개인적인 포스팅입니다.
Spark 관련 기술 질문 꺼리들을 잊어버리지 않도록 여기다 적어둡니다.
2.
스파크 애플리케이션은 두 가지 프로세스로 구성 - 드라이버 프로세스 : main 함수 실행. SparkSession 이라고 불림. 애플리케이션을 제어. 하나의 애플리케이션은 하나의 SparkSession 을 갖음 스파크 애플리케이션(익스큐터 및 태스크)의 정보 유지 관리, 클러스터 매니저와 통신하여 자원 얻고 익스큐터 실행 (드라이버는 yarn 의 AM 역할), 사용자 프로그램이나 입력에 대한 응답, 실행된 코드 해석 및 물리적 실행 계획 DAG 변환, 생성된 Task들을 Executor에게 할당, 전반적인 익스큐터 프로세스의 작업과 관련된 분석, 배포 및 스케줄링 역할 - 익스큐터 프로세스 : 드라이버 프로세스가 할당한 코드 작업(태스크) 수행 작업 진행 상황을 드라이버 노드에 보고 모든 스파크 애플리케이션은 개별 익스큐터 프로세스 사용 드라이버 프로세스, 익스큐터 프로세스는 말 그대로 프로세스이기 때문에, 단일 머신 위에서 동작 가능함. 클러스터 매니저는 스파크 앱 실행에 필요한 자원을 할당 |
sparksession 이란, 데이터를 처리하는 진입점(Entry Point) 역할을 하는 객체 드라이버 프로세스 그 자체임. 하나의 spark session 이 생성되었다? -> 하나의 스파크 앱이 실행되었다고 보면 됨 sparksession 은 사용자가 작성한 Spark 코드를 해석하고 실행 계획(DAG)을 생성함 - 코드를 해석하여 논리적 실행 계획 및 물리적 실행 계획 생성 - 물리적 실행 계획이 (DAG scheduler 에 의해) stage 단위로 나뉨 - 각 stage 가 여러 task 로 나뉘고 각 executor 에 전달됨 - 각 executor 가 task 를 받아 병렬 처리함 sparksession 을 통해 df, ds, rdd, sparksql 를 처리할 수 있음 (DataFrame, Dataset, SQL API 를 처리할 수 있음) - 여기서 말하는 '처리'란, df, ds, rdd, sparksql 코드를 해석하고 실행 계획을 수립한다는 의미 sparksession 은 클러스터 매니저에게 작업을 위한 자원(executor 개수, memory 크기 등)을 요청하고 받아, 작업 실행에 사용함 - yarn 이 사용 가능한 노드에 container 를 생성하고 spark 에게 사용하라고 넘겨줌 - 이 container 에서 새로운 spark executor 가 실행됨 - sparksession 에서 dag(stage) 의 task를 새로운 executor 에게 할당 sparksession 을 통해 csv, json 등 다양한 포맷의 파일을 읽음 - '파일을 읽는다'는 의미도, 파일 읽고 코드를 해석하고 실행 계획을 수립한다는 의미임. 실질적인 읽기 작업은 각 executor 에서 진행됨 sparkcontext 는 1.0 버전에서 주로 사용되었고, 2.0 이상 버전에서는 sparksession 에 흡수됨 sparkcontext 는 rdd 를 생성하고 관리할 때 필요함. (rdd API 를 처리할 수 있음) 2.0 이상 버전부터는 sparkcontext 대신 sparksession 을 주로 사용함 |
spark 는 executor 를 어떻게 인식할까? spark 가 처음 실행되었거나, 실행 중간에 새로 생성된 executor 가 스스로 spark driver program(sparksession) 으로 연결을 시도하고 자신을 등록함 이 과정에서 Executor는 자신의 고유 ID, 호스트/포트 정보, 사용 가능한 자원(코어, 메모리) 등을 Driver에게 전달하고 driver 는 executor 를 자신의 executor 목록에 추가하여 관리하기 시작함 spark 는 executor 들의 상태를 어떻게 인식할까? 각 executor 는 주기적으로 driver 에게 (자신의 상황 정보를 담은) heart beat를 보냄 특정 executor 로부터 heart beat 를 받지 못하면 그 exeuctor 를 죽은 것으로 처리하게 될 것임 spark 는 executor 들의 상태를 어떻게 저장하고 관리할까? driver memory 위에서 Map 형태의 데이터 구조로 executor 상태 정보를 저장하고 관리함 이것을 'executor 목록'이라고 하며, executor id, executor ip & port, executor status, executor resource, executor task status & metrics 등의 정보를 담고 있음 이 정보들은 heart beat 로 꾸준히 업데이트되며, 이를 기반으로 가장 적합한 executor에게 tasks를 할당할 수 있게 됨 spark driver(sparksession) 은 spof 이며, 고가용성을 얻기 위한 전략은 어떤 것들이 있을까? spark 는 클러스터 매니저의 도움을 받아 고가용성을 갖춤 yarn 의 경우, AM(spark driver) 이 죽으면 RM 이 다른 노드에서 AM 을 재실행함 kube 의 경우, spark driver pod 가 죽으면 다시 되살림 spark streaming 은 check pointing 기능을 활용하여 (yarn 등에 의해 재실행되었을 때) 기존 상태로 복귀 가능 그럼 기존에 드라이버 메모리에 있던 데이터들은 어떻게 복구하지....? 복구 안 됨(!) 드라이버 내 메모리에 있던 데이터들은 다 날아감. 드라이버가 재실행되면, job 자체가 처음부터 다시 실행됨 이는 설계 미스가 아니라, 일부러 이렇게 만들어진 것임. 왜냐면 spark 는 short-lived process 를 추구하도록 만들어졌기 때문. 하둡처럼 오랫동안 구동되는 용도가 아니라, job 을 한 번 실행하고 끝내는 용도. |
하나의 df 에 많은 row(데이터)가 포함되어 있다면 우리가 spark shell 등에서 볼 땐 모든 데이터가 하나의 서버에 하나로 뭉쳐져있는 df 인 것 같지만 사실 이 df 의 각 row 는 (분산시스템이 적용되었다는 전제하에) 서로 다른 서버들에 분산되어 처리됨 이 row 들은 "파티션" 단위로 물리적으로 나뉘어지고, 각 서버들에 저장됨 그리고 각 서버에서 실행된 executor 노드들이 파티션을 가져가서 처리하게 됨 df 에 명령어를 실행하면, spark 가 알아서 이 파티션들을 효과적으로 처리하며 개발자인 우리가 직접 수동으로 처리하지 않아도 됨 |
모든 익스큐터가 병렬 작업할 수 있도록 파티션이라는 청크 단위로 데이터 분할 파티셔닝 : 데이터가 클러스터에서 물리적으로 분산되는 방식 파티셔닝 스키마 : 데이터를 저장할 때 사용되는 물리적인 분할 방법 예를 들어, 아래와 같이 partitioning 할 컬럼을 직접 지정하면 dir 구조로 저장됨 df.write .mode("overwrite") .partitionBy("year", "month") .parquet("s3://my-bucket/data/orders/") dir 구조 : /data/orders/year=2024/month=01/ /data/orders/year=2024/month=02/ 파티셔닝과 파티셔닝 스키마 구분 < 파티셔닝 > 목적 : Spark 내부 연산 성능 최적화(병렬 처리) 작동 방식 : 데이터를 여러 개의 논리적 블록으로 나누고 물리적으로 서로 다른 머신에 저장 후 분산 실행 적용 대상 : Spark의 RDD, DataFrame, Dataset 쿼리 최적화 : 데이터 샤딩(Sharding)과 유사, 데이터 불균형 방지 < 파티셔닝 스키마 > 목적 : 데이터 저장 구조 최적화 작동 방식 : 특정 컬럼을 기준으로 디렉토리 단위로 저장 적용 대상 : S3, HDFS, Hive 등의 저장소 쿼리 최적화 : 특정 파티션만 읽는 Partition Pruning 가능 dataframe 을 사용하여 파티션 된 데이터를 쉽게 처리 하나의 core 처리 = 하나의 파티션 = 하나의 task (in executor) = 하나의 HDFS block 하둡은 데이터를 읽을 때 설정된 InputSplit 분할 정책에 따라 데이터를 분할하고 이 분할 정책에 따라 나눠진 데이터가 Spark 의 파티션 단위가 됨 HDFS 데이터 읽을 때 rdd 로 읽으면 HDFS 블럭 하나 당 파티션 하나 (파티션 한 개 = 128mb 블럭 한 개) 통상적으로는 Partition의 크기가 클수록 메모리가 더 필요하고, Partition의 수가 많을수록 Core가 더 필요 파티션 수가 많으면 메모리 부담이 적어지고 병렬성이 올라감 Spark 내에서 데이터를 처리할 때, repartition 혹은 coalesce 로 파티션 개수 설정 가능 Input Partition : 처음 파일 읽을 때 생성하는 Partition 기본값 128mb HDFS 파일 크기가 128MB보다 크다면, Spark에서 128MB만큼 쪼개면서 파일 읽음 파일의 크기가 128MB보다 작다면, 작은 크기 그대로 읽음 읽은 파일 하나당 Partition 하나 대부분의 경우, 필요한 칼럼만 골라서 뽑아 쓰기 때문에 파일이 128MB보다 작음 Output Partition : 파일을 저장할 때 생성하는 Partition 기본값 64mb이나, 대개 기본 블록 사이즈로 세팅 Shuffle Partition : 셔플 진행 후 생성되는 Partition 기본개수 200개 Shuffle Partition 하나 크기가 100~200MB 정도 나올 수 있도록 개수 조절하는 것이 좋음 Partition의 크기가 크고 연산에 쓰이는 메모리가 부족하다면 Shuffle Spill(셔플에 필요한 메모리가 부족해서 (데이터직렬화 후 IO 하여) 디스크를 대신 사용)이 일어날 수 있음 (shuffle spill 이 발생하면 성능에 굉장한 악영향이겠군) 참고 https://tech.kakao.com/2021/10/08/spark-shuffle-partition/ 200개 정도의 파티션(=200개 태스크)은 대부분의 Spark Job에서 허용 가능한 수준의 오버헤드임 기본값 200은 병렬성 극대화, Executor OOM 방지라는 장점을 고려한 것 |
< shuffle 이 비싼 연산인 이유 > - shuffle parittion 이 Disk 에 저장되므로 Disk IO 가 발생함 - 네트워크를 통해 데이터 교환해야 하므로, 네트워크 IO, 그리고 serialization/deserialization 비용이 발생함 - shuffle 끝날 때 까지 다음 stage 기다려야 하므로 시간적 비용 발생함. 만약 skew 가 생긴다면 더 길어지겠지... |
< Shuffle 이후 skew 가 발생하는 이유 > 예를 들어, 다음과 같이 'country' 를 기준으로 groupby 하는 경우 - df.groupBy("country").count() 'country' 값을 hashing 한 값 기준으로 shuffle partition 나머지를 계산하여 partitioning 을 진행 - partition_id = hash(country) % shuffle_partitions 만약 "KR" 가 100만개, 나머지 국가가 1만개라면, "KR" 에 속하는 모든 데이터들이 하나의 partition_id 를 갖고 하나의 파티션으로 몰려들게 되며 (왜냐면 같은 key를 갖는 데이터는 같은 파티션에 들어가게 되니까) 이 "KR" 파티션 하나 처리하는 데 엄청 오래 걸릴 것임 이렇게 skew 가 발생함 이 경우, shuffle partition 개수를 늘린다고 해서 skew 가 예방되지 않음 따라서, salting, broadcast join(shuffle 자체를 막음), AQE(큰 파티션 강제로 split) 하는 방법을 통해 skew 를 예방함 만약 key 를 쪼갤 수 없는 상황이라면? 예를 들어, 국가별로 사용자들 이름을 정렬하는 상황이라면? - 같은 key의 모든 데이터는 반드시 하나의 노드(파티션)에 있어야 함 - salting 불가, AQE split 불가 이 경우, skew 를 만드는 key 를 갖는 데이터를 따로 처리하도록 하여 다른 데이터 처리에 영향이 없도록 함 예를 들어 - val skewed = df.filter(col("country") === "KR") val normal = df.filter(col("country") =!= "KR") 혹은, 단계를 분리할 수 있음 예를 들어, 국가별로 그룹짓는 처리를 job1 에서 하고 job1의 데이터 기반으로 정렬하는 처리를 job2 에서 하는 식 혹은, pre-aggregated, pre-sorted data 를 활용하거나 top-N 개만 정렬하여 full sorting 을 피하는 방식도 있음 skew 가 발생하면, task 한두개가 비정상적으로 오래 실행되기 떄문에 Spark WebUI 의 Tasks tab 에서 확인 가능 input 자체에서 너무 큰 데이터가 들어와서 skew 가 발생하기도 함 그래서 input size 가 압도적으로 큰 부분이 보인다면 skew 의심할 수 있음 |
< join 및 shuffle 이 진행되는 구체적인 과정 > tableA, tableB 를 서로 join 하는 상황 (기본 join 전략인 shuffle join 진행) tableA , tableB 는 여러 파티션으로 나뉘어져서 다뤄질꺼야. 각각 3개씩 총 6개 파티션이라고 가정하자. 이 여러 파티션들은 어떤 executor 메모리에 올라가는지 알 수 없어(tableA, tableB 상관 없이) task 하나는 partition 하나를 처리하기 때문에, 총 6개의 task 가 실행될거야. task 는 join 을 실행할 예정이기 때문에, task 가 처리하는 partition 내에서 join key 기준으로 hash(join key) % number of shuffle partition(default 200) 처리를 진행하여 같은 키 값을 갖는 데이터들로 나누고, executor 의 로컬 디스크에 저장해 결과적으로 number of shuffle partition 개수만큼의 파일이 executor 의 로컬디스크에 저장될꺼야 각 executor 의 로컬디스크에서 같은 join key 를 갖는 shuffle partition 의 데이터를, 네트워크를 통해 하나의 executor 로 모아. 그러면 tableA, B 의 같은 join key 를 갖는 데이터들이 하나의 executor 에 모여있게 될꺼야. 그 후 executor 내에서 local join 을 진행하는거지. 여기서 broadcast join 및 buckeing 이 추가되는 상황을 상상해보자. 먼저 broadcast join. tableB 가 dimension table 이라서 크기가 (executor memory 에 들어갈만큼) 작다는 전제. 이 tableB 가 모든 executor memory 에 복사된다면 (executor 마다 한 번 복사됨) 각 executor 가 갖는 tableA 의 파티션과 바로 local join 이 가능하게 됨 (굳이 tableA, tableB 의 같은 key 값을 모아서 하나의 executor 로 뭉치는 작업을 하지 않아도 됨=shuffle 을 하지 않아도 됨) broadcast join 진행하면 memory 를 아주 많이 사용하기 때문에 OOM 혹은 disk spill 발생 가능성을 염두해둬야 함 그리고 bucketing. bucketing 을 통해, tableA, tableB 의 데이터를, 같은 hash function 을 사용하고, 같은 개수만큼 나눠서 disk 에 저장했다고 하자 이렇게 되면, disk 에는 '같은 key 를 갖는 데이터들은 동일한 bucket 에 존재'하게 됨 이제 task 에서 tableA, tableB 를 join 하려고 disk 에서 데이터를 읽어오면 같은 key 값을 갖는 데이터들을 bucket 단위로 가져올 수 있고 그 상태 그대로, 곧바로 local join 이 가능하게 됨(=shuffle 생략) bucketing 의 단점은, 개수를 늘릴 수 없다는 것(=개수 고정), 그리고 table A, B 둘다 동일한 key 기준으로, 또 동일한 개수로 bucketing 이 되어있어야 한다는 것 user_id 로 bucketing 해두었는데 나중에 join 할 때 join key 가 order_id 라면 bucketing 의 이득을 전혀 볼 수 없게 됨(=shuffle 발생) bucketing 은, shuffle의 "같은 key 로 모아두기" 부분을 미리 진행해두고 disk 에 저장해두는 것 따라서 bucketing 실행 자체에서 shuffle 을 유발함 (query time 에 발생하는 셔플을 write time 으로 옮기는 것) |
< 파티션 개수가 적을 때 장점 > - 낮은 관리 오버헤드: Spark Driver가 관리해야 할 태스크(Task)와 파티션 메타데이터의 수가 적으므로, Driver의 부담이 줄어들고 스케줄링 오버헤드가 감소 - 셔플 파일 오버헤드 감소: 셔플 작업 시 생성되는 파일의 수가 줄어들어, 파일 관리와 관련된 오버헤드가 감소. < 파티션 개수가 적을 때 단점 > - 클러스터 자원 활용 저하 (Underutilization): 파티션 수가 클러스터의 총 코어 수보다 적으면, 일부 코어는 유휴 상태로 남아 클러스터의 병렬 처리 능력을 충분히 활용하지 못함 - 긴 태스크 실행 시간: 각 파티션이 처리해야 할 데이터 양이 많아지므로, 개별 태스크의 실행 시간이 길어짐(병렬성 하락) - 메모리 부족(OOM) 가능성 증가: 하나의 파티션이 너무 커서 Executor의 메모리 용량을 초과할 경우, OutOfMemoryError가 발생할 가능성이 높아짐 - 느린 장애 복구: 태스크가 실패하면 해당 파티션 전체를 재실행해야 하므로, 파티션 크기가 클수록 복구 시간이 오래 걸림 < 파티션 개수가 많을 때 장점 > - 높은 병렬 처리: 파티션 수가 많으면 더 많은 태스크가 동시에 실행될 수 있어 클러스터의 모든 코어를 효율적으로 활용하고 병렬 처리 수준이 높아짐 - 빠른 장애 복구: 각 태스크가 처리하는 데이터 양이 적으므로, 태스크 실패 시 재실행 비용이 낮고 복구 시간이 짧음 - Executor OOM 가능성 감소: 각 파티션의 크기가 작아지므로, Executor 하나의 메모리로도 충분히 처리 가능하여 OOM 발생 가능성이 낮아짐 < 파티션 개수가 많을 때 단점 > - 높은 관리 오버헤드: Driver가 스케줄링하고 모니터링해야 할 태스크의 수가 기하급수적으로 늘어나 Driver에 과부하를 줄 수 있음 이는 Driver의 GC 오버헤드 증가나 네트워크 혼잡으로 이어질 수 있음 - 셔플 오버헤드 증가: 셔플 시 생성되는 파일 수가 많아지고, 이 파일들을 관리하는 메타데이터 오버헤드가 커짐 - 비효율적인 I/O: 각 태스크가 처리하는 데이터 양이 너무 적으면, 파일 열고 닫는 IO 오버헤드나 네트워크 통신 오버헤드가 실제 데이터 처리 시간보다 더 커질 수 있음 - 메모리 사용량 증가: 각 태스크 객체, 중간 상태, 내부 데이터 구조 등 메타정보를 위한 메모리 사용량이 전체적으로 늘어날 수 있음 |
