[Kafka] Udemy Apache Kafka 시리즈 – 초보자를 위한 아파치 카프카 강의 v3 필기
Topic 은 RDB 의 table 과 같은 개념. 카프카를 통해 흐르는 데이터들이 모이는 장소.
사용자가 원하는 건 모든 kafka topic 으로 보낼 수 있음 (제약 혹은 데이터 검증이 없음)
직렬화 가능한 어떤 종류의 메세지라도 받을 수 있다고 함. 예를 들어 Text, Json, Avro, binary...
사용자가 원하는만큼 많은 topic 을 만들 수 있음
kafka 에서 topic 은 'name' 으로 식별됨.
topic 내의 메세지 순서를 '데이터 스트림' 이라고 부름
topic 내의 데이터는 (일반적으로는) 쿼리할 수 없음.
대신 topic 으로 데이터를 보내고(produce) 그 데이터를 받는(consume) 기능 사용이 가능
topic 은 "partition" 으로 분리가 되며, 사용자가 원하는 만큼의 partition 을 만들 수 있음
예를 들어 topic A 를 3개의 partition 으로 분리할 수 있음.
이 topic 에 보내진(produce) 데이터는 각 파티션으로 들어감
kafka topic 에 저장한 데이터는 (특별한 전략에 의해) 정해진 파티션 중 하나에 쓰여지게 됨
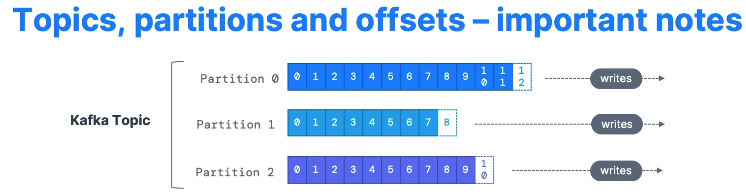
각 파티션 안의 메세지들은 들어온 순서대로 순서가 정해짐.
파티션 안에서 정해진 메세지들의 순서를 offset 이라고 부름
예를 들어 partition 0 에 세 개의 메세지가 들어감
[ 0, 1, 2 ] 이렇게 각각의 메세지에 들어온 순서대로 id가 붙고, 이 id 는 offset 이 됨
kafka topic 은 immutable, 즉 수정할 수 없는 성격을 갖음.
한 번 데이터가 쓰여지면, 업데이트 할 수 없음
Kafka topic 내 데이터는 일정 시간 동안만 유지됨. 이것은 TTL 혹은 retention time 이라고 부름
기본적으로 7일 동안 유지되며, 관리자가 변경 가능.
retention time(7일) 만큼의 시간이 지나면 먼저 들어온 순서대로 (offset 이 작은 것 먼저) 사라짐
사라진 offset 은 재사용이 불가능함 (사라진 offset 에 대한 메세지 자체가 사라졌기 때문에)
retention.ms 설정으로 retention time 변경 가능
topic 을 partitions 로 나눈 존재하는 이유는 다음과 같음
topic 내 데이터를 partition 으로 나눔으로써 병렬처리를 할 수 있게 됨
각 partition 단위로 독립적인 데이터 읽기 쓰기 작업이 가능함
(producer 는 병렬로 데이터를 쓰고, consumer 도 병렬로 데이터를 읽음)
만약 파티션이 없다면, 하나의 컨슈머 그룹 내에서 여러 컨슈머가 동일한 데이터를 중복해서 읽거나,
읽기 작업을 조정하는 복잡한 메커니즘이 필요하게 됨.... 생각만해도 끔찍하군
병렬처리에서 더 나아가, 수평적 확장성도 갖을 수 있게 됨
(kafka server 에 가해지는 부하가 낮추기 위해) 새로운 kafka server 를 추가하면
새로운 broker 에 partition 단위의 데이터가 분산 저장되기 때문에
consumer 의 읽기 병렬성이 올라가고, 그로 인해 부하가 낮아짐 (쓰기 부하는 좋아지지 않음. 왜냐면 쓰기는 leader partition 에서만 발생하기 때문에 서버가 늘어나던 말던 하나의 서버에만 쓰기 부하가 가해짐)
만약 파티션이 없다면, 그룹 내 컨슈머들 여럿 있다고 해도, 하나의 거대한 stream 은 (하나의 파티션은 하나의 컨슈머가 처리하므로) 단 하나의 컨슈머만 처리하게 되고, 부하가 마구마구 올라가게 됨
topic 을 partition 으로 나눔으로써, 오프셋 관리가 용이하게 됨
각 파티션은 자체적인 순서와 오프셋을 가지고, 각 컨슈머 그룹이 각 파티션 내에서 자신이 마지막으로 소비한 메시지의 위치를 독립적으로 추적할 수 있도록 함.
만약 파티션이 없다면, 모든 컨슈머 그룹이 하나의 거대한 스트림에서 오프셋을 관리해야 하므로 매우 복잡하고 비효율적이 됨
Producer 는 kafka topic 에 데이터를 저장하는 역할을 하는 kafka 프로그램
Producer 가 topic 에 데이터를 저장할 때, 'partitioner'를 통해 topic 내 어떤 partition 에 쓸지 결정함
어떤 partition 에 데이터를 쓸 지 결정하는 것은 producer 임
어떻게? producer client 에서 partitioner 클래스를 실행해서.
