹으로부터 보호 SSH의 주요 특징 1. 보안성 : 클라이언트와 서버 간의 통신을 암호화하여 데이터와 명령이 모두 안전하게 전송되도록 보장 2. 원격 제어 : SSH 클라이언트(PuTTY, 터미널 등)를 사용하여 SSH 서버 컴퓨터에 원격으로 명령어를 실행 가능 3. 인증 : 사용자 ID와 패스워드 외에도 SSH 키를 사용하여 인증을 할 수 있음 SSH 키 인증은 패스워드보다 훨씬 안전하며, 자동화된 스크립트에서 많이 사용됨 4. 터널링(Tunneling) 및 포트 포워딩 : 다른 네트워크 프로토콜의 트래픽을 SSH 연결 내에서 안전하게 전송하는 터널링 기능을 제공 암호화되지 않은 프로토콜(예: HTTP)도 SSH 터널을 통해 안전하게 사용할 수 있음 SSH의 작동 방식. 두 가지 단계로 이루어짐 1. 핸드셰이크(Handshake) - SSH 클라이언트가 SSH 서버에 연결을 요청 - 클라이언트와 서버는 서로의 신원을 확인하고, 안전한 암호화 통신을 위한 세션 키(Session Key)를 생성 이 과정에서 대칭키(Symmetric Key) 암호화와 공개키(Public Key) 암호화 기술이 모두 사용됨 - 생성된 세션 키는 한 번의 연결에만 유효하며, 연결이 끊기면 사라짐 2. 인증 및 통신 - 핸드셰이크 완료 후, 사용자는 서버에 자신을 인증. 아래 두 가지 방법 중 하나를 사용 - 패스워드 인증 : 사용자 ID와 패스워드를 입력하여 인증 - SSH 키 인증 : 사용자의 컴퓨터에 있는 개인 키(Private Key)와 서버에 등록된 공개 키(Public Key)를 사용하여 인증 - 인증이 성공하면, 클라이언트와 서버 간에 암호화된 터널이 생성되고, 사용자는 이 터널을 통해 명령어를 실행하거나 파일을 전송함 |
| SFTP (SSH File Transfer Protocol) 란 |
SFTP는 SSH(Secure Shell) 프로토콜을 사용하여 파일 전송을 안전하게 수행하는 네트워크 프로토콜 FTP의 기능에 SSH 프로토콜을 통합하여 보안을 강화한 방식 SFTP의 주요 특징은 다음과 같음 - 데이터와 명령을 모두 암호화하여 전송함 SFTP는 SSH 터널 안에서 모든 통신이 이루어지므로, ID, 패스워드, 전송 중인 파일 내용이 중간에 노출될 위험이 없음 (반면, FTP는 통신 내용이 암호화되지 않은 평문(plain text)으로 전송되어 보안에 매우 취약함) - 파일 시스템 기능 제공 SFTP는 파일 업로드/다운로드뿐만 아니라, 원격 파일 관리 기능을 제공 예를 들어, SFTP 가 실행되는 서버의 디렉터리 생성, 삭제, 이름 변경 등 다양한 파일 시스템 명령을 SFTP 연결을 통해 원격으로 실행 대부분의 SFTP 서버는 보안을 위해 사용자의 접근 범위를 특정 디렉터리로 제한하며, 이를 'Chroot' 라고 부름 예를 들어, SFTP 사용자가 /home/eyeballs/ 디렉터리에만 접근 허용하면, 사용자는 그 상위 디렉터리인 /home/로 이동 불가함 - 단일 연결 (Single Connection) SFTP는 데이터와 명령을 모두 단일 연결(Single Connection)로 처리 '데이터 전송', '파일 관리 명령'을 하나의 TCP 포트(22번 포트)를 통해 주고받는다는 의미임 (반면, FTP는 명령을 위한 제어 채널과 데이터를 위한 데이터 채널, 두 개의 별도 연결을 사용) 일반적으로 22번 포트 하나만 사용하므로 세션 관리가 훨씬 효율적임 (반면, FTP 는 두 개의 포트를 열어야 해서 복잡함) SFTP 작동 방식 1. 클라이언트의 연결 요청 : 사용자(SFTP 클라이언트)가 SFTP 서버의 22번 포트로 연결 요청 2. SSH 핸드셰이크 : 클라이언트와 서버가 서로의 신원 확인을 위한 SSH 핸드셰이크 진행. 이 과정에서 암호화된 세션 키를 생성 3. 인증 : 사용자 ID/패스워드 또는 SSH 키를 사용하여 인증을 수행 (이 과정은 모두 암호화된 채널을 통해 이루어짐) 4. 파일 전송/명령 수행: 인증 완료 후, 클라이언트와 서버는 생성된 암호화 채널을 통해 파일 전송하거나, 원격 파일 관리 명령을 주고받음 |
| 네트워크 : https://eyeballs.tistory.com/m/582 |
| Public |