< Spark driver 가 HDFS 로부터 데이터를 읽을 때 > Spark driver 는 HDFS 로부터 읽은 데이터들(여러 블록들)을 처리할 Task 를 생성하고 Executors 에게 이 Task 를 처리하도록 스케줄링함. 각 Task는 자신이 처리해야 할 파티션에 해당하는 HDFS 블록의 특정 위치를 알고 있음 Executor는 자신이 처리할 HDFS 블록을 직접 HDFS로부터 읽어와서 처리함 Spark은 데이터를 처리할 Task를 해당 데이터가 있는 노드 (DataNode)의 Executor에게 우선적으로 할당하려고 시도함(네트워크 비용 최소화를 위해) 이게 바로 데이터 지역성 Executor는 Task가 할당받은 파티션의 데이터를 (파티션 크기와 상관 없이) 'iterator 기반의 스트리밍 방식'으로 조금씩 읽어옴 Executor 가 데이터의 32mb(이걸 청크라고 부름) 를 조금 읽어옴 -> 필요한 연산 수행 -> 읽은 청크를 메모리에서 해제 -> Executor 가 데이터의 32mb 청크를 추가로 읽어옴 -> 필요한 연산 수행 -> 읽은 청크를 메모리에서 해제 -> .... 128mb모두 읽고 처리함 -> 읽기 및 연산 작업 끝! (물론 앞서 읽어온 청크를 유지해야 한다면 메모리에 유지함) spark 는 데이터를 작은 청크 기준으로 읽기 때문에, HDFS 에서 읽은 데이터가 executor 메모리보다 더 큰 상황(예를 들어 executor 메모리 64mb, HDFS 블록 크기 128mb 읽을 때)에서 데이터 읽기 작업 중 Disk spill 이나 OOM을 일으키지 않음 - Spark 청크 : Executor가 하나의 Spark 파티션을 처리하기 위해 메모리에 일부분씩 나누어 읽어오는 작은 데이터 조각. 파티션 전체를 한 번에 메모리에 로드할 수 없을 때, 데이터를 여러 번에 걸쳐 조금씩 읽어 처리하기 위해 사용 - Spark 파티션 : Spark이 데이터를 병렬로 처리하기 위해 논리적으로 나눈 데이터의 덩어리. |
HDFS 에 130MB 텍스트 파일을 저장한 두 개의 블록(128mb, 2mb)을 Spark 가 읽고 처리할 때 데이터의 중간이 끊겨있으면 어떻게 처리하게 될까? HDFS 저장: 블록 1: 128MB 블록 2: 2MB (남은 부분) Spark 에서 spark.read.text() 등으로 읽으면 두 개의 Spark 파티션을 생성 파티션 1 (Task 1): 블록 1 (128MB)을 담당. 파티션 2 (Task 2): 블록 2 (2MB)를 담당. Task 1은 128MB 블록을 처리하기 위해 LineRecordReader를 사용함 만약 128MB 지점에서 라인이 끊겨 있다면, LineRecordReader는 블록 2 시작 부분의 몇 바이트를 더 읽어서 그 라인을 완성 (만약 블록2가 Task1 과 다른 서버에 존재한다면, Task1 이 블록2의 몇 바이트를 읽는 과정에서 네트워크 비용이 소모될 수 있음) 예를 들어 128MB + 50바이트를 읽어서 첫 번째 라인을 완성함 그 후 Task 1은 자신이 읽은 모든 완전한 라인들을 처리하게 됨 Task 2도 2MB 블록을 처리하기 위해 LineRecordReader를 사용함 이 LineRecordReader는 Task 1이 이미 블록 2의 시작 부분(앞선 라인의 나머지 부분)을 읽었다는 것을 "알고" 있음 따라서 Task 2의 LineRecordReader는 자신의 InputSplit의 첫 번째 완전한 라인부터 읽기 시작함 (=Task 1이 읽었던 50바이트는 건너뛰고, 그 이후의 첫 번째 줄 바꿈 문자(\n)부터 새로운 라인을 시작하여 읽음) 결과적으로 Task 2는 블록 2의 나머지 데이터를 (Task 1이 읽은 겹치는 부분을 제외하고) 온전히 처리하게 됨 위와 같은 방식으로 동작하기 때문에 텍스트가 중간에 끊어진 blocks 를 읽어도 (중복 처리, 데이터 누락 등의) 이슈가 없음 |
| 추가적으로, 특정 파티션을 처리하는 과정에서 Executor의 메모리가 부족해지면 (예: 대규모 Shuffle 연산, 메모리 기반 집계, 메모리에 데이터를 모두 올리고 수행하는 작업(예를 들면 groupByKey) 등) Spark은 Disk Spill 을 통해, 메모리에서 사용하지 않는 데이터를 디스크에 임시로 저장함 디스크에 저장한 데이터가 다시 필요해지면 디스크에서 메모리로 읽어와 처리 진행 Disk Spill은 성능 저하를 유발함 만약 개별 파티션의 크기가 Executor 메모리보다 훨씬 크거나, cache(), persist() 명령어로 너무 큰 데이터를 메모리에 저장(캐싱)하는데 Executor 메모리가 부족하게 되는 등, 메모리 부족 상황에서 Disk Spill이 불가능한 연산 (매우 큰 파티션을 메모리에 모두 올려야 하는 경우 등)을 수행시 OOM 오류가 발생하여 작업이 실패할 수 있음 |
< Spark 에서 HDFS 에 데이터를 쓸 때 > Executor들이 생성한 파티션의 내용을 HDFS 블록 단위로 기록하는 방식으로 진행됨 각 Executor는 자신이 처리한 결과 데이터를 메모리 내의 파티션 형태로 가지고 있지. saveAsTextFile(), write.parquet(), write.orc() 등의 쓰기 액션이 호출되면 드라이버는 쓰기 작업을 위한 Task들을 생성하여 Executor에게 스케줄링 함 각 Task를 할당받은 Executor는 자신의 메모리 내 파티션 데이터를 HDFS 클라이언트 라이브러리를 사용하여 HDFS의 DataNode에 기록 여러 Executor가 주체적으로 병렬로 HDFS에 쓰기 작업 수행함 데이터를 쓸 때 (Executor 내에서 실행된) HDFS 클라이언트는 데이터를 (기본 블록 크기인) 128MB 단위로 나누어 여러 개의 HDFS 블록을 생성하고, 각 블록을 어떤 DataNode에 기록할지 NameNode와 통신하여 결정한 후 저장 일반적으로는 파티션 크기에 따라 HDFS 블록이 생성됨. 하지만 파티션 크기가 HDFS 블록 크기보다 큰 경우, Executor의 메모리 내 파티션 하나가 HDFS에 여러 개의 블록으로 나뉘어 저장될 수 있음 반대로, 여러 개의 작은 파티션의 내용이 하나의 HDFS 블록에 이어져서 저장될 수도 있음 repartition(1) 그리고 coalesce(1)은 executor 하나의 메모리 위에 모든 파티션을 몰아주는 명령어임 따라서 모든 데이터(모든 파티션) 이 하나의 executor 메모리에 올라가게 되는데 해당 Executor의 가용 메모리를 초과하면, 메모리 부족으로 인해 disk spill (혹은 OOM)이 발생 disk spill 이 발생한 상태에서 HDFS 에 데이터를 쓰게 되면? 해당 Executor의 메모리에 있는 데이터부터 순차적으로 HDFS에 쓰고, 다 쓰고나면 disk 에 spill 되어있는 데이터를 메모리로 불러와서(스트리밍 방식으로) 이어서 HDFS에 씀 (HDFS에 데이터를 쓰는 작업은 스트리밍(append-only) 방식으로 진행됨) (Executor 내의)HDFS 클라이언트는 데이터를 128MB 블록 단위로 나누어 DataNode에 계속해서 전송함 참고로 HDFS 에 저장된 데이터는 업데이트는 불가능하지만 append 는 가능함 그래서 append 기능을 통해 스트리밍 쓰기가 가능한 것임 |
dataframe 이 한 번 생성되면 변경할 수 없는 불변성을 갖음 변경하려면, 기존의 dataframe 에서 변경(transformation)된 것을 적용한 새로운 dataframe 을 생성해야 함 즉, 기존 df 기반으로 새로운 df 를 만들려면, 기존 df 를 트랜스포메이션하여 새로운 df 를 만들어야 함! 좁은 트랜스포메이션 (with narrow dependency) - 각 입력 파티션이 하나의 출력 파티션에만 영향 - 즉, (다른 파티션과의 협력 없이) 각 파티션 자체적으로 수행 가능한 작업들 - filter, where, select, map 등 - 메모리에서 작업이 일어남 넓은 트랜스포메이션 (with wide dependency) - 각 입력 파티션이 여러 출력 파티션에 영향 - group by, join, sort 등 - 파이프라이닝을 통해 노드간 데이터 셔플이 일어남 - 중간 결과를 디스크에 저장 - stage 를 만드는 기준이 됨. 즉, 넓은 트랜스포메이션이 발생함 -> stage 가 생성됨 일련의 트랜스포메이션은 하나의 dag 명령을 만듦 트랜스포메이션이 발생한다? -> dag 의 단계가 생성된다 -> dag(트랜스포메이션)가 실행된 후 불변의 df 가 생성된다 -> 각 dag(트랜스포메이션) 단계 실행 될 때 마다 df 가 생성된다 각 stage 에서 처리하는 데이터의 파티션 개수에 따라 tasks 수가 정해짐 예를 들어 어떤 stage 에서 5개짜리 partitions 를 갖는 데이터를 처리하면 task 는 5개가 생성됨 하나의 task 가 하나의 partition 을 처리하기 때문 |
지연 연산 : action 이 일어나기 전까지 연산을 기다리는 동작 왜 기다릴까? action 이 일어나기 전 모든 연산을 최적화하기 위해서. 조건절 푸시다운 : 조건을 데이터 소스에 위임 예를 들어, RDB 에서 전체 데이터를 읽고 하나의 로우만 갖고 오는 작업 진행시, 스파크는 하나의 로우만 갖고오도록 RDB 에 where 조건 처리를 위임하여 RDB 에서 하나의 로우만 갖고옴 액션 - 일련의 트랜스포메이션으로부터 결과를 계산하는 명령어 - count, show 등 - 액션이 일어나면 spark job 이 실행됨 |
spark webui 는 port 4040 으로 접근 spark job 의 진행 상황을 모니터링 할 때 사용함 pyspark shell 을 실행한 이후에 localhost:4040 으로 접근해서 webui 콘솔을 열어볼 수 있었음 |
spark 가 csv 등의 데이터를 읽을 때 schema inference 기능을 사용할 수 있기는 함.. (스키마 추론을 위해 spark 는 csv 데이터를 조금 읽어 분석한다고 함) 이렇게 데이터를 읽고 분석한 뒤 데이터의 schema 를 얻는 것(추론하는 것)을 schema-on-read 라고 함 (schema-on-read 는 spark 에서만 사용되는 개념이 아니라 다양한 곳에서 적용되는 개념) df = spark.read.option("inferSchema", "true").csv(path) 하지만 이 방식을 실제 운영에서는 사용하면 안 됨 운영에선 스키마를 엄격하게 직접 지정해서 넣어줘야 함 |
>>> df.sort("rollno").explain() == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- Sort [rollno#34 ASC NULLS FIRST], true, 0 +- Exchange rangepartitioning(rollno#34 ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=76] +- Scan ExistingRDD[address#30,age#31L,height#32,name#33,rollno#34,weight#35L] 위에서 "rollno" 컬럼을 기준으로 sort 명령어를 진행할 시 shuffle(exchange) 이 실행된 것을 볼 수 있음 - exchange : 데이터를 다시 파티셔닝(repartitioning) 할 때 등장하는 연산자. 여기서는 셔플파티션(200개)으로 재 파티셔닝 함 - rangepartitioning : 정렬 기반 파티셔닝(Sort-Based Partitioning)을 의미함 - rollno#34 ASC NULLS FIRST, 200 : 데이터가 rollno 컬럼을 기준으로 오름차순(ASC) 정렬되며 NULL 값이 우선 배치. 200은 생성되는 파티션 개수 - plan_id=76 : 내부적으로 Spark의 실행 계획에서 특정 노드의 ID를 나타냄. 디버깅할 때 유용한 정보 위와 같이, 내가 실행할 명령어들이 어떤 계획에 의해 처리되는지 explain 으로 미리 확인 가능함 또한, 셔플이 발생한 후 그 결과로 생성된 df 는 (기본값으로) 200개의 작은 파티션들을 갖는 df 가 됨 이를 셔플 파티션이라고 부름 |
셔플 파티션 : sort, join, 넓은 트랜스포메이션 등에 의해 셔플 후 생성되는 파티션의 기본값은 200 수정하려면 spark.conf.set("spark.sql.shuffle.partitions", "5") 참고로 spark.default.parallelism 도 동일한 의미는 갖는데, spark.default.parallelism는 rdd 에만 적용되고 df 에는 적용되지 않음 spark.sql.shuffle.partitions 는 df 에도 적용됨 계보 : 일련의 논리적 실행 계획 계보를 통해 첫 입력 데이터를 시작으로 그 동안 수행되어온 연산을 전체 파티션에서 어떻게 재연산하는지 알 수 있음 DAG 가 계보(lineage) 라고 보면 됨 (넓은 트랜스포메이션이나 cache, persist 등에 의해) 다루던 데이터가 메모리나 디스크에 저장되면 (데이터를 잃어버려도) 디스크에 저장된 곳부터 다시 실행(재연산)이 가능하게 됨 |
최적의 익스큐터 개수 계산 다수의 작은 executor 문제 - 하나의 파티션을 처리할 자원이 불충분 할 수 있음 - 셔플, skewed 데이터의 캐시, 복잡한 연산의 transformation 수행 시 OOM 또는 disk spill이 생길 수 있음 - 같은 노드내 executor 끼리 통신하는데 드는 비용 낭비 소수의 큰 executor 문제 - 너무 큰 executor 는 힙 사이즈가 클 수록 GC가 시작되는 시점을 지연시켜 Full GC로 인한 지연이 더욱 길어질 수 있음 executor 당 메모리는 최소 4GB 이상, CPU 는 최대 5개 최적의 파티션 개수, 크기 계산 공식이 따로 없고 각 환경에서 최적의 값을 직접 찾아야 함 최소한 Executor 개수 x Core 개수 이상으로 설정해야 함 (병렬성을 맞추는 최소 값) 일반적으로 파티션의 개수를 늘리는 것은 (오버헤드가 너무 많아지는 수준이 되기 전까지는) 성능을 높여줌 CPU가 놀지 않도록 최소한 총 코어 개수 이상의 파티션을 사용 파티션 개수를 늘리면 각 Executor에서 스파크가 한 번에 처리하는 양이 적어지므로 메모리 부족 오류를 줄이는데 도움 파티션이 부족한 것보다는 차라리 조금 더 많은 것이 나음 MapReduce는 각 task의 스타트업 오버헤드가 큰 반면 스파크는 그렇지 않음 반대로, 파티션이 너무 많아도 문제가 됨 스파크 드라이버가 모든 파티션의 메타데이터를 보관 Driver memory errors & Driver overhead errors를 유발 가능 모든 파티션을 Scheduling 하는 오버헤드 작은 사이즈의 파일들을 생성하기 위한 I/O가 많이 발생(block store에서) 스파크 메모리 설명 |
pyspark 도 jvm 위에서 동작할까? 맞음 pyspark 가 python script 를 실행하면, python process 에서 SparkSession 을 생성(build)하고 SparkSession 이 내부적으로 JVM 을 실행함 Python 과 JVM 사이 양방향 데이터 교환을 위해 Py4J(Python for Java) lib 를 사용함 Py4J 덕분에, Python 에서 호출한 Spark API 들이 Java Spark API 로 변환됨 Python 의 DataFrame API 는 내부적으로 JVM 의 DataDrame 객체를 래핑한 것임 PySpark 는 Driver 에서 Python 코드를 실행하고, 실제 데이터 처리는 Executor(JVM) 에서 진행됨 Spark Driver 와 각 Executor 는 독립적인 JVM 프로세스 안에서 구동됨 Driver, Executor 를 하나의 JVM 프로세스 라고 생각해도 됨 (따라서, driver, executor 대상으로 JVM 기능 (이를테면 thread dump) 사용 가능) python 코드가 어떻게 Java Spark API 로 변환되는지 예를 들어봄 아래와 같은 python 코드를 실행한다고 하자 df = spark.read.csv("data.csv") df.select("column1").show() spark.read.csv 가 실행되면, Py4J 를 통해 JVM 의 Spark 로 전달됨 그리고 전달받은 것을 토대로 JVM 의 DataFrameReader 가 csv 를 읽음 df.select 가 실행되면 똑같이 Py4J 를 통해 JVM 의 Spark 에 전달되고 전달받은 것을 토대로 JVM 에서 SparkSQL 이 실행됨 show 가 실행되면, (Py4J를 통해) jvm 의 DataFrame 이 변환된 후, Python 으로 결과가 전달됨 결과적으로 pyspark 를 사용해도 실질적인 실행은 모두 JVM 내 driver, executor 가 담당함 하지만 PythonUDF 는 JVM 에서 연산되지 않음 UDF 는 별도의 python process 를 실행하고 그 위에서 실행됨 python driver 가 작업을 시작한다 -> worker node 위에 JVM 이 실행되고, JVM 안에서 executor 가 실행된다 -> executor가 실행되는 도중에 UDF 를 만난다 -> UDF 를 처리할 새로운 python process 가 (JVM 바깥, worker node 위에) 생성된다 -> executor 와 python process 사이에 데이터를 주고받음. (executor 가 python process 에게 처리에 필요한) 데이터를 주고 (python process 가 처리한 결과를 executor 가) 받는다 -> 결과를 executor 가 다시 받고, 다음 작업을 진행한다 이렇게 UDF 를 사용하면, 데이터를 주고받는 스텝이 하나 더 생김 JVM 과 python process 사이에 데이터를 주고받을 때 직렬화/역직렬화를 해야하는 오버헤드가 발생 그래서, udf 를 사용하려면 같은 JVM 언어인 scala 등을 사용하거나, python udf 로 로직을 구축하는 대신 spark API 를 사용하여 로직을 구축 |
3.