실행된 파티셔너가 메시지의 키, 토픽 메타데이터 (파티션 정보. kafka broker 에 요청해서 미리 받아갖고 있음) 등을 기반으로 파티션 번호를 선택하고 선택된 파티션의 리더 브로커에게 쓰기 요청을 보냄
프로듀서가 저장하는 데이터(메세지)에는 key 값이 존재함
그리고 이 key 값은 partition 을 결정하는 데 사용됨
이 key 를 hashing 처리하여 나온 hash 값을 기준으로 (메세지가 저장될) partition 이 결정됨
어떤 key를 넣어야 어떤 hash값이 나와서 어떤 partition 에 데이터를 넣을지는 모름
key 값은 string, number, binary 등 다양한 포맷을 갖으며,
key 값을 사용자가 직접 결정할 수 있음
다르게 말하면, 지금부터 쓸 메세지가 기존과 동일한 partition에 데이터를 쓰도록 만들지
아니면 기존과 다를 수 있는 partition에 데이터를 쓰도록 만들지 사용자가 결정할 수 있음
만약 메세지 내 key 값이 null 이라면(=메세지에 key 값이 존재하지 않음)
특별한 partition 선택 전략에 의해 partition 이 선택되어지고 그 partition 에 데이터를 저장함 (위에서 설명한 부분)
만약 메세지 내 key 값이 존재한다면
이 key 의 hash 값을 이용하여 매칭된 partition 에 데이터를 저장함
(사용자가 직접 partitioner를 지정했어도, partitioner 는 무시됨)
참고로 동일한 key 를 사용하는 메세지들은 (심지어 다른 프로듀서에서 지정한 것이라도)
hash 값이 같기 때문에, 동일한 partition 에 데이터를 저장함
즉, 동일한 key 값을 갖는 메세지들은 하나의 partition 에 저장됨!
예를 들어, A topic에 파티션이 3개 있고 총 6개의 메세지를 보낸다고 가정했을 때, key 와 partition 매칭이 아래와 같음
(이해를 돕기 위한 예제)
| message key | partition |
| key1 | 1 |
| key2 | 3 |
| key3 | 2 |
| key4 | 1 |
| key5 | 1 |
| key6 | 3 |
어떤 key 가 어떤 partition 에 매칭될지는 사용자인 우리는 모름(;;)
Kafka partitioner (단순한 코드 로직) 라는 녀석이 있고 이 녀석이 키에 따른 파티션을 결정함.
이 파티셔너가 프로듀서로부터 받은 데이터의 키값을 해싱처리하고, 그 결과를 기준으로 파티션을 결정함
이 때 기본으로 사용되는 해싱 알고리즘은 murmur2 이며 아래와 같은 로직으로 이루어져있다고 함
targetPartition = Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1)
응... 그냥 key 를 파티션 수로 나눈 나머지를 사용하는구나
producer 가 발행하는 메세지는 다음과 같이 생겼음

Key : binary 형태. partition 을 결정하기 위한 값
Value : message 의 내용. 즉, 우리가 저장하고 싶은 데이터. binary 형태
Compression Type : message 의 내용을 압축하고 싶을 때 사용하는 옵션값
Headers : 옵션으로 추가 가능한 message 의 헤더. 메타데이터 넣는 부분.
Partition + Offset : ?? 왜 여기 포함되어있다고 설명하는건지 모르겠음. partition 이나 offset 모두 (데이터 저장 후) 카프카 브로커가 결정
Timestamp : 메세지가 발행된 시간. producer 의 시스템이나 사용자가 넣음
Kafka 가 프로듀서로부터 받은 메세지의 Key, Value 는 only bytes 로 저장됨
그리고 컨슈머에게 전달할 메세지의 Key,Value 도 only bytes 로 전달됨
따라서 프로듀서는 Kafka 로 메세지를 보낼 때 직렬화해야하고,
컨슈머는 Kafka 로부터 받은 메세지를 역질렬화해야 함


여기서 알 수 있는 점은, Producer 나 Consumer 둘 다 동일한 데이터 타입을 사용해야 한다는 것임
프로듀서가 A 토픽에 여태까지 Text 로 된 데이터를 보내고 있다가, 갑자기 다른 포맷인 Avro 데이터를 보내게 되면
A 토픽을 읽고있던 컨슈머가 갑자기 이해할 수 없는(역직렬화가 불가능한) 데이터를 받게 됨
(컨슈머에 Avro 를 역직렬화하는 라이브러리가 없으면 해석이 불가능하게 됨)
따라서 어떤 토픽을 사용 할 때는 하나의 데이터 타입만 사용해야 함
만약 다른 데이터 타입을 사용하고 싶다면, 토픽을 아예 새로 만들어야 함.
만약 producer 가 데이터를 저장할 partition 이 (네트워크 이슈 등에 의해) 사용 불가가 되면,
producer 는 broker 로부터 메타데이터를 다시 가져와서 토픽,파티션 최신 정보를 가져온다고 함
이 최신 정보를 기준으로 데이터를 저장할 leader partition 을 선택함
Consumer 는 kafka topic 으로부터 데이터를 읽는 kafka 프로그램
컨슈머에 설정한 topic 이름을 따라 topic 을 결정하고 데이터를 읽어옴(pull)
컨슈머가 읽는 데이터는 하나의 partition 내 offset 값 기준으로 낮은 값부터 높은 값 순서로 읽어옴.
만약 컨슈머가 두 개의 partitions 으로부터 데이터를 읽는다면
이 각각의 partition 으로부터 읽는 데이터의 순서는 보장이 안 됨...
예를 들어 partition1 에 [0, 1, 2, 3] 데이터가 있고, partition2 에 [55,56,57] 데이터가 있을 때
컨슈머가 55, 56, 0, 57, 1, 2, 3 이렇게 읽을 수 있고,
0, 55, 1, 56, 2, 57, 3 이렇게 읽을 수 있고... 서로 다른 파티션 데이터끼리의 순서 보장은 안 된다고 함
참고로 pull 이랑 poll 이랑 조금 다름
poll : 서버에 질의를 보내고, 그 결과를 서버로부터 받음 (예 : SQL Client)
pull : 서버로부터 데이터를 읽음 (예 : Kafka Consumer)
컨슈머는 'consumer group' 에 포함되어 동작함
하나의 그룹 내에 여러 컨슈머들이 존재할 수 있지만,
하나의 컨슈머는 오직 하나의 컨슈머 그룹에만 속함
그룹은 "group.id" 라는 속성property을 설정함으로써 컨슈머의 그룹을 설정할 수 있음
하나의 그룹 내의 컨슈머들은 topic 에서 데이터를 읽을 때 각각 다른 partition 을 읽게 됨
하나의 그룹 내의 컨슈머들은 모든 파티션에서 읽기를 공유함

만약 consumer group 내 consumer 개수가 partition 개수보다 많다면
초과된 수만큼 consumer 가 동작하지 않음

여러 컨슈머 그룹이 하나의 토픽을 읽을 수 있음
그룹이 존재하긴 하나, 결과적으로 (컨슈머 그룹 내) 하나의 partition 은 하나의 consumer 로 처리됨
돌려 말하면, (컨슈머 그룹 내) 두 개 이상의 여러 consumer 들이 하나의 partition 을 처리하지 않음
consumer 가 partition 의 데이터를 읽으면
어디까지 읽었는지 확인하는 consumer offset 이 데이터 읽는 부분까지 업데이트 됨
이것은 commit consumer offset 이라고 하며, consumer client 에서 commit 을 직접 진행함 (kafka broker 에서 하는게 아님)
Kafka 브로커는 컨슈머 그룹별로 각 파티션의 마지막 커밋된 컨슈머 오프셋을 특별한 내부 토픽 (__consumer_offsets)에 저장하고 관리함
만약 컨슈머가 재시작되거나, 새로운 컨슈머가 그룹에 합류하면, 브로커가 미리 저장해둔 offset 정보를 바탕으로 컨슈머에게 어디서부터 consuming 해야 할지 기준이 되는 마지막 오프셋을 알려줌.
commit 에는 두 가지 방식이 존재함
- 자동 커밋 (Auto Commit) : 컨슈머는 일정 간격 (기본적으로 5초)마다 자동으로 현재까지 소비한 메시지의 가장 마지막 오프셋을 커밋
이 방식은 구현이 간단하지만, 데이터 유실 가능성이 있음
컨슈머가 메시지를 처리하는 도중에 오류가 발생하거나 재시작되면 같은 데이터를 중복으로 읽게 됨(offset 이 바뀌질 않아서)
이는 At most once, 또는 데이터 유실 가능성을 내포한 At least once에 가까움
enable.auto.commit을 true로 설정하여 자동커밋하도록 만듦
자동 커밋 간격은 auto.commit.interval.ms 로 설정
- 수동 커밋 (Manual Commit): 컨슈머는 명시적으로 commitSync() 또는 commitAsync() 메서드를 호출하여 오프셋을 커밋
enable.auto.commit 을 false로 설정하여 수동커밋하도록 만듦
commitSync(): 현재까지 소비한 모든 메시지를 동기적으로 커밋
커밋이 완료될 때까지 컨슈머 스레드는 블로킹됨(동기적으로 진행되어야 하기 때문)
데이터 안정성은 높지만, 처리량에 영향을 줄 수 있음
commitAsync(): 현재까지 소비한 메시지를 비동기적으로 커밋
커밋 요청을 보내고 바로 다음 작업 진행이 가능함 (비동기적으로 진행되기 때문에)
콜백 함수를 통해 커밋 결과를 확인할 수 있
처리량은 높지만, 재시도 로직을 직접 구현해야 하는 등 복잡성이 증가할 수 있음
commit 전략이 세 가지 존재함
- At most once (최대 한 번):
메시지 처리 전에 offset 을 commit 함
컨슈머가 메시지를 처리하는 도중 실패하면, 해당 메시지는 다시 처리되지 않고 유실될 수 있음
(메세지를 읽고 바로 commit 함, 그래서 메세지 처리하다가 실패하면 다시 partition 에서 동일한 메세지를 읽을 수 없음
왜냐면 이미 offset 은 commit 되어 업데이트 되었으니까)
자동 커밋의 기본적인 동작 방식임 (오류 발생 시 재처리 보장 없음)
간혹 데이터 유실이 허용되는 일부 시나리오에서 처리량을 높여야 할 때 사용됨
- At least once (최소 한 번):
default 전략.