spark-submit 으로 스파크 애플리케이션 코드 실행이 가능하며, 한 번 제출하면 작업을 일부러 취소하거나 자연 종료되거나, 에러가 발생 할 때까지 계속 실행됨 spark-submit 으로 실행시 애플리케이션 실행에 필요한 자원과 실행 방식, 옵션 등을 지정 가능 - scala 언어) spark-submit --class com.tistory.eyeballs.SparkJob --master local ./my/spark/jar/spark-jar.jar - python 언어) spark-submit --master local ./my/pyspark/script/script.py < --master (클러스터 관리자 설정) > --master 옵션은 Spark 애플리케이션을 실행할 환경을 지정하는 옵션 사용 가능한 값: - local: 로컬 머신에서 실행(standalone 모드) (ex: --master local, --master local[4]) 여기서 4 는 cpu 개수를 의미함 driver 와 executors 가 하나의 머신 위 하나의 JVM 에서 동작함. [4] 에서 4는 Spark Driver와 Executor가 사용할 JVM의 CPU 코어(스레드)의 개수 - yarn: Hadoop YARN 클러스터에서 실행 (ex: --master yarn) - mesos: Apache Mesos 클러스터에서 실행 (ex: --master mesos://HOST:PORT) - k8s: Kubernetes에서 실행 (ex: --master k8s://https://kubernetes-api-server) spark://HOST:PORT: Spark 실행 < --deploy-mode (배포 모드) > 스파크 드라이버를 어디서 실행할지 지정 - client: 사용자가 spark-submit을 실행하는 머신에서 드라이버 실행 - cluster: 클러스터 내부의 노드에서 드라이버 실행 (YARN, Standalone, Mesos에서 가능) < --executor-memory (Executor 메모리 할당) > 각 Executor에게 할당할 메모리 크기 설정 (ex: --executor-memory 4G) < --executor-cores (Executor CPU 코어 수) > Executor가 사용할 CPU 코어 수 지정 (ex: --executor-cores 2) < --num-executors (Executor 개수 설정) > 실행할 Executor 개수 지정 (ex: --num-executors 10, YARN 클러스터에서만 사용 가능) < --driver-memory (Driver 메모리 설정) > 드라이버 프로그램이 사용할 메모리 크기 설정 (ex: --driver-memory 2G) < --driver-cores (Driver CPU 코어 수) > 드라이버가 사용할 CPU 코어 개수 지정 (YARN 클러스터에서 사용 가능) < --conf (추가 Spark 설정) > Spark 애플리케이션 실행 시 추가 설정 적용 (ex: --conf spark.executor.extraJavaOptions="-XX:+PrintGCDetails") < --jars (추가 JAR 파일 포함) > Spark 애플리케이션이 의존하는 JAR 파일 추가 (ex: --jars my-library.jar) < --py-files (추가 Python 파일 포함) > PySpark 실행 시 추가 Python 파일 포함 (ex: --py-files my_script.py) < --properties-file (설정 파일 로드) > Spark 설정을 포함한 properties 파일을 지정 (ex: --properties-file spark-defaults.conf) |
DataSet 은 JVM 에서 사용하는 정적 타입 코드를 지원하기 위해 생성된 Spark 의 구조적 API 임 (동적 타입 언어인 python 에서는 사용 불가) 내부적으로 Spark 자체 데이터타입(Row)을 갖는 Dataframe 과 다르게, DS 는 사용자가 설정해 준 타입을 이용하여 데이터를 처리함 DS 의 역할은 타입 안정성을 제공하는 것임 타입 안정성(type safety)을 제공한다? -> 컴파일 시점에서 데이터의 타입을 보장하여 런타임 오류를 방지할 수 있다 (df 의 경우 타입 mismatch 가 발생하면 런타임에 오류가 발생함) 복잡한 데이터 변환 작업 등에서, 우리가 의도한 타입으로 처리되어야 한다면 DS 를 사용하여 컴파일 타임에 이슈 미리 확인 가능! 또, DS 에서 take 나 collect 를 사용하면, DS 에 매개변수로 지정한 타입의 객체가 반환됨! 예를 들어, 숫자로 구성된 DS 를 만들고 take 해보면, Long 이 나옴 scala> val ds = spark.range(1,10) ds: org.apache.spark.sql.Dataset[Long] = [id: bigint] scala> ds.take(1) res3: Array[Long] = Array(1) scala> ds.collect() res4: Array[Long] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) 근데 이걸 DF 로 바꿔서 take 해보면, Row 가 나옴 scala> val df = ds.toDF df: org.apache.spark.sql.DataFrame = [id: bigint] scala> df.take(1) res5: Array[org.apache.spark.sql.Row] = Array([1]) |
스파크의 거의 모든 기능은 RDD 를 기반으로 만들어짐 DF 도 RDD 로 만들어짐.. 우리가 RDD 를 사용해야 할 때는? 세밀한 데이터 제어가 필요할 때 (파티션 단위) 1. 원시 데이터(비정형 데이터. 이를테면 JSON, 로그 파일 등)를 읽고 자유롭게(구체적으로) 다룰 때 예를 들어, log 파일을 불러와서 word count 예제를 실행할 때 rdd 를 사용할 수 있음 val spark = SparkSession.builder().appName("RDD Example").getOrCreate() val sc = spark.sparkContext val rdd = sc.textFile("hdfs://path/to/textfile") val wordCounts = rdd.flatMap(_.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) wordCounts.collect().foreach(println) // 결과 출력 RDD 로 비정형 데이터 다룬다고, df 가 비정형 데이터를 다루지 못한다는 말은 아님 df 도 비정형 데이터 다룰 수 있지만, rdd 보다 추가적인 변환 과정이 들어가게 됨 2. 파티션같은 물리적 실행 특성을 컨트롤해야 할 때 val rdd = sc.parallelize(Seq((1, "A"), (2, "B"), (3, "C")), numSlices = 2) // 키를 기준으로 해시 파티셔닝 적용 val partitionedRdd = rdd.partitionBy(new HashPartitioner(3)) println(partitionedRdd.partitions.length) // 3개의 파티션 생성 3. DF 로 처리하기 힘든 연산을 실행해야 하는 경우 DF 가 모든 연산 처리를 할 수 있는 건 아니라고 함(!) 직접 만든 복잡한 연산을 실행할 때 rdd 를 사용함 RDD는 map(), filter(), reduce() 등의 다양한 연산 제공하기 때문에 사용자 정의 연산 실행이 가능 val rdd = sc.parallelize(Seq(1, 2, 3, 4, 5)) // 각 요소를 제곱하고 합산하는 사용자 정의 연산. 이걸 DF 가 못 한다고..? val squaredSum = rdd.map(x => x * x).reduce(_ + _) println(squaredSum) // 55 하지만 우리가 rdd 대신 df 를 사용하는 이유는, df 같은 고수준API 가 갖는 최적화 기술(Catalyst 옵티마이저)이 있고 rdd 를 사용하면 사용자가 직접 최적화를 해야하기 때문.. |
4.
구조적 API 는 정형, 반정형, 비정형 데이터 모두 처리 가능 df, ds 는 분산 테이블 형태의 컬렉션 카탈리스트 엔진 - 스파크 자체 데이터 타입 정보를 갖음 - 다양한 실행 최적화 기능 제공 DataFrame - 스키마 데이터 타입 일치 여부 런타임에서 확인 - Row 타입을 갖는 DataSet - Row 타입은 스파크가 사용하는 연산에 최적화된 인메모리 포맷 - DataSet - 스키마 데이터 타입 일치 여부 컴파일 타임에서 확인 - 사용 언어가 갖는 데이터 타입을 사용 - 타입 안정성을 지원 |
Row 타입을 사용하는 것이 왜 좋을까? 사실 'Row 타입 사용' 이 좋은 게 아니라, 'UnsafeRow 포맷을 사용하는 DF, SparkSQL을 사용' 이 좋은 것임 DF 으로 연산 진행시, "UnsafeRow"라는 내부 포맷을 사용하여 최적화를 수행함 (Row와 UnsafeRow 는 서로 다른 개념임....아래서 구체적으로 설명) UnsafeRow는 - 데이터를 연속적인 바이트 배열(byte array) 에 저장해서 메모리를 효율적으로 사용할 수 있는 구조가 됨 그래서 GC(가비지 컬렉션) 비용을 줄이고, 메모리 캐싱을 효율적으로 활용함. - Java Object 형태로 저장하는 것이 아니라 바이너리 포맷(Binary Format) 으로 저장 그래서 직렬화/역직렬화 비용 감소하고, Spark의 CPU 성능을 극대화함. 바이너리 포맷을 사용한다? -> JVM 객체를 사용하지 않고(객체 헤더, 포인터(Reference-Based)가 제거됨) -> 데이터를 연속된 배열(Contiguous Memory)로 저장 -> 메모리가 효율적으로 사용됨(구멍 뚫린 곳이 없음) -> 연속된 데이터 구조 덕분에 CPU의 캐시 친화적인 데이터 배치(Cache Friendly Layout) 가능 (CPU는 연속적인 데이터를 한 번에 가져올 때 속도가 훨씬 빠름) -> 즉, CPU L1/L2 캐시를 효율적으로 사용 가능 -> CPU 성능 극대화 더불어 JVM 객체는 주로 Heap 메모리에 쌓여서 GC 를 발생시키는데, 바이너리 포맷 (UnsafeRow) 를 사용하면 GC 를 피할 수 있어서 좋음! (GC를 피할 수 있는 이유에 대해서 아래에 설명) - Null Bitmask 제공: 컬럼 값이 NULL인지 아닌지를 빠르게 체크할 수 있도록 Bitmask를 활용. 이러한 UnsafeRow 포맷을 통해 Spark는 연산을 수행할 때 불필요한 객체 생성 없이 메모리 접근 비용을 줄여 최적화함. 그래서 Row 타입을 사용하는 게 빠르고 효율적임 |
위에서 설명한 Spark 내부 포맷(UnsafeRow)으로 객체가 생성되면 물리적으로 올라가는 메모리 영역을 off-heap 이라고 함 - on-heap : JVM 이 관리하는 메모리 영역 - off-heap : JVM 이 관리하지 않고, application 이 직접 관리하는 메모리 영역 Spark 내부 포맷이 off-Heap 메모리를 사용하여 얻는 장점은 아래와 같음 - GC 오버헤드 감소(stop-the-world 없음) : 위에서 설명한 것처럼, Off-Heap 메모리에 저장된 데이터는 JVM의 Garbage Collection 대상에서 제외됨 이는 Full GC 발생 빈도를 줄이고 GC로 인한 애플리케이션의 일시 중지 시간을 최소화하여 전체적인 성능을 향상시킴 - 직렬화/역직렬화 비용 감소 : Spark의 내부 Off-Heap 데이터 표현 방식은 JVM 객체 모델에 비해 직렬화 및 역직렬화 비용이 훨씬 저렴하거나 아예 필요하지 않은 경우가 많음. 왜냐면 데이터가 이미 바이트 형태로 메모리에 존재하기 때문 그래서 네트워크를 통해 데이터를 전송하거나 디스크에 저장/읽기 작업을 수행할 때 효율적임 - 메모리 관리 효율성 향상 : Off-Heap 메모리는 JVM 힙 크기의 제약에서 벗어나 더 많은 데이터를 메모리에 저장하고 처리할 수 있음 또한, 메모리 할당 및 해제가 JVM 객체 생성/소멸보다 더 효율적일 수 있음 즉, JVM 의 관리에서 벗어나 더 효율적으로 메모리를 사용할 수 있음 |
off-heap 과 관련된 프로젝트가 바로 Tungsten project. Tungsten은 Apache Spark 1.5 버전부터 도입된 프로젝트임 Spark의 성능과 메모리 사용 효율성을 극적으로 향상시키는 것을 목표로 진행됨 기존 Spark 엔진의 JVM 기반 객체 모델과 Garbage Collection (GC)으로 인한 오버헤드를 줄이고, 더 낮은 수준의 메모리 관리(off-heap) 및 CPU 최적화 기술을 활용하여 데이터 처리 속도를 끌어올리는 것이 목표임 Tungsten의 핵심 아이디어는 "데이터를 JVM 객체 형태로 표현하는 대신, 바이너리 형태로 직접 메모리 (주로 Off-Heap)에 저장하고 처리하자"는 것. 최적화를 위해 UnsafeRow 포맷을 사용하는 것도 tungsten 프로젝트의 일환 이를 통해 GC 부담을 줄이고 CPU 친화적인 연산이 가능함 아래는 Tungsten 프로젝트 주요 목표 및 특징임 - Off-Heap 메모리 관리 : 데이터를 JVM 힙 메모리 대신 Off-Heap 메모리에 저장하여 GC 오버헤드를 최소화 Spark 의 자체적인 메모리 관리 메커니즘을 통해 Off-Heap 메모리를 효율적으로 할당하고 해제 - 바이너리 데이터 처리 (Project Tungsten - Phase 1) : 데이터를 JVM 객체로 직렬화/역직렬화하는 대신, 데이터를 바이너리 형태(=Unsafe Row)로 직접 메모리에서 처리함 직렬화/역직렬화에 소요되는 CPU 및 메모리 비용을 크게 절감함 또한 Shuffle 진행(데이터 이동)시에 발생하는 직렬화/역직렬화 비용이 줄어들어 네트워크 비용 감소하는 효과 - 벡터화된 연산 (Vectorized Execution - Project Tungsten - Phase 2) : 한 번에 여러 데이터 레코드를 묶어서 처리하는 방식 이는 CPU의 SIMD (Single Instruction, Multiple Data) 명령어를 활용하여 데이터 처리 병렬성을 높이고 CPU 캐시 효율성을 향상시킴 예를 들어, 필터링이나 집계 연산을 수행할 때, 개별 레코드마다 함수를 호출하는 대신 벡터화된 연산자는 데이터의 "배치"에 대해 한 번의 명령으로 처리함 즉, 개별 레코드마다 연산을 수행하지 않고, 레코드들을 하나로 묶어서 한 번에 연산을 수행함 - 코드 생성 (Whole-Stage Code Generation - Project Tungsten - Phase 3): Spark 쿼리의 전체 스테이지를 하나의 최적화된 함수로 컴파일하여 실행함 이는 JVM 함수 호출 오버헤드를 줄이고, CPU 파이프라인을 효율적으로 활용하여 연산 속도를 향상시킴 Catalyst 옵티마이저가 생성한 실행 계획을 기반으로, JVM 바이트코드를 동적으로 생성하여 실행함 아래는 옵션 설정 값 - spark.memory.offHeap.enabled : Off-Heap 메모리 사용 여부를 활성화/비활성화. spark 3 부터 default true 값임 - spark.memory.offHeap.size : Spark가 사용할 Off-Heap 메모리의 총 크기(Executor의 총 메모리에서 JVM 힙 크기를 제외한 나머지 부분을 설정하는 것이 일반적) - spark.sql.Tungsten.enabled (기본값: true): Spark SQL의 Tungsten 최적화 (바이너리 데이터 처리, 벡터화된 연산) 활성화 여부 - spark.sql.codegen.wholeStage (기본값: true) : Whole-Stage Code Generation 활성화 여부 |
Catalyst : Apache Spark SQL의 핵심 엔진 SQL 쿼리 및 DataFrame/Dataset 연산을 분석, 최적화, 실행하는 역할을 담당 Catalyst optimizer : Spark SQL 쿼리의 성능을 극대화하기 위한 핵심 구성 요소 쿼리를 논리적 실행 계획에서 물리적 실행 계획으로 변환하는 과정에서 다양한 최적화 규칙을 적용하여 가장 효율적인 실행 전략을 찾아내 적용함 Catalyst Unsafe Row : Spark SQL 엔진에서 데이터를 효율적으로 표현하고 처리하기 위해 Tungsten 프로젝트의 일환으로 도입된 바이너리 데이터 포맷 JVM 객체 모델 대신, 데이터를 연속적인 바이트 배열 형태로 Off-Heap 메모리에 저장하는 것을 목표로 함 (위에서 계속 설명했던 'off-heap' 메모리에 올라가는 데이터 포맷이 바로 Catalyst Unsafe Row 임) Spark SQL 엔진은 DataFrame/Dataset의 데이터를 내부적으로 Unsafe Row 포맷으로 변환하여 Off-Heap 메모리에 저장함 쿼리 실행 시, Spark은 Unsafe Row 포맷으로 저장된 데이터에 대해 직접적인 바이트 연산을 수행 예를 들어, 필터링 조건 검사, 값 비교, 집계 연산 등을 JVM 객체 생성 없이 효율적으로 처리 가능 그리고 위에서 설명한 여러 장점들(직렬화/역직렬화 비용 감소, 네트워크 비용 감소, GC 피함 등)을 가져감 최종 결과를 사용자에게 반환하거나 외부 시스템에 저장할 때, 필요에 따라 Unsafe Row를 JVM 객체 (Row) 형태로 변환할 수 있음 (=take 혹은 collect 로 읽은 Row 데이터는 JVM on-heap 에 올라가는 데이터라는 의미) Catalyst 옵티마이저는 최적의 실행 계획을 생성하고, 이 계획의 효율적인 실행을 위해 Catalyst Unsafe Row 포맷을 활용함 |
Row 와 UnsafeRow는 서로 다른 개념임 < Row 포맷 : org.apache.spark.sql.Row > Row 포맷은 DataFrame/Dataset의 데이터를 사용자에게 노출하는 형태 Row 포맷은 on-heap 메모리에 저장되는 JVM 객체 Spark 의 구조적 API(DataFrame/Dataset API)를 통해 데이터를 조작하거나 df.collect(), df.take(), df.show()와 같은 액션(Action)을 사용하여 드라이버로 데이터를 가져올 때 사용되는 포맷 각 Row는 독립적인 Java 객체이며, Row 내의 각 필드(컬럼 값) 역시 String, Integer, Double 등 JVM 객체로 표현됨 인간이 읽기 쉽고, 디버깅 시 내용을 확인하기 용이하다는 장점이 있음 대신 JVM 을 사용하므로 생기는 단점들이 있음 이를 테면 높은 메모리 오버헤드(JVM 객체는 실제 데이터 외에 객체 헤더 등이 존재해서 발생) GC 오버헤드, 직렬화/역직렬화 비용 발생(네트워크를 통해 Executor 간에 데이터를 주고받거나 디스크 IO 등) < UnsafeRow 포맷 : org.apache.spark.sql.catalyst.expressions.UnsafeRow > UnsafeRow 포맷은 Catalyst 엔진이 Spark SQL 연산을 수행할 때 사용하는 고도로 최적화된 바이너리 데이터 표현 방식 UnsafeRow 포맷은 데이터를 연속적인 바이너리 형태로 off-heap 메모리에 저장함 UnsafeRow 포맷은 JVM 객체가 아님 대부분의 DataFrame/Dataset 변환(Transformation) 연산은 내부적으로 UnsafeRow 포맷을 사용하여 처리됨 장점은 위에서 이미 수 차례 언급함(바이트 배열 형태, 높은 메모리 사용 효율성, 높은 cpu 효율성, 바이트 연산으로 높은 cpu 효율성, SerDe 빠름, Off-Heap 메모리, GC의 영향 없음) 단점은, 사람이 직접 읽거나 디버깅하기 매우 어렵다는 점. 간단하게 설명해서, DataFrame, Spark SQL 등은 모두 내부적으로 UnsafeRow를 사용하여 연산 작업을 하고, 사용자와 소통할 때 (take, collect, show 등) 그리고 (JVM 객체가 필요한) UDF에 데이터 넘길 때 만 Row 포맷을 사용 (UDF는 일반적으로 표준 JVM(또는 Python) 객체 타입을 입력으로 받아서 동작하도록 설계됨. UDF는 UnsafeRow를 넘겨받지 못하기 때문에 (JVM 객체인) Row 로 역직렬화하여 넘겨줘야 함) 그럼 어떻게 Row 와 UnsafeRow 가 교대로 사용될 수 있을까? Spark 내부적으로, DF 의 Row 를 UnsafeRow 로 변환하는 Encoder[Row] 를 사용하기에 DF 는 Row 와 UnsafeRow 를 교대로 전환되어 사용 가능함. |
여기서 드는 의문, 구조적 API 모두(DF, DS) 내부적으로 UnsafeRow를 사용하여 연산한다면 왜 DS 가 DF 보다 성능이 안 좋다고 하는것인가? 이 질문에 답하려면, DS 가 내부에서 어떻게 동작하는지 알아야 함 알다시피, DS 는 Row 포맷을 쓰는 대신 사용자가 정의한 데이터 타입을 사용함 예를 들어 Dataset[T] 에서 T 는 JVM 객체인 String, Integer, 그리고 Map, Array 등이 올 수 있음 < T 에 String, Integer 등의 POJO (Plain Old Java Object) 가 오는 경우 > Encoder 를 사용하여 JVM 객체(T)를 UnsafeRow 으로 직렬화하고 반대로 역직렬화함 (위에서 설명한 DF 의 Encoder 와 동일한 역할) 그래서 UnsafeRow 의 장점을 그대로 가져갈 수 있음 < T 에 Map, Array, 사용자 정의 타입 등 Encoder 가 지원하지 못하는 타입이 오는 경우 > Encoder 대신 java 직렬화 lib(java.io.Serializable, Kryo) 를 사용하여 JVM 객체(T)를 직렬화함 이렇게 직렬화 한 것은 JVM 메모리 위(On-Heap) 에 올라가서 UnsafeRow 의 장점을 갖지 못 함 결과적으로, Encoder 가 지원하는 타입(POJO)의 T 를 사용하는 DataSet 은 UnsafeRow 로 직렬화되어 처리되므로 최적화 가능 Encoder 가 지원하지 못하는 타입의 T 를 사용하는 DataSet 은 JVM 위에서 처리되므로 Spark 의 최적화 기능을 사용하지 못하여 성능이 떨어짐 |
df 에서 row (레코드)는 Row 타입임 그래서 collect 나 take 로 가져온 객체도 Row 타입으로 되어 있음 >>> df.take(1) [Row(address='guntur', age=23, height=5.79, name='sravan', rollno='001', weight=67)] 참고로 take 나 collect 를 이용하여 drive 로 갖고온 Row 타입 데이터에는 스키마가 없음...! (두둥) |
구조적 API 전체 실행 과정 코드부터 rdd 로 변환되어 실제 실행되기까지 과정을 설명 이 과정중에 카탈리스트 옵티마이저가 관여하며 최적화를 진행함 1. df,ds,sql 코드 분석 2. 논리적 실행 계획 변환 3. 물리적 실행(DAG) 계획 변환 4. rdd 를 이용하여 실행 < df, ds, sql 코드를 분석함 > 컬럼 타입, 스키마 등을 확인하고, 존재하지 않는 컬럼 사용되는지 등을 확인함 분석이 마무리 된 후, 논리적 트리(logical tree)로 변환하고 논리적 실행 계획 단계로 감 < 논리적 실행 계획 > - 추상적 트랜스포메이션만 표현 - 드라이버나 익스큐터 정보 고려하지 않고 오로지 코드 위주로 확인 (코드 문제는 없는지, 최적화 할 수 있는지) - 다양한 표현식 최적화 - 코드 유효성 검증 - 테이블이나 컬럼 존재 여부 검증 아래와 같은 최적화 기법이 사용됨 - Projection Pruning: 필요 없는 컬럼 제거 (select 등으로 잡힌 컬럼 외 컬럼을 제거) - Predicate Pushdown: 필터 조건을 가능한 한 빨리 적용하여 불필요한 데이터 스캔 방지 예를 들어, Parquet 파일 읽을 때 필터 처리를 (spark 가 직접 하지 않고) parquet 에 위임함 parquet 에서 읽을 때 필터처리가 되므로, 최종적으로 spark 가 읽는 데이터 크기가 줄어듦 - Constant Folding: 계산이 미리 가능한 상수 값은 쿼리 실행 전에 계산 < 물리적 실행 계획 > - 논리적 실행 계획을 물리적인 클러스터 환경에서 실행하는 방법 정의 - 비용 기반 최적화(Cost-Based Optimization)를 통해 가장 효율적인 것을 선택 (어떤 join 이 좋을까.. 등) - 일련의 rdd 와 트랜스포메이션(DAG)으로 변환 즉 스파크는 df,ds, sql 쿼리를 rdd 트랜스포메이션으로 컴파일함 - Catalyst 는 대부분의 데이터 연산을 UnsafeRow 포맷 기반으로 수행되도록 지시함 아래와 같은 최적화 기법이 사용됨 - Join Reordering: 테이블 크기에 따라 Broadcast Join 또는 Sort-Merge Join 선택 [참고] - Sort Elimination: 필요 없는 정렬 제거 - Partition Pruning: 파티션 필터링을 통해 불필요한 데이터 로드를 방지 (꼭 필요한 파티션만 읽도록 함) (Partition Pruning 추가 설명 : https://eyeballs.tistory.com/248) < 실행 > - rdd 대상으로 모든 코드 실행 - 처리 결과는 사용자에게 반환 물리적 실행 계획까지 모두 처리된 이후(최적화 과정을 거친 이후) 생성된 마지막 byte code 는 아래 기법을 통해 마지막으로 최적화됨 - Expression Folding: 중복된 표현식을 제거 - Vectorized Execution: 한 번에 여러 개의 Row를 처리하여 성능 향상 - Pipelining: 불필요한 연산을 하나의 실행 단위로 묶어 연산 속도 최적화 여러 개의 연산이 있을 경우, 이를 하나의 실행 단계로 묶어 메모리 접근과 I/O 작업을 최적화 실행 계획 정보는 spark webui 의 sql 탭에서 확인 가능! 개인 컴터에서 --master local 로 실행한다면 localhost:4040 으로 webui 접근 가능함 |
WholeStage CodeGen, SIMD 가 뭔지 살펴보자
6.