메시지 처리 후에 offset 을 commit 함
컨슈머가 메시지를 처리하는 도중 실패하면, 해당 메시지를 다시 처리될 수 있음 (중복 처리 가능)
수동 커밋의 동작방식
대부분의 경우 데이터 유실을 방지하기 위해 이 전략을 선호함
중복 처리는 애플리케이션 수준에서 idempotent(멱등성)하게 설계하여 해결할 수 있음
- Exactly once (정확히 한 번):
각 메시지가 정확히 한 번만 처리되도록 보장하는 가장 강력한 전략
Kafka 0.11.0 버전부터 Transactional Messaging 기능을 통해 일부 시나리오에서 정확히 한 번 처리를 지원함
이는 프로듀서와 컨슈머 모두 트랜잭션을 사용하여 메시지 발행과 오프셋 커밋을 원자적으로 처리하는 방식
정확히 한 번 처리는 구현이 복잡하지만, 데이터 정확성이 매우 중요한 경우에 필요
Kafka Consumer 를 프로그래밍으로 구현할 때 "데이터 읽기 poll" 메소드 위치와 "읽은 데이터 처리" 메소드 위치를
어떻게 배치하고 구현하느냐에 따라, at most once, at least once 등의 전략이 구현됨
enable.auto.commit이 true로 설정되면, 컨슈머는 백그라운드에서 주기적으로 현재까지 소비한 메시지의 가장 마지막 오프셋을 Kafka 브로커에 커밋함
이 커밋 주기는 auto.commit.interval.ms에 설정된 값에 따라 결정됨
예를 들어, auto.commit.interval.ms가 5000으로 설정되어 있다면
컨슈머는 5초마다 마지막으로 처리한 메시지의 오프셋을 자동으로 커밋하게 됨
(정확히는, 5초가 지난 이후, consume 메소드(poll) 호출하면 auto commit 진행됨)
이렇게 자동 커밋을 설정해두면 데이터를 유실할 수 있음
만약 컨슈머가 메시지를 처리하는 도중에 오류가 발생하거나 재시작되면, 마지막 자동 커밋 이후에 처리했지만 아직 커밋되지 않은 메시지들이 다시 처리되지 않고 유실될 수 있기 때문
이는 At most once 또는 데이터 유실 가능성을 내포한 At least once 전략에 가깝다고 볼 수 있음
자동 커밋 간격이 짧을수록 컨슈머가 실패했을 때 다시 처리해야 하는 메시지 수가 줄어들어 중복 처리 가능성을 낮출 수 있긴 하지만
반대급부로, 이렇게 커밋 빈도가 잦아지면 약간의 성능 오버헤드가 발생할 수 있음
자동 커밋은 개발 편의성을 제공하지만, 데이터 처리의 안정성을 중요하게 생각한다면 enable.auto.commit을 false로 설정하고 수동 커밋을 사용해야 함
수동 커밋을 사용하면 메시지 처리의 성공 여부를 확인한 후에 오프셋을 커밋하여 At least once 를 구현할 수 있음
수동으로 구현하기 위해 commitSync() 또는 commitAsync() 메소드를 호출. 해당 메소드가 호출되면 오프셋이 커밋됨
여기서 설명한 auto.commit.interval.ms 옵션은 Kafka 컨슈머가 자동으로 오프셋을 커밋하는 주기를 설정하는 옵션
enable.auto.commit이 true로 설정된 경우에만 유효함
기본값: 5000 (5초)
단위: 밀리초 (ms)
Kafka broker 는 kafka server 이며
Kafka server 는 다수의 브로커들로 구성된 클러스터 형태로 만들 수 있음
브로커의 개수는 관리자가 마음대로 늘릴 수 있으며, 이를 수평적 스케일링(horizontal scaling) 이라고 함
각 브로커는 id 를 통해 구분 및 구별됨
모든 브로커가 각 토픽의 파티션을 모두 골고루 나눠갖음
즉, 사용자가 저장한(produce) 데이터는 모든 브로커에 골고루 분산되어 저장됨.
프로듀서나 컨슈머 클라이언트가 kafka cluster 내 아무 브로커에 연결을 시도하면
연결을 시도한 프로듀서/컨슈머 클라이언트는 전체 클러스터에 연결됨.
즉, 브로커 중 하나의 브로커 정보만 알고 접근해도 모든 브로커에 연결됨 (모든 브로커 정보를 다 알 필요가 없다는 의미)
여기서 연결이 시도된 브로커를 '부트스트랩 브로커bootstrap broker' 라고 부름
bootstrap broker는 시스템에서 따로 지정된 게 아니라, 그냥 클라이언트가 처음 접근을 시도한 브로커를 지칭하는 말임.
즉, 모든 브로커가 bootstrap broker 가 될 수 있음
클라이언트가 bootstrap broker 에 연결 성공하면,
bootstrap broker는 자기 외에 다른 모든 브로커들의 리스트를 클라이언트에게 넘겨줌
그래서 클라이언트는 bootstrap broker 외에 다른 모든 브로커들에 연결이 가능해지며,
각 브로커들이 어떤 토픽의 어떤 파티션들을 갖고 있는지 알게 됨
다르게 말하면, 각 브로커는 모든 브로커의 메타 정보(토픽, 파티션 구성 정보 등)를 이미 갖고 있다는 의미
카프카 클러스터를 이루는 브로커들은 각 토픽의 파티션들을 분산하여 저장함
예를 들어, 3개의 파티션을 갖는 Topic-A, 2개의 파티션을 갖는 Topic-B 가 존재하고
이 두 토픽을 3개의 브로커로 구성된 클러스터에 저장하는 경우
아래와 같이 각각의 파티션들은 하나의 브로커에 분산되어 저장됨
(=하나의 브로커가 하나의 토픽 내 모든 파티션을 저장하지 않음)

관리자가 브로커 혹은 토픽(파티션)을 더 추가해도 동일한 방식으로 분산됨 (horizontal scaling)
토픽은 '복제 계수 replication factor' 를 설정하여 토픽의 파티션을 복제할 수 있음
말 그대로 진짜 데이터를 복제하여 중복 저장하는 것임
복제계수가 2면 파티션이 중복으로 (브로커에) 2개 저장됨
복제계수가 3이면 파티션이 중복으로 (브로커에) 3개 저장됨
예를 들어, 파티션이 2개인 Topic-A 을 3개의 broker 로 이루어진 kafka cluster 에 저장한다고 하자
이 때 복제계수를 2로 설정하면 아래와 같이 복제된 파티션들이 각 브로커에 분산되어 저장됨

이렇게 데이터가 중복되어 분산 저장되어 있으면
브로커 중 하나가 제 기능을 못하여 갖고 있던 파티션 데이터를 잃더라도,
다른 브로커가 중복 데이터를 저장하고 있기 때문에 결과적으로 해당 파티션의 데이터를 잃지 않음
즉, 고가용성이 올라감
각 파티션은 'leader partition' 을 갖음
파티션을 복제할 때 'leader partition' 의 것을 (다른 브로커가) 복제하여 가져가게 됨
이렇게 복제하여 저장한 것을 ISR(in-sync replica) 라고 부름

Producer 는 오직 leader partition 을 갖는 브로커에만 접근하여 leader partition 에 데이터를 씀.
마찬가지로, Consumer 역시 leader partition 을 갖는 브로커에만 접근하여 leader partition 으로부터 데이터를 읽음
(kafka 2.4 이상부터는, consumer 와 물리적으로 가까운 kafka broker의 partition replica에 연결하여 데이터를 읽을 수 있도록 바뀜. 이것을 fetching 이라고 함)
만약 leader partition 을 갖는 브로커가 작동을 멈추면?
레플리카(isr)를 갖는 다른 브로커의 파티션이 대신 리더가 됨
만약 leader partition을 레플리카로 복제하는 속도가 느리거나, (네트워크 이슈 등으로) 복제가 지연 될 경우
레플리카가 제대로 만들어지지 않는 등 리더 파티션과 충분히 동기화되지 않을 수 있음
이 경우 충분하게 동기화되지 않은 레플리카를 Out-of-Sync Replica(OSR) 이라고 함
Kafka 브로커에는 팔로워(레플리카)가 리더 파티션으로부터 얼마 동안 뒤처질 수 있는지를 설정하는 파라미터 (replica.lag.time.max.ms)가 있음
팔로워가 이 설정된 시간 이상으로 리더를 따라잡지 못하면(즉, 복제를 시간 내에 제대로 못 하면) OSR이 됨
네트워크 상태가 개선되거나 팔로워 브로커의 부하가 줄어들면, OSR은 리더로부터 누락된 데이터를 다시 복제하여 ISR로 복귀가능한데, 이것을 'catching up(osr -> isr)' 이라고 하며, catching 을 하는 대신 (osr을 버리고) 완전히 새로운 레플리카를 생성하여 처음부터 모든 데이터를 복제하는 것보다 훨씬 효율적임
osr 이 얼마만큼의 데이터를 catching up 해야 isr 이 될까? 이건 replica.lag.time.max.ms, replica.lag.max.bytes 두 개의 설정값으로 결정됨
Producer 가 데이터를 저장하면, kafka broker 로부터 잘 쓰여졌는지 확인 응답acknowledgement을 받을 수 있음
acks 값에 따라 응답을 받는 정책이 결정됨
- acks = 0 : Producer 가 데이터를 쓰기만 하고, 응답은 무시함.