UDF 는 모든 언어에서 생성 가능 드라이버가 UDF 를 직렬화하고 네트워크를 통해 모든 익스큐터 프로세스에 전달하여 사용할 수 있도록 함 스칼라, 자바 언어로 만든 UDF 는 JVM 위에서 동작(On-heap) 따라서 UnsafeRow 의 장점을 활용할 수 없어서 성능 저하 파이썬 언어로 만든 UDF 는 모든 워커 노드에서 파이썬 프로세스를 실행하고 UDF 및 데이터를 직렬화하여 파이썬 프로세스에 전달 파이썬 프로세스에서 UDF 를 실행한 후 결과를 다시 스파크 익스큐터 프로세스에 (직렬화하여) 전달 파이썬 프로세스 시작 부하, 파이썬 프로세스로 데이터 직렬화/역직렬화 및 전달 부하 가 있음 그래서 python process 는 최대한 사용하지 말아야 함. 대신 df,ds,sparksql, rdd 등을 사용해야 함 |
8.
셔플 조인 - 큰 테이블과 큰 테이블이 join 할 때 사용 - 전체 노드 간 네트워크 통신(셔플) 발생 (join 하는 내내 발생) 브로드캐스트 조인 - 큰 테이블과 작은 테이블(단일 워커 노드 메모리에 들어갈 수 있을 정도) 이 join 할 때 사용 - 작은 테이블을 전체 워커에 복사. 이후로 추가적인 네트워크 통신 불필요 (셔플 없음) - 각 워커에서 join 진행 |
9.
다수의 파일이 존재하는 폴더 읽으면, 각 파일이 최소 하나의 Spark 파티션이 되거나, 파일 크기에 따라 여러 파티션으로 나뉨 일반적으로 Spark 가 데이터 소스(CSV, Parquet, JSON 등)를 읽을 때 특정 경로에 있는 모든 파일을 스캔함 그리고 각 파일을 하나 이상의 Input Split으로 나눔. 마치 Hadoop HDFS 처럼 이 Input Split이 Spark 파티션의 기본 단위가 됨 데이터를 읽을 때는 스트리밍 방식을 사용하여 청크 단위로 읽음 < 폴더 내에 기본 파티션 크기보다 작은 파일을 읽을 때 > (Input Split 으로 나뉘지 않고) 그 작은 파일 그대로 파티션이 됨 예를 들어 기본 파티션 크기가 128mb 이고 읽을 파일이 30mb면, 30mb 짜리 파티션이 됨 여기서 기본 파티션 크기(=InputSplit 크기)는 spark.sql.files.maxPartitionBytes 설정으로 업데이트 가능 < 폴더 내에 매우 큰 단일 파일이 있고, 해당 파일 포맷이 분할 가능(splittable)할 때 (예: 일반 CSV, Parquet, ORC) > 기본 파티션 크기에 따라 그 파일을 여러 Input Split 나누고 그것들이 모두 파티션들이 됨 < 폴더 내에 매우 큰 비분할(non-splittable) 압축 파일(예: gzip)을 읽을 때 > 그 파일은 기본 파티션 크기로 나뉘지 못하고 하나의 Input Split으로 처리됨 결과적으로 하나의 파티션이 됨 만약 이 비분할 파일이 기본 파티션 크기보다 커도, 청크 단위로 읽기때문에, 읽기 작업 자체에서 OOM은 발생하지 않음 |
DataFrame 을 (dest에) 쓸 때, DataFrame 파티션 당 하나의 파일이 생성됨 |
파티셔닝 - 어떤 데이터를 어디에 저장할지 제어하는 기능 - 필요한 데이터만 읽을 수 있음 - 파티셔닝 결과를 보면 여러 dir 가 있는데, 각 dir 마다 서로 다른 데이터가 내부에 들어있음 - 예) Hive Table 에서 날짜별로 파티셔닝 - 쓰기 : df.write.partitionBy("year", "quarter").mode("overwrite").parquet("data_output") - 결과 : data_output/year=2023/quarter=Q1/part-00000.parquet.... - 읽기 : df = spark.read.parquet(f"data_output/year=2023/quarter=Q1") < 파티셔닝 장점 > - Partition Pruning : 필터링 시 해당 파티션만 읽으므로 I/O 비용 절감. - 쉬운 이해: 디렉토리 구조가 직관적이라 데이터 관리 용이. < 파티셔닝 단점 > - 너무 많은 파티션 : 파티션 키의 고유 값이 매우 많으면(높은 cardinality) 수많은 작은 디렉토리와 파일이 생성되어 "Small File Problem" 발생 가능 (Small File Problem 는 다수의 작은 파일들을 다루면 성능이 저하되는 문제임. 작은 파일들의 메타데이터를 저장/관리하는 NameNode 에 부하, spark task 과하게 생성됨 및 관리 부하, 디스크 및 네트워크 IO 부하 등) - 데이터 스큐 : 특정 파티션 키에 데이터가 몰리면 해당 파티션만 커져서 데이터 스큐가 발생 가능 - 셔플 발생 : 파티셔닝된 데이터를 다른 키로 Join하거나 GroupBy할 때 셔플이 발생 가능 < 버켓팅 > - 컬럼 값을 기준으로 데이터를 hashing하여 고정된 개수의 "버킷"(파일)으로 나누어 저장하는 방법 - 동일한 hash 를 갖는 데이터는 하나의 물리적 파티션에 모여있게 됨 - 데이터를 물리적으로 미리 hash soring 하여 저장, 특정 연산(Join, GroupBy) 시 셔플을 피하거나 줄여 성능 향상 - 해시 함수를 사용하여 데이터가 버킷에 고르게 분배됨 - 쓰기 : df.write.bucketBy(4, "id").sortBy("id").mode("overwrite").saveAsTable("data_output") # 'id' 컬럼 기준 4개 버킷 - 결과 : spark-warehouse/data_output/part-00000_bucket_00000.snappy.parquet.... - 읽기 : df = spark.read.table("data_output") < 버켓팅 장점 > - Shuffle 제거/최소화 : Join이나 GroupBy 연산 시 셔플을 피하여 성능을 향상 버킷 키와 조인 키가 동일할 때 효과적임 - 데이터 균등 분배 : 해시 기반으로 데이터를 분배하여 데이터 스큐를 완화 < 버켓팅 단점 > - 사전 지식 필요: 버킷 수와 버킷 키를 미리 결정해야 함 - Metastore 의존성 : 버켓팅 정보를 Spark이 활용하려면 Hive Metastore에 테이블을 등록해야 함.... (saveAsTable 사용). - 유연성 부족 : 버킷 수는 고정되어 있으므로, 데이터가 계속 증가하면 이슈 발생. 버킷당 데이터 양이 너무 많아지거나 불균형해질 수 있음 버킷 수를 변경하기 위해 테이블을 다시 생성해야 함 - 쿼리 필터링에는 파티셔닝이 더 효율적 : 읽기 진행시 모든 버킷 파일을 스캔하여 부하가 있음. partition pruning 을 하지 못함 파티션은 데이터를 디렉토리로 나누어 저장하는 방식이고, 버켓팅은 데이터를 파일별로 해싱하여 나누어 저장 두 가지 방법 혼용해서 사용 가능함..! df.write.partitionBy("year", "month").bucketBy(100, "user_id").saveAsTable(...) |
스파크는 데이터를 쓸 때, 자동으로 파일 크기를 제어할 수 있음 데이터를 쓸 때 너무 크지도, 너무 작지도 않은 최적의 파일 크기를 계산하여 파일을 생성(write)함 Spark 3.0부터 도입된 Adaptive Query Execution (AQE) 이 그 역할을 함 AQE는 런타임에 쿼리 실행 계획을 동적으로 조정하여 성능을 최적화 spark.sql.adaptive.enabled (기본값: true in Spark 3+) : AQE 활성화 유무 spark.sql.adaptive.coalescePartitions.enabled (기본값: true in Spark 3+) : 이 설정이 활성화되면, AQE는 셔플 이후에 생성되는 파티션의 크기를 모니터링하여 너무 작은 파티션들을 자동으로 병합(coalesce)함 이는 spark.sql.adaptive.advisoryPartitionSizeInBytes (기본값 128MB) 설정값을 기준으로 파티션을 병합하여, 출력 파일의 크기를 약 128MB 정도로 유지하려고 시도함 예를 들어, 셔플 결과 1000개의 파티션이 생겼는데 각 파티션이 10MB로 너무 작다면, AQE는 이를 자동으로 병합하여 100개의 100MB 파티션으로 만들 수 있음 AQE 가 활성화되면, 파티션 개수와 상관없이 AQE 의 매커니즘에 따라 데이터 개수(크기)가 정해짐 AQE 가 비활성화되면, 파티션 개수에 따라 데이터 개수(크기)가 정해짐 |
10.
클라이언트(예를 들면 tabealu)가 (Hive 대신) 스파크SQL 을 사용하기 위해, SQL 인터페이스(hue, beeline2) 등을 사용해 스파크 driver 에 (JDBC 로) 접속한 뒤 쿼리 실행 가능 하지만 스파크 SQL 은 OLTP 가 아닌 OLAP 로만 사용됨 (짧은 지연 시간이 필요한 OLTP 쿼리 수행하기엔 부적절) 스파크 프로그래밍에서 SQL 의 결과는 df 로 나타남 df 을 스파크 SQL에서 처리하려면 tempview 에 등록해야 함 |
Hive 가 포함된 시스템에서 SparkSQL 을 함께 사용하면 SparkSQL 은 테이블 정보를 얻기 위해 Hive metastore 에 접속하여 정보를 가져옴 접속 정보만 가져오는 게 아니라, 데이터를 쓰고 또 삭제까지 가능함 즉, hive metastore 를 완전하게 사용 가능! spark.sql.catalogImplementation=hive 로 설정해야, metastore 로 hive metastore 를 사용하게 됨 당연한말이겠지만, metastore 에 접속할 때 필요한 DB 정보를 Spark 에 미리 설정해두어야 함 hive-site.xml 을 통해 설정 가능 hive-site.xml 은 Spark가 Hive 메타스토어와 상호작용할 때 필요한 설정이 포함됨 - hive.metastore.uris Hive Metastore : 서비스의 URI (ex: thrift://localhost:9083) - hive.exec.dynamic.partition : 동적 파티셔닝 활성화 여부 (true or false) - hive.exec.dynamic.partition.mode : 동적 파티셔닝 모드 (strict 또는 nonstrict) - hive.metastore.warehouse.dir : Hive 테이블 데이터를 저장하는 기본 디렉터리 (hdfs://namenode:9000/user/hive/warehouse) - hive.metastore.client.factory.class : Spark에서 Hive Metastore를 접근하는 데 사용하는 클라이언트 |
만약 SparkSQL 이 hive 와 연동하여 사용되지 않더라도, SparkSQL 은 metastore 가 필요하긴 함. 그래서 (Hive metastore 를 사용하지 못하는 대신) in-memory metastore 를 만들어 대신 사용한다고 함 memory 에 적재되기 때문에, spark session 이 종료되면 그 동안 쌓은 메타데이터가 날아감 따라서 in-memory metastore 는 그냥 테스트용으로 사용하고, 운영할 때는 꼭 외부 저장소를 metastore 로 사용해야 함 SparkSQL 이 metastore 를 사용하는 목적은 hive metastore 의 존재 이유와 진배없음 테이블의 스키마 정보, 위치 정보, 테이블 정보 등을 저장하기 위함 metastore 에는 메타데이터만 저장되며, 테이블에 들어가는 실제 데이터는 외부 저장소(HDFS, S3 등)에 저장됨 Spark SQL은 테이블 메타데이터를 위해 무조건 Hive Metastore만 사용해야 하는 것은 아님 그럼 왜 굳이 "hive의" metastore를 사용하는 것일까? 상호 운용성(Interoperability)과 빅데이터 생태계의 표준화 때문임. 이게 뭐냐? 간단히 설명해서, "하나의 메타스토어를 사용함으로써 여러 Hadoop ecosystem들이 데이터의 메타데이터를 공유"하기 위해서. Hadoop 생태계에서 Hive Metastore는 HDFS나 S3 같은 분산 스토리지에 저장된 데이터 스키마, 테이블 위치, 파티셔닝 정보, 파일 형식 등의 메타데이터를 저장하는 사실상의 표준 저장소임 Spark SQL이 Hive Metastore를 사용함으로써 Spark에서 생성한 테이블은 다른 엔진에서도 즉시 쿼리할 수 있고 반대로 다른 엔진에서 생성한 테이블도 Spark에서 바로 사용할 수 있음 이는 데이터 일관성과 공유를 극대화함 만약 에코시스템들이 hive metastore를 사용하지 않는다면, 데이터에 대한 통합된 뷰(view)를 만들기가 어렵고 데이터 사일로(silo)가 발생하며, 데이터 거버넌스(governance) 및 관리 비용이 증가하게 됨 metastore 를 새로고침? 갱신하는 쿼리 REFRESH TABLE mytable; |
외부 사용자가 SparkSQL 을 DB 처럼 연결하여 사용할 수 있도록 JDBC 인터페이스를 제공함 예를 들어 외부 tabealu 프로그램이 우리 서버의 SparkSQL 에서 제공하는 JDBC 를 통해 spark driver 에 접근하여 데이터를 읽도록 허용할 수 있음 hive 에서 동일한 역할(외부 클라이언트가 Hive에서 쿼리를 실행할 수 있도록)을 하는 서버를 hiveserver2 라고 하며 이 hiveserver2 는 Apache Thrift 기반이라고 함 (Apache Thrift 는 서로 다른 언어로 작성된 프로그램끼리 연결 가능하게 해주는 cross language RPC 프레임워크) SparkSQL 은 이 hiveserver2 에 맞춰 구현되어있으며, 그 말인 즉슨 SparkSQL 도 thrift 기반이라는 의미(=다른 언어로 작성된 프로그램에서 SparkSQL 에 접근 가능) SparkSQL thrift server 의 default port 는 10000 SparkSQL 은 기본적으로 JDBC 를 지원함 Spark 에서 Thrift server 를 실행해야 Thrift 지원이 가능하게 됨 |
Spark SQL 에는 '카탈로그'라는 개념이 있음 Spark SQL의 카탈로그(Catalog)는 데이터베이스, 테이블, 뷰, 함수, 파티션 등의 메타데이터를 관리하는 시스템 (org.apache.spark.sql.catalog.Catalog 패키지로 사용 가능) 그럼 카탈로그와 metastore 는 뭔 차이냐? 카탈로그(Catalog)는 Spark가 job 실행 동안 메타데이터를 임시로 저장하고, 다른 메타데이터를 조회하고 조작하는 API. (SparkSession.catalog) Hive 메타스토어(Metastore) 영구적으로 메타데이터를 저장하는 스토리지. (예: In-Memory, Hive Metastore, Glue 등) Hive metastore 는 데이터를 저장하는 스토리지이고, Spark catalog 는 Hive metastore 에 접근하기 위한 인터페이스로 사용됨 Catalog 가 없다면, Hive Metastore의 데이터를 조회하는 것은 불가능함(!) Hive Metastore는 데이터베이스(DB)에 저장된 메타데이터를 관리하는 저장소일 뿐임. Spark는 Hive Metastore에 직접 접근하는 것이 아니라, Catalog API를 통해 테이블 정보를 조회하고 조작함 Spark 에서 쿼리를 실행하면, Hive Metastore 로부터 메타데이터를 Spark Catalog 로 임시 캐싱해 옴 임시 캐싱한 메타데이터 기반으로 데이터 스키마 및 위치를 알아낸 다음 실제 데이터를 읽을 때 사용 |
Spark 카탈로그는 Spark Driver 의 JVM 메모리에서 동작하는 내부 컴포넌트(SparkSession.catalog) 스파크 카탈로그(SessionCatalog) 는 (메타데이터가 있는) 메타스토어에 연결하기 위한 통로임 내가 만약 Spark SQL 을 통해 A 테이블에 쿼리를 실행한다고 가정해보자 - Spark SQL의 쿼리 엔진은 SessionCatalog 를 통해 "A 테이블의 스키마는 무엇이고, 데이터는 어디에 저장되어 있어?"라고 물어봄 - 카탈로그(SessionCatalog)는 자신이 연결된 (설정된) 외부 메타데이터 저장소(Hive Metastore, Glue 등)에게 해당 질문을 전달하고, 그 결과를 Spark SQL 쿼리 엔진에게 다시 넘겨줌 (결과를 SparkCatalog 에 임시 저장. 세션동안만 유지) - Spark SQL 은 해당 정보를 기반으로 쿼리를 실행함 위와 같이, SessionCatalog가 (SparkSQL과 메타스토어)중간에서 추상화 및 중계 역할을 함으로써, Spark SQL은 특정 메타데이터 저장소의 세부 구현 방식에 구애받지 않고 일관된 방식으로 메타데이터에 접근할 수 있음(이것이 Spark 카탈로그의 존재 의미) 반대로 말해, Session Catalog 가 없다면 외부 메타스토어(Hive Metastore)에 연결할 수 있는 방법이 없어서 결과적으로 Spark은 외부 Hive Metastore에 저장된 테이블 메타데이터에 접근할 수 없게 됨 (=메타데이터에 접근 안 됨 -> 테이블 사용 불가) |