(Producer 가 ack 를 무시하기 때문에) 데이터가 쓰여지는데 실패한다면 곧바로 데이터 손실이 됨
- acks = 1 : Producer 가 데이터를 쓰고 leader 로부터의 응답만 받음
- acks = all (acks=-1) : Producer 가 데이터를 쓰고 leader 및 모든 isr replica 로부터 응답을 받음
(모든 replica 로부터 각각 응답을 받는게 아니라, leader 가 모든 replica 의 응답을 수집한 후 '응 다 잘 처리되었군' 하며 하나의 ack 를 producer 에게 줌)
Producer 가 보낸 데이터를 broker 가 잘 받은 후, producer 에게 ack 를 날렸는데
하필 이 ack 가 네트워크 이슈 등으로 사라짐
그럼 Producer 는 ack 를 받지 못해서 'broker 에 문제가 생겼구나' 라고 생각해서 다시 한 번 동일한 데이터를 broker 에 보냄
broker 입장에서는 동일한 데이터가 다시 들어오게 되는 것임
이 때 broker 가 '이 데이터는 중복으로 들어온거야' 라고 인식하여 실제로 topic 에 저장하진않고 ack 만 다시 보내주는 것을
"멱등Idempotent 프로듀서" 라고 함
이 기능은 Kafka 3 버전 이후 producer 에 default 로 적용되었음
kafka 2.8 이하 버전에서는 acks=all, enable.idempotence=true 을 설정해야 적용됨
acks = all 설정에서, 얼마나 많은 replica 가 만들어져야 정상 ack 를 받을까?
이건 min.insync.replicas 값으로 설정 가능함
min.insync.replicas=3 이면, leader 1개, isr 2개, 총 3개의 replica 가 생성되어야 정상 ack 를 줌
min.insync.replicas=2 이면, leader 1개, isr 1개, 총 2개의 replica 가 생성되어야 정상 ack 를 줌
broker 는 3개이고 복제계수는 3로 구성된 kafka 클러스터에서는 min.insync.replicas을 3개보다 작은 2로 설정함
만약 min.insync.replicas=3 으로 설정한 상태에서 broker 하나가 기능을 못하게되면,
(최대로 만들 수 있는 replica는 2이므로) 절대 3에 도달할 수 없음
그래서 kafka 는 정상 ack를 절대 주지 못하게 됨.
(이때는 정상 응답대신 NOT_ENOUGH_REPLICA 응답을 받게 됨)
따라서 min.insync.replicas 는 브로커 개수보다 작은 수로 설정함
(broker 3개로 구성된 클러스터에서 min.insync.replicas=2 로 설정
1개 broker 까지 고장나도 producing 하는데 문제 없음)

Zookeepr 는 kafka broker 들을 관리함. 모든 broker 리스트를 갖고 있음.
그리고 여러 replica partitions 중 어떤 것을 leader partition 으로 선출할지에 대해 관여함
Zookeeper 는 kafka에게 이벤트 알람을 주기도 함
가령 새로운 토픽이 생성되었거나, 기존 토픽이 삭제되었거나, broker 가 죽었거나, broker 가 추가되었거나.. .등의 이벤트
Kafka 2.8 이하 버전에선 Kafka 구동시 Zookeeper 가 필수였으나
Kafka 3.x 버전부터 Zookeeper 없이 Kafka 구동 가능하게 됨. 이를 "Kafka Raft(Kraft) 혹은 KIP-500" 매커니즘이라고 함
(현재) Zookeeper 의 도움을 받던 Kafka APIs, 명령어들은 모두 Kafka 로 이관되어가는 중임.
아래와 같은 단점이 있음
- Zookeeper 는 Kafka 보다 보안에 취약 (따라서 Zookeeper 는 반드시 Kafka 로부터 오는 요청만 받도록 ports 를 설정해야 함)
- partition 이 100,000개를 넘었을 때 Kafka 클러스터 스케일링에 이슈가 발생함 (Zookeeper 가 없으면 수백만개까지 확장 가능)
- Zookeeper 를 없앰으로써 유지보수, 모니터링, 스케일링 등의 장점을 얻을 수 있음
Zookeeper 를 없애고, 기존에 Zookeeper 를 통해 Kafka 를 사용하던 다른 프로그램들은 Zookeeper 대신 Kafka 에 연결하여도 기능이 동작 될 것임
Consumer 가 commit 한 offset 정보는 Zookeeper 에 보관되지 않음
Consumer 가 commit 한 offset 정보는 Kafka 의 내부 토픽(__consumer_offsets) 에 보관됨
Consumer 실행 직후 곧바로 데이터를 읽지 않음. 왜냐면 Consumer가 다른 일을 하기 때문
이를테면
- bootstrap broker 로부터 메타데이터 공유받음
- Consumer Group에 join
- Consumer Group 생성
- Consumer offset reset
- Consumer 와 Partition 매칭 (바로 아래서 설명)
등등
Consumer Group 에 Consumer 가 새로 추가 혹은 삭제된 이후(group 내 consumer 개수가 바뀌었을 때)에,
"어떤 partition 을 어떤 consumer 가 담당하여 읽을지"가 다시 결정됨
이를 재분배(rebalancing)라고 하며 kafka broker 가 진행함
이는 partition 과 consumer 의 매칭을 다시 진행하는 작업임
반대로 말하면, partition 수가 바뀌었을 때도 재분배가 일어남
재분배는 broker 중에 "coordinator broker" 라고 지정된 broker 가 진행함
coordinator broker 는 컨슈머 그룹마다 하나씩 지정되어 있음.