in-memory, hive metastore 뿐만 아니라, 외부에서 제공하는 Apache Iceberg, Delta Lake, AWS Glue Catalog 같은 카탈로그도 사용 가능함! in-memory metastore, AWS Glue Catalog, Apache Iceberg는 메타데이터를 저장할 뿐만 아니라 이를 관리하고 제공하는 API도 포함함(!) 즉, "메타스토어 + 카탈로그 기능을 동시에 제공"하는 시스템임 (Hive Metastore는 단순한 메타데이터 저장소지만, in-memory metastore, Glue와 Iceberg는 자체적인 API와 카탈로그 시스템을 통해 Spark와 연동 가능) hive 의 경우 metastore 와 metastore service 가 나뉘어져 있는데 Glue 와 iceberg 는 통합되어있다는 말임 Glue - hive metastore 처럼 테이블 스키마, 파티션 정보, 데이터 위치, 파일 형식 등의 메타데이터를 저장하는 저장소 역할 - (hive metastore service 데몬이 thrift 를 사용하여 클라이언트의 연결을 받는 것처럼) Glue 에 접근할 때 AWS SDK 를 통해 직접 접근 가능한 API 를 제공함 - 이 API 를 통해, 클라이언트는 Glue 에 직접 접근 후 메타데이터를 쓰거나 읽는 등의 작업이 가능함 추가) Glue 에 S3와 같은 데이터 레이크의 스토리지 위치를 지정하면, Glue 내부 크롤러가 그 위치의 데이터를 스캔하여 자동으로 스키마를 추론하고 Glue Data Catalog에 메타데이터를 자동으로 채워줌 반대로, Hive Metastore는 Glue처럼 기본적으로 스토리지를 스캔하여 자동으로 메타데이터를 추론하고 채워주는 기능이 없고 엔지니어가 SQL DDL(Data Definition Language) 명령어를 사용하여 테이블의 스키마, 데이터 저장 위치, 파일 형식 등을 직접 정의하고 Metastore에 등록해야 함 참고로, Catalyst 옵티마이저가 쿼리를 최적화할 때 Catalog의 정보를 참조하여 최적화된 실행 계획을 만듦. |
sparkSQL 이 hive metastore 에 메타데이터를 저장하는 방법에 대해 설명 두 가지 전제가 필요함 1. 실제 데이터 파일 (예: Parquet, CSV, JSON 등)이 저장되는 스토리지. 예를 들어 S3 2. hive-site.xml : Spark 가 Hive Metastore 의 연결 정보를 얻기 위해 필요함 우리가 사용하는 Spark SQL 이 Hive Metastore 에 접근하는 클라이언트가 됨 Spark SQL 은 catalog 를 통해 Metastore 에 접근하게 되고, 테이블 정의를 읽어오거나, 새로운 테이블 정의를 등록할 수 있음 S3 버킷 s3://my-data-lake-bucket/raw_data/web_logs/2025/07/01/ 경로에 CSV 파일들이 존재한다고 가정해보자 이 csv 파일들에 대한 메타데이터는 hive metastore 에 아직 존재하지 않음 (=Spark SQL 쿼리를 통해 이 csv 파일들을 읽어올 수 없음) 아래 코드를 실행하여 hive metastore 에 메타데이터를 등록하고, 등록된 metastore 의 메타데이터를 이용하여 csv 파일을 읽을 수 있음 ----------------------------------------------------------------------------------------------------------------------------------- from pyspark.sql import SparkSession # SparkSession 생성 시 Hive Metastore 연동 활성화 # 'enableHiveSupport()'를 호출하면 Spark가 기본적으로 hive-site.xml을 찾거나 # Spark 설정에 hive.metastore.uris 등을 명시해야 함. spark = SparkSession.builder \ .appName("S3_Hive_Table_External_DDL") \ .enableHiveSupport() \ .getOrCreate() # S3 경로 s3_data_path = "s3a://my-data-lake-bucket/raw_data/web_logs/" # Spark SQL을 사용하여 EXTERNAL TABLE 생성 # 이 DDL이 Hive Metastore에 메타데이터를 등록함 spark.sql(f""" CREATE EXTERNAL TABLE IF NOT EXISTS web_logs ( timestamp STRING, user_id STRING, page STRING, path STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '{s3_data_path}' """) print("테이블 'web_logs'가 Hive Metastore에 성공적으로 등록되었음!") # 등록된 테이블 쿼리 (Spark SQL이 Metastore에서 메타데이터를 읽어 S3 데이터에 접근) print("\n--- web_logs 테이블 쿼리 결과 ---") spark.sql("SELECT * FROM web_logs LIMIT 5").show() # 스키마 확인 print("\n--- web_logs 테이블 스키마 ---") spark.sql("DESCRIBE web_logs").show() spark.stop() ----------------------------------------------------------------------------------------------------------------------------------- Spark가 실행한 CREATE TABLE 쿼리는 Hive Metastore 로 보내짐 Hive Metastore 서버는 이 요청을 받아, 자신이 사용하는 내부 관계형 데이터베이스에 이 모든 메타데이터를 SQL INSERT 문으로 저장함 이렇게 저장된 메타데이터는 Hive Metastore에 영구적으로 남게 됨 Hive, Presto, Spark SQL 등 Metastore에 연결된 모든 쿼리 엔진이 web_logs라는 테이블을 통해 S3의 실제 데이터에 접근 가능 |
s3 에 있는 데이터를 읽고 df 로 만든 후, 이 df 를 기반으로 metadata 를 저장하는 방법은 다음과 같음 ----------------------------------------------------------------------------------------------------------------------------------- from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName("S3_Hive_Table_SaveAsTable") \ .enableHiveSupport() \ .getOrCreate() s3_data_path = "s3a://my-data-lake-bucket/raw_data/web_logs/" # 1. S3에서 데이터를 읽어 DataFrame 생성 (Spark가 자동으로 스키마 추론) df = spark.read \ .option("header", "false") # 예시 데이터에 헤더 없음 .option("inferSchema", "true") # 스키마 자동 추론 .csv(s3_data_path) # 컬럼 이름 변경 (추론된 _c0, _c1 등을 의미 있는 이름으로) df = df.toDF("timestamp", "user_id", "page", "path") print("--- 추론된 DataFrame 스키마 ---") df.printSchema() # 2. DataFrame을 Hive Metastore에 테이블로 저장 (metadata만 등록) # 'mode("overwrite")'는 테이블이 이미 존재하면 덮어씀 # Spark는 DataFrame의 스키마와 S3 경로를 메타데이터로 Metastore에 등록 df.write \ .mode("overwrite") \ .saveAsTable("web_logs_inferred") print("\n테이블 'web_logs_inferred'가 Hive Metastore에 성공적으로 등록됨!") # 등록된 테이블 쿼리 print("\n--- web_logs_inferred 테이블 쿼리 결과 ---") spark.sql("SELECT * FROM web_logs_inferred LIMIT 5").show() spark.stop() ----------------------------------------------------------------------------------------------------------------------------------- df.write.saveAsTable("web_logs_inferred") 명령을 실행함 여기서 web_logs_inferred 는 테이블 이름 Spark는 df 가 가지고 있는 추론된 스키마 정보와, 이 DataFrame이 현재 가리키고 있는 원본 S3 데이터의 경로(s3a://my-data-lake-bucket/raw_data/web_logs/)를 결합하여 하나의 테이블 정의를 생성함 이 생성된 테이블 정의는 Hive Metastore Client API를 통해 Metastore 서버로 전달되고, Metastore 내부의 관계형 데이터베이스에 저장됨 이후 Spark SQL을 포함한 다른 SQL 엔진에서 이 테이블 이름을 사용하여 S3의 데이터를 쿼리할 수 있게 됨 |
카탈로그는 테이블, 데이터베이스, 함수 등을 조회하는 여러 유용한 함수를 제공함 catalog 명령어 예제 # SparkSession 생성 from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName("CatalogExample") \ .enableHiveSupport() \ # Hive Metastore 사용 설정 .getOrCreate() # Catalog 객체 생성 catalog = spark.catalog # 현재 활성화된 데이터베이스 확인 print(catalog.currentDatabase()) # 사용 가능한 데이터베이스 목록 조회 print(catalog.listDatabases()) # 테이블 목록 조회 print(catalog.listTables()) # 현재 사용 중인 모든 함수 목록 조회 print(catalog.listFunctions()) # 특정 테이블이 존재하는지 확인 print(catalog.tableExists("my_table")) |
sparkSQL 에서 어떤 DB 를 사용하겠다고 말 해주지 않으면 default DB 가 사용됨 SparkSQL이 사용하는 테이블에는 두 가지 정보가 함께 있음 - (테이블의 내용이 되는) 데이터 - metadata Spark 는 (hive 와 연동하여) 관리형 테이블과 외부 테이블을 가질 수 있음 - 내부 테이블 : 실제 데이터를 spark 가 직접 관리하는 테이블 - 외부 테이블 : 실제 데이터를 spark 가 직접 관리하지 않는 테이블 Spark 가 사용하는 metastore 에는 이 내부 테이블, 외부 테이블에 대한 메타데이터를 모두 갖고 있음 |
< 내부 테이블 (Managed Table) > 내부 테이블은 Spark/Hive가 데이터의 수명과 위치를 관리하는 테이블임 테이블을 관리하는 주체가 Spark이며, 사용자가 직접 데이터 파일을 관리할 필요 없음 삽입된 데이터는, hive-site.xml 에 설정된 위치 등에 저장됨 (HDFS 를 사용할 경우, 기본 위치는 hdfs://namenode:9000/user/hive/warehouse/테이블명/ 이며 hive.metastore.warehouse.dir 설정값을 따름) 메타데이터는 hive metastore 에 저장 drop table 로 테이블을 삭제하면, metadata 뿐만 아니라 실제 데이터까지 날아감 해당 테이블의 데이터는 Spark/Hive 전용으로만 사용되고, 다른 애플리케이션에서 접근 불가 Managed Table 만드는 쿼리 예제 CREATE TABLE employees ( id INT, name STRING, salary DOUBLE ); |
< 외부 테이블 (External Table) > 내부 테이블과 다르게, 외부 테이블은 데이터 파일을 Spark/Hive가 직접 관리하지 않는 테이블 실제 데이터는 사용자가 지정하거나 설정한 위치에 저장됨 사용자가 LOCATION을 명시하면 해당 경로에 있는 데이터를 테이블로 등록 가능 예를 들어, 내가 s3://a/b/c 위치에 데이터를 넣고 이 위치에 존재하는 데이터로 구성된 External 테이블을 만들 수 있음 데이터는 s3://a/b/c 에 그대로 존재함 메타데이터는 hive metastore 에 저장 테이블을 삭제(DROP TABLE)해도 데이터는 남아 있음 (메타데이터(스키마 정보)만 삭제되고, 실제 데이터 파일은 삭제되지 않음) drop table 로 데이터가 삭제되지 않기 때문에, 사용자가 데이터 파일을 수동으로 관리해야 함 Spark가 데이터의 소유권을 가지지 않으며, 다른 애플리케이션(Spark, Hive, Presto 등)에서도 데이터를 접근 가능 외부 테이블을 생성하는 쿼리 예제 CREATE EXTERNAL TABLE my_table ( id INT, name STRING, count LONG ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/external/table/data/location' CREATE EXTERNAL TABLE my_table ( id INT, name STRING, count LONG ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/external/table/data/location' AS SELECT * FROM origin_table |
CTAS (create table as select) 구문을 이용하여 partitioning 된 테이블 생성하는 쿼리 예제 CREATE TABLE new_table USING parquet PARTITIONED BY (date) AS SELECT id, name, age, date FROM origin_table |
11.
Dataset 은 JVM 기반 언어에서만 사용 가능(=pyspark 에서 사용 불가) 스파크가 Dataframe 으로 String, Integer 등의 데이터 타입을 처리할 때, 해당 타입의 객체를 생성하기보다는 Row 타입의 객체를 변환해 데이터를 처리 반대로, 스파크가 DataSet 으로 String, Integer 등의 데이터 타입을 처리할 때, Row 타입이 아닌 사용자가 정의한 데이터 타입(String, Integer)으로 변환해 처리 사용자 정의 데이터 타입 사용하면 성능이 안 좋음 (Encoder 대신 Java serializer 를 사용하여 On-Heap 객체를 만들기 때문) 별개로, 파이썬 UDF 함수 사용 성능이 DataSet 을 사용하는 것보다 더 안 좋음 왜냐하면 프로그래밍 언어 전환하는 것에 오버헤드가 있기 때문 |
DataSet 을 사용하는 이유 - df 기능만으로 수행할 연산을 표현할 수 없는 경우 - 타입 안정성을 갖는 데이터 타입을 사용해야 하는 경우 - 기존 시스템에서 사용한 case class 를 데이터타입으로 재활용 가능 (=사용자 정의 클래스를 데이터 타입으로 사용 가능) 정확도와 방어적 코드가 중요하다면, 컴파일 타임에서 오류 확인이 가능한 DataSet 을 사용하는게 좋음 (예 : 타입이 유효하지 않은 작업 등) |
12.
저수준 API 는 두 가지 종류가 있음 - RDD : 분산 데이터 처리 - 브로드캐스트 변수, 어큐뮬레이터 : 분산형 공유 변수 배포 및 처리 저수준 API 를 사용하는 경우 - 고수준 API 에서 제공하지 않는 기능이 필요한 경우 - RDD 를 사용해 개발된 기존 코드 유지 - 사용자 정의 공유 변수를 다루는 경우 |
RDD : Resilient Distributed Dataset (Resilient : 탄력적인, 회복 탄력성 있는) 불변성을 가지며, 병렬로 처리할 수 있는 파티셔닝된 레코드 를 표현하는 데이터 모델 Resilient (탄력적) - 노드 장애가 발생해도 RDD를 복구할 수 있음 (내고장성(Fault-Tolerance) 을 갖추고 있음) - DAG(Directed Acyclic Graph) 기반으로 Lineage 정보를 유지하여 재연산 가능. - RDD는 불변(immutable)이며, 각 RDD는 자신을 생성하는 데 사용된 부모 RDD들과 그 동안 적용되어온 Transformation 연산의 논리적인 그래프를 따로 저장하는데 이 그래프가 바로 계보(Lineage) - 계보는 Spark Driver 메모리에 저장되어 있음 각 RDD가 생성될 때마다 그 RDD의 부모 RDD 정보와 적용된 Transformation (예: map, filter, join 등) 정보가 드라이버의 메모리에 있는 DAG(Directed Acyclic Graph) 스케줄러에 기록됨 - 분산 환경에서 Task가 실패하거나, 특정 Executor가 데이터를 잃어버리는 경우, 데이터를 어떻게 복구할까? Task 가 실패한 것을 드라이버가 알아차리게 되면 복구를 시도함 Spark Driver가 갖고있는 계보 정보를 활용하여, 해당 Task가 실패한 RDD 파티션을 재계산하여 복구 '실패한 파티션'을 복구하기 위해 '원본 데이터 소스'부터 시작하여 필요한 모든 변환을 다시 재수행 Distributed (분산) - 여러 클러스터 노드에 데이터를 분산 저장 및 처리 - Spark 클러스터의 Executor에서 개별적으로 처리됨 - 그렇다고 RDD 가 직접 분산되다는 말은 아님. RDD 는 Driver JVM 메모리에만 존재하며, 실제 데이터를 저장하지도, 데이터의 위치를 나타내지도 않음 RDD 가 갖고 있는 것은 파티션의 개수와 partition ID, 파티션을 어떻게 계산할지 등에 대한 메타정보임 - RDD가 표현하는 데이터가 분산 가능하다는 의미로 distributed 라는 이름이 붙음 Dataset (데이터셋) - RDD 는 데이터를 직접 담고 있지는 않지만, 어떤 데이터 집합을 나타내며 (말 그대로 '이러이러한 데이터 집합' 이라고 나타내기만 함) 그 데이터 집합을 어떻게 얻고 조작할 수 있는지에 대한 모든 정보(계보, 파티셔닝, 계산 로직 등)를 포함하고 있기 때문에 'Dataset'이라고 불림 (구조적 API 와 마찬가지로) 액션 실행 전 지연 트랜스포메이션 방식을 사용함 RDD 는 데이터를 저장하는 주체가 아님 RDD 는 단지 df 의 연산 과정을 기록한 메타데이터(DAG, 계보)일 뿐이고, 실제 연산은 executor 내에서 파티션을 처리하면서 진행됨 그냥 데이터(파티션)가 어떻게 처리되어가는지 보여주는 논리적 흐름의 기록임. 실제 데이터는 파티션 그대로 존재함. 구조적 API 가 물리적 실행 계획을 거쳐 RDD 로 변환한다는 설명도 실제 데이터가 RDD 로 변환한다는 게 아니라, "이 데이터(파티션)를 필터링을 하고 그룹짓고 카운팅 한다" 라는 논리적 흐름(과 의존성)을 갖는 실행 계획을 생성한다 라고 이해해야 함 실제 데이터(파티션)를 가공하고 연산 처리하고, 캐싱하는 등의 실질적인 작업 주체는 Executor 내부의 Task 임 RDD는 이 모든 분산 작업을 조율하고, 장애 발생 시 재연산할 수 있는 '회복력 있는 분산 컬렉션'을 추상화하는 모델 역할 구조적 API, 저수준 API를 이용한 작업(연산) 실행시 코드가 RDD 레벨로 다시 해석됨 이렇게 RDD 라는 메타데이터로 작업 흐름을 기록(=계보)하고 있기 때문에 내고장성을 갖을 수 있는 것임 Dataframe 의 각 레코드는, 스키마를 알고 있는 필드로 구성된 구조화된 Row (테이블 형태) 이지만 RDD 의 레코드는, (프로그래머가 선택한 Scala, Python 등) 언어의 객체일 뿐. Row 개념이 없음 RDD[T]에서 T (예: RDD[Row], RDD[String], RDD[Int], RDD[UnsafeRow])는 해당 RDD가 논리적으로 나타내는(관리하는) 분산된 데이터 컬렉션의 각 요소(레코드)가 갖는 포맷(데이터 타입)을 의미함 예를 들어, RDD[String]이라면 RDD가 나타내는 모든 파티션 내의 각 레코드가 문자열(String) 타입이라는 것을 의미 RDD 레코드는 완벽하게 제어 가능하지만, 최적화를 하려면 (구조적 API 와는 다르게) 훨씬 많은 수작업이 필요 구조적 API 가 제공하는 여러 함수 사용 못하기에 수동으로 처리해야 함 구조적 API 와 다르게, RDD 는 구조화된 데이터 엔진을 사용해 데이터를 저장하거나 다루지 않음 RDD 를 사용하는 이유 - 저수준 연산(Partition 관리, Custom Serialization 등)을 직접 제어할 필요가 있을 때 - DataFrame/Dataset이 제공하는 기능으로 해결할 수 없는 복잡한 로직을 구현해야 할 때 - 데이터의 구조가 동적으로 변하는 경우 (예: JSON 파싱) RDD API 는 모든 언어에서 사용 가능하지만 파이썬에서 RDD 를 사용하면 RDD 모든 레코드에 파이썬 UDF 를 적용하는 효과. 즉, 엄청난 성능 저하 발생 왜냐면 Python RDD 를 사용한다는 말은, Python 객체를 사용한다는 말과 진배 없기 때문 Spark 는 JVM 위에서 동작하기 때문에, Python 객체를 사용하게 되면 외부 Python process 로 데이터를 직렬화하여 보내고, Python process 에서 처리를 끝낸 결과를 다시 직렬화하여 Spark JVM 에 반환하는 일련의 작업들이 오버헤드를 높임 DataSet 과 다른 점은, DataSet 은 최적화 기법을 제공한다는 것 |
RDD 내부 상황을 조금 확인해보자 val rdd1 = sc.textFile("s3://logs1") val rdd2 = sc.textFile("s3://logs2") 위와 같이 rdd 를 두 개 만들면, Driver JVM 메모리 내에 RDD 2개가 완전히 독립적으로 생성됨 RDD1 ├── Partition 0 ├── Partition 1 └── Partition 2 RDD2 ├── Partition 0 ├── Partition 1 ├── Partition 2 └── Partition 3 RDD1 은 데이터를 세 개의 파티션으로 나눴고 RDD2 는 데이터를 네 개의 파티션으로 나눴음 이 두개의 RDD 들은 계보(Lineage) 도 독립적으로 갖고 있음 즉, RDD1_2 ↑ filter RDD1 ↑ textFile RDD2_2 ↑ map RDD2 ↑ textFile RDD 를 요약한 문장 RDD itself lives on the driver as metadata. The actual data is distributed across executors by partition, and RDD defines how the data is partitioned and how each partition can be computed. |
내부적으로 RDD 는 아래 다섯가지 주요 속성으로 구분됨 1. 파티션 목록 RDD는 여러 개의 파티션(partition)으로 구성되며, 각 파티션은 클러스터의 여러 노드에 분산 저장됨 각 파티션은 독립적으로 연산이 수행되며, 병렬 처리됨 2. 각 조각을 연산하는 함수 RDD의 각 파티션에서 독립적으로 실행될 연산(Transformation) 함수(map, groupBy 등)를 제공함 Spark는 이러한 함수를 DAG(Directed Acyclic Graph) 내부에서 관리함 3. 다른 RDD 와의 의존성 RDD는 기존 RDD를 변형하여 생성됨 이러한 RDD의 변환 과정에서, "부모 RDD와의 의존성(dependency)"을 갖게 됨 Spark는 이러한 의존성을 활용하여 Lineage Graph 를 구성하고, 장애 발생 시 데이터를 재생성(복구)하는 데 사용함 rdd.toDebugString() 명령어 실행으로 계보를 볼 수 있음 4.부가적으로 key-value RDD 를 위한 Partitioner Key-Value 기반의 RDD에서는 데이터를 특정 방식으로 파티셔닝(partitioning)할 수 있음 - HashPartitioner: 키를 해시값으로 변환하여 할당 - RangePartitioner: 키의 범위를 기준으로 할당 HashPartitioner 사용 예시) pair_rdd = spark.sparkContext.parallelize([(1, "a"), (2, "b"), (3, "c"), (4, "d")]) partitioned_rdd = pair_rdd.partitionBy(2) # key 를 해시한 값을 이용하여, 2개의 파티션으로 나누기 print(partitioned_rdd.glom().collect()) # glom 을 사용하면, 파티션별 리스트로 묶은 결과를 collect 됨 5. 부가적으로 각 조각을 연산하기 위한 기본 위치 목록 RDD의 각 파티션이 저장될 클러스터 노드 위치 정보를 (Spark의 스케줄러가 접근할 수 있는 메모리 내에) 저장 및 이용함 (이 위치 정보는 데이터 로컬리티(Data Locality) 를 최적화하기 위해 사용됨) 예를 들어, HDFS에서 어떤 데이터를 읽었고 그것을 RDD 로 연산한다면, 그 RDD 연산은 (가능한 한) 해당 HDFS 데이터가 존재하는 노드에서 실행되도록 설정됨 데이터 노드의 위치 정보는 getPreferredLocations() 메소드를 통해 확인 |
RDD 는 저장하고 있는 데이터 형태에 따라, 두 가지 타입이 존재함 - Generic RDD - Key-Value RDD < Generic RDD > 데이터를 개별 요소(element)의 리스트(List of elements) 형태로 저장하는 RDD. 주로 일반적인 컬렉션(리스트, 문자열, 숫자 등)에 대한 연산을 수행할 때 사용됨. 아래처럼 두 가지 방법으로 만들 수 있음 # 1. 컬렉션에서 생성 data = [1, 2, 3, 4, 5] rdd = spark.sparkContext.parallelize(data) # Generic RDD 생성 print(rdd.collect()) # [1, 2, 3, 4, 5] # 2. 파일에서 생성 rdd_text = spark.sparkContext.textFile("hdfs://path/to/file.txt") # 텍스트 파일을 읽어서 RDD 생성 요소 단위로 변환하는 map(), filter(), flatMap() 등, 일반적인 RDD 연산 수행 가능함 하지만 (Key-Value 형태가 아니기 때문에) GroupBy, ReduceByKey 등의 키 기반 연산은 수행 불가함 < Key-Value RDD (Pair RDD) > 데이터를 (Key, Value) 쌍(Pair) 형태로 저장하는 RDD. 주로 데이터를 그룹화하거나 집계하는 연산을 수행할 때 사용됨. 내부적으로 Hadoop MapReduce 스타일의 Key-Value 연산(map-reduce 연산)을 최적화하여 지원. 아래와 같은 방법으로 만들 수 있음 # (Key, Value) 형태의 데이터 생성 pair_data = [("apple", 3), ("banana", 2), ("apple", 5), ("orange", 7)] pair_rdd = spark.sparkContext.parallelize(pair_data) # Key-Value RDD 생성 print(pair_rdd.collect()) # [('apple', 3), ('banana', 2), ('apple', 5), ('orange', 7)] 연산 예제 (아래 예제엔 없지만 Join 도 가능) - reduceByKey : 동일한 Key에 대해 연산 수행 pair_rdd.reduceByKey(lambda a, b: a + b) - groupByKey : 동일한 Key끼리 그룹화 pair_rdd.groupByKey().mapValues(list) - mapValues : Value만 변경 pair_rdd.mapValues(lambda v: v * 2) - keys : Key만 가져옴 pair_rdd.keys() - values : Value만 가져옴 pair_rdd.values() - sortByKey Key : 기준 정렬 pair_rdd.sortByKey() |
서술했다시피, RDD 는 불변성을 갖고 있기 때문에 RDD 내용을 업데이트하려면, 기존 RDD 기반으로 새로운 RDD 를 다시 만들어야 함 이렇게 RDD 가 계속 업데이트 되면서 lineage, 즉 계보를 생성하게 됨 이 계보는 RDD가 생성된 연산들의 중간 단계를 기록한 것이며, 모든 RDD가 다 갖고 있음 중간 단계를 기록한다는 의미는, "이 RDD 가 어떤 연산을 통해 생성되었는지 여태까지의 연산 내용"을 의미함 이를 통해 RDD 의 내결함성(실제 데이터가 손실되어도, 계보를 통해 다시 연산하여 자동으로 복구 가능)을 갖출 수 있게 됨 이에 따라 안정성도 올라감 계보는 spark driver 메모리 내에 존재하고, 외부 시스템에 저장되거나 하진 않음 이 계보 자체가 손상되는 경우는 거의 없음 (메모리 내에서 생성되고 작업되니까) 이 계보는 Driver 의 메모리에 존재하기 때문에, RDD 가 늘어날수록 Driver 메모리 부하가 커짐 데이터 손실에 따른 복구 절차는 다음과 같음. - RDD 데이터의 일부 파티션이 클러스터 노드에서 실패하거나 손실됨 - spark는 해당 RDD 의 계보를 이용하여 해당 파티션의 데이터가 어떤 연산을 거쳐 생성되었는지 추적 - 초기 데이터부터 시작하여 해당 연산들을 재실행하여 손실된 파티션 복구 RDD 에 연산을 너무 많이 해서 계보가 일파만파 길어질 가능성도 존재함 계보가 너무 길면 복구를 위한 연산이 비효율적으로 변함(연산 및 복구 비용이 올라감) 이를 해결하기 위해, checkpoint, cache 를 사용함 checkpoint 는 RDD 의 중간 결과((연산이 아닌)실제 파티션, 물리적인 데이터들)를 disk, HDFS 등에 물리적으로 저장하여 나중에 복구할 때 checkpoint부터 복구를 진행할 수 있도록 하여 복구 효율성을 높여줌 그리고 checkpoint 를 사용하면 계보는 삭제됨(헉) rdd.checkpoint() 를 사용하여 체크포인트 저장! 참고로 dataframe 에서는 checkpoint 를 하지 못한다고 함 내가 알고있던 것은 cache, persist 였음 그럼 df의 cache 와 rdd 의 checkpoint 는 어떻게 다른가? - df/rdd cache : df.cache() rdd.cache() (df, rdd 둘 다 사용 가능) (transfomration 연산이 실행될 때가 아닌) action 이 실행될 때, 데이터가 execution memory 에 저장됨 cache 를 진행한 이후, df를 사용하는 연산 진행시 데이터를 읽거나 변환하지 않고 메모리에 적재된 cache 를 직접 가져옴 메모리가 부족하면 disk 로 spill 되거나, 삭제될 수 있음 (필요할 때 다시 계산됨) 물론 spark session이 종료되어도 삭제됨 cache 가 계보 자체를 끊어주진 않음 데이터 복구 시 계보를 전체적으로 역추적하는 대신 캐시된 지점부터 재연산할 수 있게 하여 Driver의 복구 부담을 줄여줌 동일한 RDD/DataFrame을 여러 번 재사용할 때 매번 전체 계보를 재계산하는 것을 방지하여 Driver의 작업 부하를 줄여줌 spark ui의 storage 탭에서 cache() 된 데이터 확인 가능 - rdd checkpoint : rdd.checkpoint() (rdd만 사용 가능) 계보가 너무 길어질 때, 데이터를 저장하면서 계보를 제거하기 위해 사용 checkpoint()는 (캐싱과 달리) 이전 계보를 잘라내어(truncates the lineage graph) Driver가 관리해야 할 계보의 깊이를 크게 줄여줌 (transfomration 연산이 실행될 때가 아닌) action 이 실행될 때 실제 데이터를 disk 에 영구적으로 저장함 그래서 꼭 hdfs 같은 안정적인 저장소를 제공해줘야 함 spark session 이 종료되어도 disk 에 쓰인 데이터가 유지됨(!) 그래서 사용자가 직접 삭제해야 함 spark webui 에서는 보이지 않음 너무 긴 계보를 대신하여 안정성을 높이기 위해서 사용됨 |
13.
pyspark 의 word count text_file = sc.textFile("hdfs://...") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) counts.saveAsTextFile("hdfs://...") flatMap : 각 파티션 내 모든 레코드를 다른 값으로 변환 map : 각 파티션 내 각 레코드를 다른 값으로 변환 reduceByKey : 주어진 레코드에서 같은 키를 갖는 것끼리 집계 연산 |
reduceByKey vs groupByKey reduceByKey - combine 을 미리 진행 후 셔플 - 모든 key 값을 메모리에 유지하지 않아도 됨 groupByKey - combine 없이 모든 레코드를 셔플 - 모든 key 값을 메모리에 유지해야 함. OOM 에러 발생 가능 |
coalesce vs repartition coalesce - 되도록 동일한 워커 노드에 존재하는 파티션을 합침(물론 그렇지 못한 경우에는 repartition 처럼 셔플이 발생함) - 셔플 발생하지 않을 가능성이 있음 - 파티션을 늘릴 수 없음 repartition - 노드 간 (무조건) 셔플 발생 가능 - 균일하게 데이터를 분산 - 파티션을 늘리거나 줄일 수 있음 |
RDD 파티션들을 재파티셔닝 할 때, 위에서 hashPartitioner, rangePartitioner 를 사용할 수 있다고 말한 적 있음 이렇게 기본으로 제공되는 partitioner 말고, 엔지니어가 직접 partitioner 를 작성할 수 있음 이를 사용자 정의 파티셔닝이라고 하며, df 대신 rdd 를 사용하는 주된 이유(파티셔닝하는 기준을 직접 정할 수 있어서) 중 하나임. 예를 들어, key 값이 100, 200인 데이터만 파티션 0번으로 보내고, 나머지는 1번으로 보낸다고 하자 def customPartitionFunc(key): if key == 100 or key == 200: return 0 else : return 1 myrdd = rdd.partitionBy(2, customPartitionFunc) |
직렬화 Serialization 란, "객체(Object)"를 Byte 형태로 변환하여, 파일이나 네트워크, 메모리 등에 저장하거나 전송하는 과정을 말 함 Byte 형태의 데이터를 다시 객체로 변환하는 것은 역직렬화 Deserialization 이라고 함 spark 같은 분산 시스템에서는 (셔플 등에 의해) 데이터를 네트워크를 통해 다른 노드로 전송하는 일이 비일비재 함 이렇게 네트워크를 통해 데이터를 주고받거나, 디스크에 데이터를 저장하려면, 꼭 "연속적인 Byte Stream"으로 변환된 상태여야 함 한 노드에서 생성된 RDD 를 다른 노드로 전송해야 할 때 직렬화 해야 함 사용자가 직접 정의한 연산(클로저)를 각 워커 노드로 전달 할 때도 직렬화가 필요함 RDD 를 caching 하거나 checkpointing 하여 disk 에 데이터를 저장 할 때도 직렬화가 필요함 df 가 persist 를 통해 데이터를 disk 에 저장 할 때도 직렬화가 필요함 JAVA 를 사용하는 경우, Java Serialization 이 기본으로 제공되긴 하나, 이것은 효율적이지 못 함 Kryo serialization 이라는 직렬화가 효율이 좋아서 많이 사용됨 Kryo 를 기본 직렬화로 사용하려면 spark.serialzaer 옵션에 KryoSerializer 를 등록하면 됨 (아래 코드 예시가 있음) Kryo 를 사용하여 직렬화 하기 전, 사용할 클래스를 미리 등록해야 최적의 성능을 발휘한다고 함. 그리고 사용자가 정의한 클래스를 직렬화에 등록하지 않으면 에러가 발생한다고.... 예를 들어 from pyspark import SparkConf, SparkContext # 사용자 정의 클래스 (직렬화 필요) class MyClass: def __init__(self, value): self.value = value # SparkContext 생성 conf = SparkConf().setAppName("SerializationExample").setMaster("local") conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") conf.set("spark.kryo.registrationRequired", "true") conf.set("spark.kryo.classesToRegister", "MyClass") sc = SparkContext(conf=conf) rdd = sc.parallelize([MyClass(1), MyClass(2), MyClass(3)]) # 만약 객체를 직렬화하지 않았다면 MyClass 객체를 RDD 로 전달할 때 에러 발생! rdd.map(lambda x: x.value).collect() 다른 예를 보자 def my_function(value): return value * 2 rdd = sc.parallelize([1, 2, 3, 4]) rdd.map(my_function).collect() # my_function이 네트워크를 통해 전달됨 (직렬화 필요) 위에 예시로 든 두 가지 객체(MyClass class, my_function 함수)는 모두 driver node에서 정의된 것이고, 각 spark worker node 에는 존재하지 않음 (위 예시처럼) rdd 대상으로 MyClass, my_function 이 사용되면 spark 는 이 클래스와 함수를 직렬화하고, 네트워크를 통해 각 Worker 노드로 전송함 노드로 전송된 클래스와 함수는 역직렬화되고, 이후 RDD 의 각 파티션 대상으로 연산으로 실행됨 그래서 사용자 정의 객체(클래스, 함수)가 직렬화되지 않으면 이슈를 일으킨다는 거구나. 참고로, 위 예제에서 사용된 my_function 을 클로저 함수라고 함 왜냐면 자신이 정의된 범위(driver node) 밖(worker node)에 있는 변수에 접근하여 사용되는 함수이기 때문 추가로, disk 에 데이터를 직렬화 하여 저장할 때, 압축 옵션도 추가할 수 있음 아래처럼 설정하면, snappy, lz4, zstd 등의 압축 코덱 사용이 가능하다고 함 conf.set("spark.io.compression.codec", "snappy") |