coordinator broker 는 파티션과 컨슈머 간 매칭(membership)을 관리함
coordinator broker 는 (자신이 맡고 있는 컨슈머 그룹 내) 컨슈머들의 장애를 (heartbeat 를 통해) 감지하고
장애가 발생하면 재분배rebalancing 를 진행함
적극적인 재분배 :
그룹 내 컨슈머 재분배가 되는 동안에는 partition 으로부터 데이터를 읽지 않음
이를 stop the world 라고 부름
재분배는 각기 다른 전략에 따라 진행됨
기존에 consumer 1 이 partition 0 을 읽고 있더라도, 재분배 후에는 그게 유지되지 않을 수 있음

적극적인 재분배 전략은 다음과 같은 것들이 있음
- RagneAssignor : 파티션을 토픽별로 순차적으로 나누어 각 컨슈머에게 할당
예를 들어, 10개의 파티션을 3개 컨슈머에 재분배하는 상황. 첫 번째 컨슈머에 파티션 0, 1, 2, 3, 두 번째 컨슈머에 4, 5, 6, 세 번째 컨슈머에 7, 8, 9 할당
일부 컨슈머에게 더 많은 파티션이 할당되어 불균형(imbalance)이 발생할 수 있음
- RoundRobinAssignor : 모든 토픽의 모든 파티션을 컨슈머 그룹 내 컨슈머들에게 파티션을 라운드 로빈(순환 방식)으로 할당
예를 들어, 토픽 A에 5개 파티션, 토픽 B에 3개 파티션이 있고, 3개의 컨슈머에 재분배하는 상황. 파티션 A-0은 컨슈머 1, A-1은 컨슈머 2, A-2는 컨슈머 3, A-3은 컨슈머 1, A-4는 컨슈머 2, B-0은 컨슈머 3, B-1은 컨슈머 1, B-2는 컨슈머 2에게 할당
파티션 할당이 비교적 최적으로 균형을 이루도록 할 수 있음
- StickyAssignor : 초기에 RoundRobinAssignor와 유사하게 파티션 할당의 균형을 맞춰 할당.
재분배가 필요한 파티션만 재분배하여, 이동(partition movements)을 최소화함
(=stop the world 를 발생시킨 후, 파티션을 최소한으로 재분배함)
기존에 컨슈머에게 할당되었던 파티션을 가능한 한 유지하여 리밸런스 시 발생하는 부하를 줄임
협력적인 재분배 :
적극적인 재분배와 다르게, 재분배가 필요한 partition 읽기만 중단함
아래 예시처럼 consumer 1, 2 가 partition 0, 1 을 중단없이 계속 읽을 수 있음(=stop the world 없음)
partition 2 는 (재분배동안) 잠시 읽기가 멈춰졌다가, 재분배 후 다시 읽힘

협력적인 재분배 전략을 CooperativeStickyAssignor 라고 부름
- CooperativeStickyAssignor : 재분배할 때 StickyAssignor와 동일하게 파티션 이동을 최소화함.
기존의 "eager" 리밸런스 방식과 달리, Cooperative Rebalance는 리밸런스 과정 동안 컨슈머가 토픽에서 계속 메시지를 소비 가능
컨슈머들이 단계적으로 리밸런스에 참여하며, 일부 컨슈머는 여전히 파티션을 소유하고 메시지를 처리함. 이를 통해 리밸런스 중에도 서비스 중단 시간을 최소화하고 가용성을 높일 수 있음
default 재분배 전략은 [RangeAssignor, CooperativeStickyAssignor] 임
초기에는 RangeAssignor를 사용하여 파티션을 할당
(컨슈머 혹은 파티션의 개수 변동으로) 재분배가 발생하면 CooperativeStickyAssignor로 파티션 할당
단일 롤링 바운스(컨슈머 그룹 내의 컨슈머들을 순차적으로 재시작하는 과정)를 통해 RangeAssignor를 리스트에서 제거하면, 이후의 리밸런스는 CooperativeStickyAssignor를 사용하게 됨
topic client 를 통해 topic 생성하는 명령어 (여기서 --bootstrap-server 는 kafka broker 서버 중 하나 이상을 넣으면 됨) ./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic new-topic --partitions 3 --replication-factor 1 |
topic 리스트 확인 명령어 ./kafka-topics.sh --bootstrap-server localhost:9092 --list |
topic 상세 정보 확인 명령어 (topic id, partition 개수, leader/replica/isr 의 broker id... 등) ./kafka-topics.sh --bootstrap-server localhost:9092 --topic new-topic --describe |
topic 삭제 명령어 ./kafka-topics.sh --bootstrap-server localhost:9092 --topic new-topic --delete |
Producer console client 를 이용하여 kafka broker 의 new-topic 토픽에 데이터 전달하는 명령어 ./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic new-topic > Hello eyeballs! > I'm sending a message. |
Producer 로 데이터 저장할 때 acks 설정 바꾸는 명령어 ./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic new-topic --producer-property acks=all |
Producer 로 데이터 저장할 때 key 를 바꾸는 명령어 ./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic new-topic --property parse.key=true --property key.separator=: > key1:Hello eyeballs! > key2:I'm sending a message. |