spark 의 클로저(Closure)는 driver node 에서 정의된 변수와 함수를 worker node 에서 사용할 수 있도록 보장하는 매커니즘 driver node 에서 정의된 변수와 함수는 직렬화되어 worker node 로 전송되고 rdd 연산시 사용됨 클로저에 포함된 변수는 읽기만 가능하고, 값을 변경하려면 accumulator 를 사용해야 함 spark webui의 stages -> DAG visualization 에서 클로저가 어떻게 동작하는지 확인할 수 있다고 함 |
accumulator 란 무엇일까? accumulator(누산기)는 spark의 분산 환경에서 worker nodes들이 안전하게 값을 공유하고 누적할 수 있도록 제공하는 변수임 Spark Driver에 의해 생성되고 초기화 됨 spark 프로그래밍에서 assign 한 변수들은 worker 노드에서 사용될 때 각 worker 노드의 tasks 에서만 사용 가능한 로컬 복사본이 생성됨 태스크 내부에서 이 변수의 값을 변경하더라도, 값의 변경 사항은 해당 태스크 내에서만 유효하며, 드라이버 프로그램이나 다른 태스크에는 전달되거나 반영되지 않음 여러 태스크에 걸쳐 값을 '집계'하거나 '공유'하는 목적을 위해, accumulator를 사용함. accumulator 변수는 driver 에 존재하고, 각 worker nodes 가 이 driver node 에 있는 변수를 변경할 수 있도록 도와줌 아래 상세한 flow를 보면 이해가 될 것임 - Accumulator 객체는 (Task 에 보내질 코드와 함께) 각 Executor 로 보내짐 - 각 Task는 자신에게 할당된 로컬 복사본(local copy)의 Accumulator를 갖게 됨 - Task는 이 로컬 복사본에 업데이트(예: add())를 수행함 - Task가 완료되면, Task는 자신의 로컬 업데이트 값을 Driver에게 다시 전송하고, Driver는 이 값들을 최종적으로 집계(aggregate)하여 Accumulator의 전체 값을 업데이트 함 driver node 는 accumulator 변수값을 읽거나, 값을 초기화, 집계 할 수 있음 각 tasks 는 전체 집계된 acuumulator 변수값을 읽을 수 없고, 자신에게 복사된 로컬 값에 add 실행만 가능 따라서, 각 tasks 는 '현재까지 집계된 전체 accumulator 변수'에 기반한 논리적 결정을 내리지 못 함 Spark Driver는 여러 Task(그리고 여러 Executor)로부터 동시에 도착하는 업데이트 값들을 안전하게 집계(merge)하여 최종 Accumulator 값을 계산함 이 집계 과정은 Spark 내부적으로 스레드 안전(thread-safe)하게 처리되어, 데이터 부정합이나 경쟁 조건(race condition)은 방지 accumulator 예제 코드 from pyspark.sql import SparkSession spark = SparkSession.builder.appName("AccumulatorExample").getOrCreate() sc = spark.sparkContext # Accumulator 생성 (초기값 0. 즉 초기에 0값을 갖는 accumulator 변수가 생성됨) acc = sc.accumulator(0) def add_to_acc(x): global acc acc += x # Worker에서 acc 변수 값을 업데이트(값 추가) rdd = sc.parallelize([1, 2, 3, 4, 5]) rdd.foreach(add_to_acc) print(acc.value) # 15 (1+2+3+4+5) 만약 accumulator 를 사용하지 않는 경우라면? counter = 0 # 일반 변수 def add_counter(x): global counter counter += x rdd.foreach(add_counter) print(counter) # 0이 출력됨 위 예제에서 counter 는 각 worker node 에 복사되어 들어감 각 워커노드에서는 연산을 잘 수행하겠지만, (정작 엔지니어가 마지막에 print 를 수행한) driver node 위에 있는 counter 에는 업데이트가 반영되지 않음 그래서 print 실행시 0이 나옴 결과적으로, 일반변수와 accumulator 변수의 차이는 '각 tasks 에서 업데이트 된 변수 값을 driver 에 보내는가 보내지 않는가' 또한, transaformation 연산만 실행하면 worker node 에서 acc변수를 사용하여 누적하지 않음 역시.. action 을 수행하면 그제서야 누적을 진행함 만약 worker node 가 실패해서 acc 누적을 다시 진행하게되면 어떻게 될까? 일반적으로 Worker Node 실패로 Task가 재실행되더라도, Accumulator 변수에는 중복 데이터가 집계되지 않음 Task가 성공적으로 완료되고 그 결과가 커밋될 때만 Accumulator의 업데이트를 최종적으로 집계하기 때문 (실패한 Task는 Accumulator 값을 Driver 로 보내지 않음) accumulator는 로그 개수를 구한다거나 대량의 데이터 총합을 구하기 위해 사용된다고 함 |
브로드캐스트 변수란, driver node 에서 생성된 '읽기 전용 변수'를 각 worker node(executors) 에 공유하는 기법임 spark 는 기본적으로 각 task 가 실행될 때 필요한 변수를 driver node 에서 각 tasks 로 전송함 일반적인 변수는 task 마다 개별적으로, 또 필요할 때마다 매번 전송되므로 task 개수가 많거나, 데이터 크기가 크면 네트워크 부하가 커지고 성능 이슈를 일으킬 수 있음 (task 개수에 비례하여 (변수 이동을 위한) 네트워크 사용량이 증가) broadcast 변수를 사용하면,딱 한 번만 네트워크를 통해 각 executors 로 데이터를 전송하고 (각 executor 당 한 번만 전송) executors 는 전송받은 데이터를 local memory 에 캐시해두고 task 들이 가져다가 사용함 (더 이상 변수를 전송하지 않아도 됨) tasks 개수가 더 이상 상관이 없어짐 executor 가 브로드캐스트 변수를 사용하는 코드를 실행하는 시점에 driver 에서 브로드캐스트 변수를 읽어와서 메모리에 저장함 네트워크 I/O를 줄이고 메모리 효율성을 높여 성능을 최적화하기 위해 브로드캐스트 변수를 사용함 일반 변수 전송은 모든 tasks 마다 개별적으로 네트워크 비용을 소모하지만 브로드캐스트 변수 전송은 executor 당 한 번만 네트워크 비용을 소모 일반 변수의 경우, (같은 익스큐터 내) 여러 태스크도 각자 자신의 독립적인 변수 사본을 메모리에 로드하는데 이는 중복된 일반 변수가 익스큐터 메모리에 여러 번 로드된다는 말임(메모리 낭비!) 브로드캐스트 변수의 경우, 각 익스큐터에 단 하나의 복사본만 존재하기 때문에 메모리 절약에 도움이 됨 드라이버에서 생성한 브로드캐스트 변수는 직렬화되어 각 executor 에게 전달 각 executor 는 브로드캐스트 변수를 역직렬화하여 JVM Heap 메모리에 저장 tasks 는 메모리 내의 브로드캐스트 변수를 직렬화/역직렬화 없이 그대로 사용함 '브로드 캐스트'는 변수에만 사용되는 게 아님, 작은 테이블(dimension table) 과 큰 테이블(fact table) 을 조인할 때 작은 테이블을 브로드캐스트하는 것으로 셔플을 피할 수 있음 (이것이 브로드캐스트 조인) 브로드캐스트 변수 사용 예제 # driver node 에서 큰 Dictionary 를 만듦 (예: ID → 제품명 매핑) product_lookup = {i: f"Product_{i}" for i in range(1, 100001)} # 브로드캐스트 변수로 변환. dict(product_lookup) 이 각 executor 로 전송되고 메모리에 캐싱됨 broadcast_products = sc.broadcast(product_lookup) rdd = sc.parallelize([1, 500, 99999, 2, 3]) # rdd 에서 브로드캐스트 변수를 사용할 수 있도록 함수 구성 (각 ID를 제품명으로 변환) def map_func(x): return broadcast_products.value.get(x, "Unknown") # rdd 에서 브로드캐스트 변수 사용 result = rdd.map(map_func).collect() print(result) # ['Product_1', 'Product_500', 'Product_99999', 'Product_2', 'Product_3'] # 브로드캐스트 변수 해제 broadcast_products.destroy() 브로드캐스트 변수의 특징을 이용한 조인이 바로 브로드캐스트 조인임 근데 브로드캐스트 변수가 너무 크면, 이를 저장할 각 worker nodes 의 메모리를 많이 차지하기 때문에 OOM 등을 일으키지 않도록 조절해가면서 써야 함 브로드캐스트 변수는 읽기 전용이기 때문에, executor 에서 값을 변경할 수 없음 브로드캐스트 변수는 작업이 끝나도 자동으로 해제되지 않고 각 executor 메모리에 남아있을 수 있음(!!) SparkSession 이 살아있거나, dynamic allocation 이 활성화된 경우 등 executor 가 재사용되는 경우, 메모리에 남아있음 따라서 broadcast_var.destroy() 등으로 직접 해제해주어야 함 |
15.
클러스터 모드 : AM(스파크 드라이버)가 NM(워커 노드) 에서 동작 클라이언트 모드 : AM(스파크 드라이버)가 클러스터매니저(yarn) 외부에 있는 사용자 머신 위에서 동작 로컬 모드 : 모든 스파크 애플리케이션이 단일 머신에서 동작 이 경우 병렬처리를 위해 단일 머신의 스레드 활용한다고 함 |
yarn 과 스파크 애플리케이션(클러스터 모드) 실행 과정 (외부) - 클라이언트는 spark-submit 등을 이용하여 스파크 애플리케이션(jar, lib 파일 등)을 Spark 에게 제출 - 클라이언트 머신에서 Spark 코드가 실행되고, RM 에게 스파크 드라이버를 위한 자원 요청 - yarn RM 은 NM 중 하나 선택하여 컨테이너 준비하고, 그곳에 스파크 드라이버(AM)실행. 드라이버는 JVM 위에서 동작 스파크 드라이버가 실행되면, 스파크 잡을 제출한 클라이언트 프로그램(spark-submit)은 종료 - 스파크 드라이버(AM) 에서 실행된 SparkSession은 (작업 진행을 위해) RM 에게 익스큐터(자원) 요청 - RM 이 NM 위에 자원 확보 후 익스큐터 프로세스를 시작하고 익스큐터 위치와 여러 정보를 드라이버(AM) 에게 전달 이로서 스파크 클러스터가 완성됨 - 모든 익스큐터는 JVM 위에서 동작 - AM 이 익스큐터에 태스크 전달 - 익스큐터가 태스크 실행 - 각 익스큐터 내 태스크들은 AM 에게 진행 상황, 상태 정보, 성공/실패 보고 - AM 이 받은 보고들은 RM 에게도 전달되어 클라이언트가 RM 을 통해 AM 상태 확인 가능 - AM 이 종료된 후, RM 은 익스큐터를 모두 종료하고 익스큐터로 사용된 자원을 회수 |
스파크 애플리케이션 실행 과정 (내부) - 빌더 메소드를 통해 런타임에 SparkSession 생성 (빌더 메소드를 사용하여, 여러 라이브러리에서 SparkSession 다수 생성하는 상황 방지) - SparkSession 생성 후 스파크 코드 실행 가능 SparkSession 을 통해 sparksql, 고/저수준 API 실행, 기존 spark context, 관련 설정 정보 등에 접근 가능 - 코드에서 action 이 실행되면 스테이지와 태스크로 이루어진 job 이 실행됨 액션 하나 = spark job 하나 - 스테이지 : 다수의 머신에서 동일한 연산을 수행하는 태스크 그룹 좁은 트랜스포메이션으로 실행 가능한 태스크들을 하나로 뭉친 것(파이프라이닝)이 스테이지 셔플(넓은 트랜스포메이션)이 진행되면 무조건 새로운 스테이지가 시작됨 스테이지가 마무리된다?(=모든 머신 위의 태스크들이 작업을 마친다) -> 한 스테이지가 마무리 된 이후에 새로운 스테이지가 시작된다(=새로운 태스크들이 각 머신에서 병렬로 시작되어 작업 수행한다) - 태스크 : 단일 익스큐터에서 실행할 데이터의 블록과, 다수의 좁은 트랜스포메이션 조합 태스크는 파티션 개수대로 생성 (=하나의 파티션은 하나의 태스크에서 처리됨) 따라서 파티션 개수가 많아지면 병렬 처리성이 올라감 - 셔플 실행시, 다른 노드로부터 넘겨받은 데이터(셔플 결과)는 local disk 에 쓰여짐 job 이 실패할 경우, local disk 에 쓰여진 데이터에서부터 다시 진행 가능 (spark webui 에서 skipped 라고 표시된 게 바로 이것) (재셔플이 필수인 상황에서는 부작용으로 보이지만, 대부분의 상황에서는 시간 절약해주는 기능) 스파크에서 '파이프라이닝'기법이란, 노드 간 데이터 이동 없이 각 노드가 데이터를 직접 처리할 수 있는 연산만 모아 단일 스테이지로 만드는 실행하는 것 예를 들어 map, filter, map 순서로 작업을 수행하도록 만들었다면 내부적으로 각 작업들을 task 로 만들고 하나의 스테이지 에서 수행되도록 함 이렇게 하면, 각 단계별로 memory나 disk 에 중간 결과를 저장하지 않고 빠르게 처리할 수 있음 (셔플이 필요한 연산(넓은 트랜스포메이션)은 단일 머신에서 파이프라이닝을 할 수 없음) |
scala spark 와 pyspark 에서 잡을 제출하기 위해 사용하는 jar, python script 는 잡 제출시 모든 worker node 로 전송됨 driver 는 job 을 여러개의 stage 로 나누고, 또 stage 를 task들로 쪼갠 뒤 각 worker nodes에서 동작중인 executors에 task 를 분배함 executors는 할당된 task 를 수행하고, 필요하면 jar 파일에 포함된 클래스나 함수를 사용하여 로직을 수행하게 됨 그럼 브로드캐스트 변수는 당최 왜 필요한가? jar 파일 안에 상수를 넣어두면 잡 제출할 때 자연스럽게 모든 worker node 에 분배될텐데.... 잡 제출시 넘겨준 객체는 task 단위로 사용된다고 함. 각 tasks 가 객체를 넘겨받는다는 말임 즉, 하나의 머신(worker node, executor) 위에 100개의 task 가 존재하면,100번 객체를 넘겨받는다는 말이 됨 만약 객체 크기가 크면 네트워크 부하를 일으킬 수 있고, 또 동일한 역할을 하는 각 태스크들에 동일한 객체를 주기 때문에 중복처리가 많아 비효율적임 브로드캐스트 변수는 driver 가 데이터를 한 번만 worker node 에 전송하고, worker node 의 메모리에 저장함 (각 task가 실행될 때 일일이 driver로부터 변수를 받지 않고, worker node 의 메모리에서 받아갈 수 있음) |
16.
스파크 job 은 별도의 스레드를 사용해 여러 잡을 병렬처리 가능 스파크 스레드 스케줄러는 스레드 안정성을 충분히 보장 기본적으로 Spark 는 FIFO 스케줄러를 사용하여 스레드 스케줄링을 진행하지만 Fair 스케줄러도 사용 가능 Fair 스케줄러는 여러 개의 job 을 pool 로 그룹화하기도 함 개별 풀에 다른 스케줄링 옵션이나 가중치, 우선순위 설정 가능 |
spark job 제출 시 사용하는 옵션들 spark-submit --master : yarn 혹은 local을 지정할 수 있고, 추가로 mesos://host:port 형태로 넣을 수 있음 local[*], local[3] 에서 [] 안에 들어가는 숫자는 CPU core 수임. local 은 싱글 스레드 모드로 시작(병렬성이 없음, 한 번에 하나의 태스크만 수행) local[3] 은 3개의 CPU core 를 사용(3개만큼 병렬성이 올라감) local[*] 은 사용 가능한 모든 CPU core 를 사용 (여러 태스크를 동시에 실행) --deploy-mode : client 혹은 cluster --class : (JVM 언어 spark인 경우) 사용자 애플리케이션의 메인 클래스 --jars : (JVM 언어 spark인 경우) jar 파일의 path. 컴마로 구분하여 여러개 넣을 수 있음 --name : 애플리케이션 이름 --packages : 의존성이 있는 라이브러리. 컴마로 구분하여 여러개 넣을 수 있음 여기 설정된 의존성 lib 를 찾기 위해 먼저 로컬 저장소를 찾고 없으면 (바로 아래) --repositories 에 설정한 저장소에서 찾아 다운받아 사용 groupId:artifactId:version 포맷임 --repositories : 의존성 lib 를 검색할 때 사용할 원격 저장소. 컴마로 구분하여 여러개 넣을 수 있음 --exclude-package : --packages 에 명시된 의존성 lib 중 충돌 방지를 위해 제외해야하는 목록을 여기에 넣음. 컴마로 여러개 넣을 수 있음 --py-files : (pyspark인 경우) python 의존성 lib 파일 --files : 각 익스큐터 작업 디렉터리에 위치할 파일들. 컴마로 구분하여 여러개 넣을 수 있음 --conf : key=value 포맷. 스파크 환경 설정 속성값을 지정 --properties-file : 부가적인 속성 정보를 읽어들일 파일의 경로. 지정하지 않으면, conf/spark-default.conf 파일을 참조함 --driver-memory : 드라이버에서 사용하는 메모리 크기. 기본값은 1024M. 2G, 100M 등으로 지정 가능 --driver-cores : 드라이버에서 사용하는 코어 개수. 기본값은 1 --driver-library-path : 드라이버에 지정할 부가적인 라이브러리 경로 --executor-memory : 각 executor 에서 사용하는 메모리 크기. 기본값은 1G --executor-cores : 각 executor 에서 사용하는 코어수. yarn 에서 기본값은 1이며, standalone 모드에서는 기본적으로 모든 코어 사용 --total-executor-cores : 전체 익스큐터가 사용할 총 코어수 --num-executors : 전체 클러스터에서 실행될 익스큐터 수. 기본값은 2 각 worker node 위에서 실행될 executor 수 아님 즉, worker node 가 100개 있어도, 기본값이 2라면 이 100개로 구성된 클러스터 위에서 단 두 개의 executor 만 생성됨(...) 각 worker node 위에서 실행될 executor 수를 조절하려면, yarn.scheduler.maximum-allocation-vcores 를 설정해야 함 --queue : 잡을 제출할 yarn의 큐 이름. 기본값은 default --verbose : 추가적인 디버그 메세지 함께 출력 --version : 사용중인 스파크 버전 출력 |
spark 에서 환경설정 할 수 있는 부분들 - 애플리케이션 속성 - 런타임 환경 - 셔플 동작 방식 - 스파크 UI - 압축과 직렬화 - 메모리 관리 - 처리 방식 - 네트워크 설정 - 스케줄링 - 동적 할당 - 보안 - 암호화 - 스파크SQL - 스파크 스트리밍 - SparkR |
Spark 환경을 설정하는 방법은 여러 가지가 있고, 각 설정 방법의 우선순위가 다름 1. 환경 변수 (Environment Variables) • SPARK_HOME, HADOOP_HOME 등의 환경 변수를 설정할 수 있음 • 이 변수들은 Spark의 기본 설치 위치나 Hadoop 관련 설정 등을 지정하는 데 사용됨 우선순위: 가장 낮음. 다른 설정 방법들이 없을 경우 기본값으로 사용됨 2. conf/spark-env.sh 파일 • spark-env.sh 파일은 환경 변수를 설정할 때 사용됨 • 이 파일을 사용하면 Spark 클러스터의 전체 환경을 설정할 수 있음 예를 들어, SPARK_MASTER_HOST, SPARK_EXECUTOR_MEMORY 등 JAVA_HOME : 자바 설치 경로 PYSPARK_PYTHON : 파이썬 바이너리 실행 명령 지정 SPARK_LOCAL_IP : 머신의 IP 주소 지정 SPARK_PUBLIC_DNS : 스파크 프로그램이 다른 머신에 알려줄 호스트명 우선순위: 시스템의 환경 변수 설정이 가장 우선함 3. spark-defaults.conf 파일 • spark-defaults.conf 파일은 기본 Spark 설정을 지정하는 파일 • 이 파일에 설정된 값은 Spark 애플리케이션을 실행할 때 기본값으로 사용됨 우선순위: 환경 변수보다는 높은 우선순위. 이 파일에 설정된 값이 환경 변수에서 지정된 값보다 우선함 4. SparkConf 객체를 사용한 설정 (Spark 애플리케이션 코드 내에서 설정) • Spark 애플리케이션 코드 내에서 SparkConf 객체를 사용하여 설정을 지정할 수 있음 예를 들어, conf.set("spark.executor.memory", "4g") 우선순위: spark-defaults.conf 파일보다는 높은 우선순위 5. spark-submit 명령어 옵션 (위에서 줄줄이 설명한 것들) • spark-submit 명령어를 사용할 때 명령어 옵션을 통해 환경을 설정할 수 있음 예를 들어, --master, --num-executors, --executor-memory 등 • 이 방법은 실행 시점에 특정 설정을 지정할 때 유용함 우선순위: 가장 높은 우선순위. spark-submit 옵션에서 지정한 값이 spark-defaults.conf나 환경 변수에서 지정한 값보다 우선함 종합 우선순위 정리 1. spark-submit 명령어 옵션: 가장 높은 우선순위 2. 애플리케이션 코드 내 SparkConf 설정 3. spark-defaults.conf 파일 4. spark-env.sh 파일 / 환경 변수 5. 기본값: Spark의 기본 설정값 |
17.