Producer 로 데이터 저장할 때 partitioner 를 설정하는 명령어 (아래와 같이 partitioner 가 지정되면, 파티션 선택시 메세지의 key 는 무시됨) ./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic new-topic --producer-property partitioner.class=org.apache.kafka.clients.producer.RoundRobinPartitioner partitioner 클래스 참고 : https://github.com/apache/kafka/tree/trunk/clients/src/main/java/org/apache/kafka/clients/producer 참고로 RoundRobinPartitioner 는 굉장히 비효율적이니 prod 환경에서 사용하지 말라고 함 partitioner 을 지정하지 않고 key 값도 추가하지 않으면, 기본으로 사용되는 파티셔너는 Sticky Partitioner 스티키 파티셔너는 배치 크기(batch.size, 16KB)가 채워지거나 linger.ms 시간이 초과될 때까지 특정 파티션만 사용 이렇게 함으로써 더 큰 배치를 만들어 네트워크 요청 수를 줄이고, 지연 시간을 개선하며, 처리량을 높이는 데 효과적임 시간이 지나면 스티키 파티셔너는 파티션을 변경하여 전체 파티션 간의 균형을 유지함 partitioner 을 지정하지 않았지만 key 값이 추가되면 기본으로 사용되는 파티셔너는 DefaultPartitioner (org.apache.kafka.clients.producer.internals.DefaultPartitioner) 이 파티셔너는 (이미 위에서 설명한대로) 메시지 내 키의 해시 값을 사용하여 특정 파티션을 선택함 |
Consumer console client 를 이용하여 kafka broker 의 new-topic 토픽 데이터 읽는 명령어 ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic new-topic --group new-group 참고로, new-group 이 기존에 존재하지 않는 컨슈머 그룹이라면, 위 명령어로 새로운 new-gorup 컨슈머 그룹이 생성됨 |
Consumer 로 데이터를 처음부터(가장 낮은 offset부터) 읽는 명령어 ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic new-topic --from-beginning --from-beginning 옵션은 이 옵션을 사용한 특정 컨슈머 인스턴스에게만 영향을 미침. 컨슈머 그룹의 consumer offset 가 초기화되거나 하진 않음 |
Consumer 로 데이터 읽을 때 추가 가능한 다양한 옵션들 --formatter kafka.tools.DefaultMessageFormatter : 메시지의 내용을 어떤 형식으로 출력할지를 지정 --property print.timestamp=true : 메세지 수신 시간 출력 --property print.key=true : 메세지 key 출력 --property print.value=true : 메세지 value(내용) 출력 --property print.partition=true : 메세지를 읽은 파티션 id 출력 명령어 예) ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic new-topic --formatter kafka.tools.DefaultMessageFormatter --property print.timestamp=true --property print.key=true --property print.value=true --property print.partition=true formatter 예) - kafka.tools.DefaultMessageFormatter (default) : 키와 값을 바이트 배열로 출력하거나, 텍스트로 해석 가능한 경우 텍스트로 출력 - kafka.tools.KeyMessageFormatter : 메시지의 키와 값을 함께 출력 - kafka.tools.SimpleStringFormatter : 메시지의 값 부분을 단순한 문자열로 해석하여 출력 - kafka.tools.JsonMessageFormatter : 메시지의 값 부분을 JSON 형식으로 파싱하여 보기 좋게 출력 |
consumer 실행시, --group 옵션으로 컨슈머 그룹을 설정하지 않거나, 처음 생성되는 그룹을 사용한다면 기존에 commit 된 consumer offset 이 존재하지 않기 때문에 해당 그룹에 포함된 컨슈머들은 latest offset 부터 데이터를 읽기 시작함 (기본값 latest 가 아닌 beginning 부터 데이터를 읽고 싶다면 consumer.properties 내에서 auto.offset.reset=earliest 로 설정) 물론 기존에 생성된 group을 사용하는 경우엔 해당 group 이 마지막에 사용했던 consumer offset 을 따라 데이터를 읽게됨 (여기서 auto.offset.reset=earliest 로 설정된 것은 무시됨 왜냐면 새로운 group 을 사용하는 게 아니라 이미 존재하는 group 을 사용하는 거니까) |
consumer group 리스트를 확인하는 명령어 ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list |
consumer group 정보를 확인하는 명령어 이를테면 new-group 이라는 컨슈머 그룹에 대한 정보를 알고 싶다면 ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group new-group 이 명령어를 통해, 각 partition 에 대한 consumer offset 정보, partition offset 정보, LAG, 어떤 컨슈머가 어떤 파티션을 읽고 있는지 등 확인 가능 |
consumer offset 을 reset (초기화) 하는 명령어 ./kafka-consumer-groups.sh \ --bootstrap-server localhost:9092 \ --group new-group \ --topic new-topic \ --reset-offsets --to-earliest \ --execute --execute 대신 --dry-run 을 사용하면, 실제 명령어를 실행하지 않고, '실행 후 결과는 이렇다'는 것을 대신 보여줌 reset offset 에 들어갈 수 있는 옵션들은 아래와 같음 --to-current Reset offsets to current offset. --to-datetime <String: datetime> Reset offsets to offset from datetime. Format: 'YYYY-MM-DDTHH:mm:SS.sss' --to-earliest Reset offsets to earliest offset. --to-latest Reset offsets to latest offset. --to-offset <Long: offset> Reset offsets to a specific offset. |