Spark 가 Hadoop YARN 을 클러스터매니저로 사용하기 위해 spark classpath (conf/spark-env.sh) 내의 HADOOP_CONF_DIR 변숫값을 아래 두가지 '하둡 환경 설정 파일'이 있는 경로로 지정함 - hdfs-site.xml - core-site.xml 정리하면, HADOOP_CONF_DIR 에 설정된 위치에서 위 두 개의 xml 을 찾을 수 있어야 함 |
"동적 할당 Dynamic Allocation"이란, 애플리케이션 실행 중에 필요에 따라 Executor 개수를 자동으로 조절하는 기능 작업량(workload)에 따라 Executor(=자원)를 추가하거나 제거하여 자원을 효율적으로 사용할 수 있도록 함 다수의 애플리케이션이 하나의 스파크 클러스터가 제공하는 자원을 함께 사용해야 하는 상황에서 유용하게 쓰이는 기법 동적 할당을 사용하지 않는, 기본값은 "정적 할당 Static Allocation" 임 spark job 제출 시 --num-executors 10 이런 식으로, 한 애플리케이션이 고정된 executor(=고정된 자원) 를 이용함 이 경우, Executor 수가 부족할 경우 작업이 느려지고, 불필요하게 많으면 리소스 낭비가 발생함. 하지만 동적 할당을 사용하면, 작업량이 많아질 때 Executor가 자동으로 추가되고, 작업량이 줄어들 때 불필요한 Executor를 제거되어 자원 효율성이 좋아짐. 기본적으로 동적 할당은 false 로, 사용 설정되어 있지 않음 사용하기 위해서 spark.dynamicAllocation.enabled 속성을 true 로 바꾸어야 함 spark-submit \ --conf spark.dynamicAllocation.enabled=true \ # 동적 할당 사용 가능 --conf spark.dynamicAllocation.minExecutors=2 \ # 최소 executor 2개 유지 --conf spark.dynamicAllocation.maxExecutors=50 \ #최대 50개까지 executor 개수 늘리는 게 가능 ... 또한, worker node 에서 '외부 셔플 서비스'를 사용하도록 설정해야 함 spark.shuffle.service.enabled 를 true 로 설정 (외부 셔플 서비스를 사용하면, 익스큐터가 제거될 때 셔플 결과 파일을 삭제하지 않음) 이 말인 즉슨, 외부 셔플 서비스를 사용하지 않으면 executor 가 제거될 때 셔플 결과 파일이 함께 사라진다는 말이 됨 Spark에서 Executor가 제거될 경우, Executor 내부의 Shuffle 데이터도 함께 사라질 수 있기 때문에 External Shuffle Service를 활성화해야 함 (일 하지 않는 executor 가 생겨서 클러스터매니저에 자원을 돌려줄 때 executor 가 사라지기 때문에 이에 따라 shuffle 데이터도 함께 사라지지 않도록) 그럼 남아있는(살아있는) 다른 executor들에서 shuffle 데이터를 그대로 사용할 수 있음 왜 셔플 데이터는 executor 가 사라지면 같이 사라지는걸까? Spark의 기본 설정에서는 Executor의 로컬 디스크(/tmp, spark.local.dir)에 Shuffle 데이터를 저장함 그래서 특정 Executor가 삭제되면, 해당 Executor가 로컬 디스크에 저장한 Shuffle 파일도 함께 삭제됨 이후, 다른 Executor가 같은 Shuffle 데이터를 필요로 하면 재계산(재실행, recomputation) 해야해서 오버헤드가 발생 그럼 external shuffle service 로 셔플 데이터를 다른 곳으로 피신시킬 때 구체적으로 어디에 셔플 데이터를 옮겨놓는 것일까? 일반적으로 각 워커 노드(Node)의 로컬 디스크에 셔플 데이터를 저장해둔다고 함. 즉, Spark의 Executor가 Shuffle 데이터를 자신의 디스크가 아니라 노드의 디스크로 저장함 그럼 노드의 디스크에 저장된 셔플 데이터는 언제 삭제될까? 꽤 많은 방법으로 삭제가 됨 - spark job 이 끝나면 (=driver 프로세스가 종료되면) application ID 가 사라지고, application ID 가 사라지면 ESS 는 셔플 데이터를 삭제할 수 있음 (꼭 ESS 가 독립적인 프로세스 처럼 보이네) - Shuffle 데이터의 TTL 이 걸린 경우, TTL 이 지나서 셔플 데이터가 자동으로 삭제됨 - External Shuffle Service는 일반적으로 디스크 공간이 부족할 때 오래된 Shuffle 데이터를 우선 삭제하도록 동작함. - YARN이나 Spark Cleaner 설정을 통해 주기적으로 정리 가능 (클리너라는 게 있나봐) - ESS 옵션을 false 로 바꾼 뒤 재실행하면 셔플 데이터가 삭제된다고 함 (...) |
Spark의 동적 할당 기능은 내부적으로 Spark의 스케줄러와 External Shuffle Service를 활용하여 Executor의 수를 조절함 < Executor 추가 (Scaling Up)하는 방식 > 작업 대기(Task Queue)가 길어지면, Spark는 현재 Executor가 부족하다고 판단. 클러스터 매니저(YARN, Kubernetes 등)에 새로운 Executor 요청을 보냄. 사용 가능한 자원이 있으면 새로운 Executor가 할당됨. Scaling Up Trigger 조건: 대기 중인 Task가 많고 실행 가능한 Executor가 부족함. < Executor 가 줄어드는 (Scaling Down) 방식 > 특정 Executor에서 더 이상 실행할 Task가 없을 경우, 일정 시간(spark.dynamicAllocation.executorIdleTimeout) 동안 유휴 상태로 남아있음. Executor 의 유휴 상태가 일정 시간 지속되면, Spark는 해당 Executor를 제거하여 리소스를 반환함. Scaling Down Trigger 조건: Executor가 일정 시간 동안 유휴 상태(idle)로 유지됨. |
이렇게, 동적 할당을 사용하면 리소스도 효율적으로 사용 가능하고, executor 개수 관리도 알아서 해주니 좋긴 한데 여느 trade-off 관계나 그렇듯, 단점이 있음 Executor 추가/삭제 오버헤드가 있음. Executor를 추가/제거하는 과정에서 지연이 발생할 수 있음 (근데 이게 단점인가..? static allocation 사용하다가 자원(executor) 부족해서 작업 실행 지연되는 것 보다 훨씬 나은 것 같음) Shuffle 데이터 관리가 필요함. External Shuffle Service를 활성화해야 안정적으로 동작함. 즉각적인 반응 어려움. Task가 즉시 실행될 필요가 있는 경우엔, 동적 할당이 지연을 초래할 수 있음. 따라서 작업 부하가 변동이 심한 작업(실시간 데이터 처리, 배치 처리)에서는 동적 할당을 사용하고, 고정적인 성능이 꾸준히 필요한 작업(머신러닝 학습 등)에서는 정적 할당을 사용 참고로 "동적 할당, 정적 할당"과 "스케줄링 기법(FIFO, Fair, yarn Capacity)"은 서로 독립적인 기법임 (서로 연관이 없음) |
spark 가 task, stage 를 실행할 때 사용하는 scheduling 기법에 대해 알아봄 spark 가 사용 가능한 스케줄링 기법은 FIFO, Fair 두 가지 기본적으로 spark 는 FIFO 스케줄링을 사용함 제출된 잡이 아무리 많아도 FIFO 로 움직임....ㄷㄷ 예를 들어, A user 가 a1, a2 jobs 를 제출하고, 동시에 B user 가 b1, b2 jobs 을 제출했을 떄 (전체 클러스터에 리소스가 아무리 많아도) job 은 a1 하나만 실행되고, a1이 끝나야 a2 이 실행되고, a2가 끝나야 b1이 실행되고, b1 이 끝나야 b2가 실행됨 그래서 이 FIFO 는 단일 사용자 환경에서 사용하는 것임.... 운영에서는 사용하기 힘듦 FIFO 대신 Fair 를 사용할 수 있음 이것은 여러 사용자의 job 을 균등하게 실행하는 스케줄러임 pool 개념을 사용해서, 사용자별 리소스를 공정하게 할당해 줌 그래서 특정 사용자만 리소스를 독점하는 상황이 벌어지지 않도록 함 예를 들어보자. 사용자가 job 을 제출하면, 사용자 기준으로 pool 이 생성됨 (pool = (pool이라는) 같은 그룹으로 묶인 여러 job들의 집합) 이 여러 pool 들에 클러스터의 리소스가 공정하게 분배됨 (사용자가 제출하여) pool 안에 들어있는 job 들도 동일한 리소스를 나눠 갖게 됨 (=pool 내 jobs 들도 공정하게 리소스 받아 실행됨) 그래서 특정 사용자가 많은 job 을 제출해도, 제공받은 리소스가 한정적이기 때문에 다른 사용자의 job과 동일한 비율로 실행됨 이 fair 스케줄링의 단점은, job 이 많아질수록 오버헤드가 증가한다는 것임 여기서 말하는 pool 은, "사용자가 제출한 job이 그룹별로 모여있는 곳"임 예를 들어, A 사용자가 a1, a2 jobs 를 제출했고, B 사용자가 b1, b2 jobs 를 제출했음 A 사용자가 제출한 a1, a2 는 A_Pool 에 모이고, B 사용자가 제출한 b1, b2 는 B_Pool 에 모임 (기본적으로 사용자별로 하나의 pool 이 생성됨. 물론 내가 원하는 pool 에 넣도록 설정할 수 있고, pool 마다 중요도를 달리 줄 수도 있음) A_Pool 에 리소스를 할당하고, B_Pool 에도 동일한 리소스를 할당함 그래서 A_Pool, B_Pool 모두 동시에 동작할 수 있음 (a1, b1 이 동시에 실행되고, a2, b2 가 동시에 실행) pool 내의 job들도 공정하게 리소스 받아서 실행됨 내가 알기론 이게 round robin 방식으로 순서를 정하는 것으로 앎 참고로, YARN 에서 사용하는 스케줄링 기법은 cluster 수준의 스케줄링임(어떤 job에 리소스를 얼마나 줄지 결정할 때 사용) Spark 에서 사용하는 스케줄링 기법은 application 수준의 스케줄링임(tasks 를 어떻게 실행할 지 결정할 때 사용) |
19.
성능 튜닝의 핵심이라면 당연 셔플 처리 시간 단축 코드의 주 언어와 UDF 의 언어 등이 다르게 되면, 데이터 타입과 처리 과정을 엄격하게 보장하기 어려움 위에서 자주 언급되었다시피, |
파이썬 UDF, R 언어 UDF 는 사용하지 않는 게 심신의 안정에 이로움 UDF 를 사용해야 한다면, JVM 언어로 UDF 만들어서 사용 직접 RDD 를 작성하는 것보다 고수준 API(DF, DS, SQL)을 사용하는 게 최적화에 좋음 어쩔 수 없이 RDD 를 사용해야 한다면, RDD 사용 범위를 최소한으로 하자 직렬화가 필요한 부분에서 Java 직렬화 대신 Kryo 같은 직렬화 라이브러리를 사용 spark.serializer 속성을 kyro 로 변경하면 됨 머신 자체의 성능을 모니터링하여 클러스터 설정을 최적화해나가자 스케줄링 모드 변경, resource 제한 등을 통해 최적화를 이룰 수 있음 팀이 운영하는 Spark 에서 데이터를 여러번 읽을 수 있기 때문에 데이터를 애초에 효율적으로 읽을 수 있도록 저장 데이터는 csv, parquet, gzip 처럼 분할이 가능한 포맷을 활용해야 함. 왜냐면 여러 태스크가 파일의 서로 다른 부분을 동시에 읽고 병렬처리 할 수 있기 때문. json, tar, zip 처럼 분할이 불가능한 포맷을 사용하면, 단일 머신에서 json 전체파일을 읽어야하기 때문에 병렬 처리를 할 수 없어 효율이 떨어짐 분할된 파일 크기가 몇 백 메가바이트 정도 될 정도로 분할하면 된다고 함 데이터 저장 방법에는 best practice 가 있으니 이를 참고하자 테이블에서 자주 사용하는 컬럼을 기준으로 파티셔닝하면 읽기 효율이 좋아짐 필요하지 않는 키 값을 읽지 않을 수 있으니까 버켓팅을 사용하면 데이터를 한두 개 파티션에 치우치지 않고 전체 파티션에 고르게 분산시킬 수 있음 게다가 셔플을 미리 방지할 수 있음 |
스파크는 워크로드에 따라 job 에서 필요한 자원을 동적으로 조절 가능 '동적 할당'은 애플리케이션이 진행되는 중간에 스파크 애플리케이션이 익스큐터를 요청하고 제거할 수 있는 방식 애플리케이션이 자원이 사용 가능해질 때 자원을 가져다 쓰고 필요하지 않을 때 자원을 되돌려 주기 때문에 클러스터에서 성능을 끌어 올릴 수 있음 참고 https://exmemory.tistory.com/92 |
많은 수의 크기가 작은 파일 처리 - 많은 수의 데이터 파일 찾아 읽기 태스크 실행 - 네트워크와 잡 스케줄링 부하 - 병렬처리성 올라감 적은 수의 크기가 큰 파일 처리 - 스케줄링 부하가 덜 함 - 태스크 실행 시간 길어짐 - 병렬처리성 떨어짐 적은 수의 크기가 큰 파일 처리하는 경우, 입력 파일 수보다 더 많은 태스크 수를 설정해 병렬성 높일 수 있음 왜냐하면 스파크는 분할 가능한 파일 포맷을 사용한다고 간주하고 여러 태스크에서 처리할 수 있도록 크기가 큰 파일을 알아서 분할하기 때문 (input partition) |
자바/스칼라 UDF 사용시, 데이터를 JVM 객체로 변환하고 쿼리에서 레코드당 여러 번 수행되므로 성능이 좋지 않음 (파이썬 UDF 는 말 할 것도 없이 더 좋지 않음) RDD 캐시 : 물리적으로 데이터(bit 값)를 캐시에 저장 구조적 API 캐시 : 물리적 실행 계획을 저장 RDD cache() : 저장소는 MEMORY_ONLY RDD persist() : 파라미터로 받은 곳을 저장소로 사용 persist 실행시, job 이 끝나도 메모리에 데이터가 상주해있음 따라서 unpersist 로 해제해야 함 캐시를 직렬화하여 저장 가능한데, 직렬화하여 캐싱하게 되면 공간 효율성은 좋지만 CPU 를 더 소모함 캐시는 데이터를 재활용하는 코드에서는 좋지만, 캐싱할 때 직렬화/역직렬화를 하기 때문에 성능이 저하되는 부분이 있음 |
파케이 포맷이 좋은 이유는, 쿼리에서 사용하지 않는 데이터를 빠르게 건너 뛸 수 있기 때문 (projection pushdown, predicate pushdown) 스파크는 파케이 데이터소스를 내장하고 있어서 파케이 포맷과 호환이 잘 됨 분할이 가능한 파일 포맷(파케이, gzip 등)을 사용해야 읽기 작업시 모든 코어를 활용할 수 있어 병렬성이 올라감 분할 불가능한 파일 포맷(json, zip, tar 등)은 단일 머신에서 전체 파일을 읽어야 하므로 병렬성이 떨어짐 |
스파크 익스큐터 내 task 에서 셔플이 일어나면 익스큐터 내 disk 에 셔플 결과가 쌓이고 다른 노드에서 해당 결과를 가져가는데(pull) 만약 셔플 결과를 쌓는 task 가 죽었다면, 셔플 결과까지 사라짐 이런 경우를 방지하기 위해, 셔플 결과는 익스큐터 외부에 있는 곳에 쌓아두어 불의의 사고로 task 가 죽어도 셔플 결과는 안전할 수 있도록 함 그래서 셔플이 다시 일어나지 않도록 하여 성능을 향상시킬 수 있음 (아래 이미지 참고) |

아래부터는 Udemy 에 있는
Apache Spark 와 Scala로 빅 데이터 다루기 강의 필기
rdd 는 spark context 를 사용하여 만들 수 있음
rdd 는 resilient distributed dataset 이며 여기서 말하는 dataset 은 Spark 의 API 중 하나인 DataSet 을 의미하는 게 아님
spark context 로 local, s3, hdfs 등의 데이터를 읽는 방법
sc.textFile("filte:///home/eyeballs/sample.txt")
sc.textFile("s3n://a/b/c.txt")
sc.textFile("hdfs:///Cluster/user/eyeballs/sample.txt")
그 외 Hive, HBase, Cassandra, JDBC 등 다양한 곳의 데이터를 읽고 rdd 로 만들 수 있음
rdd 로 하는 것은 다음과 같음
map, flatmap, filter, distinct, sample, union, intersection subtract, cartesian 등
- 스파크가 하둡보다 나은 점
ㄴ 대화형 쉘 지원
ㄴ 다양한 함수 지원(Map Reduce 를 포함하여 집계함수나 MR, Streaming 등)
ㄴ in memory, cache, 카탈리스트 엔진 등을 통한 작업 속도 향상
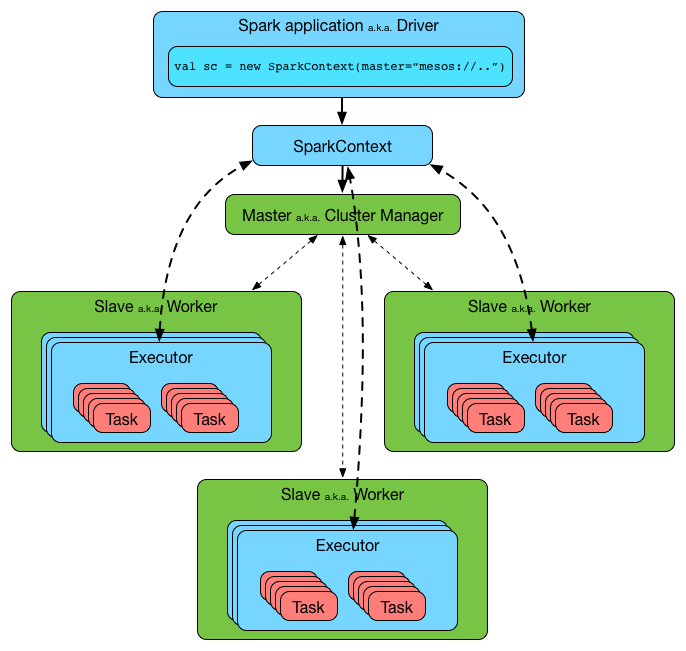

- 위의 그림을 참고.
하나의 노드 위에서 여러개의 executor 가 실행될 수 있지만, 하나의 executor 가 여러 노드에 걸쳐있을 순 없다.
하나의 데이터 파티션은 하나의 executor 위에서 처리되지만, 여러 executor 위에서 처리될 순 없다.
하나의 executor 가 갖는 core 수에 따라 파티션을 받고, 그 수 만큼 병렬 처리 할 수 있다.
한 번 생성된 executor 는 애플리케이션이 끝날 때 까지 남아있다.
spark 에서 캐싱한 RDD 등은 executor 위에 남아있는다.
- 하나의 어플리케이션은 하나의 SparkSession 을 만든다. 즉, 하나의 어플리케이션 = 하나의 Spark Session
- 데이터가 물리적으로 여러 컴퓨터에 나뉘어져 있는 것이 파티션(청크)
- 카탈리스트 : 실행 계획 수립이나 처리에 사용하는 자체 데이터 타입 정보를 갖고 있는 엔진.
python 이나 R 등으로 구조적 API 를 사용해도, 카탈리스트가 내부적으로 스파크 데이터 타입으로 변환하여 명령을 효율적으로 처리.
- Dataframe 은 Row 타입으로 구성된 Dataset임.
Row 타입은 자체 데이터 포맷을 사용하기 때문에, Garbage collector 나 객체 초기화 부하가 있는 JVM 데이터 타입 사용 안 함.
따라서 매우 효율적인 연산이 가능.
- API 실행 과정
0. 코드
1. 논리적 실행 계획 : 카탈리스트 옵티마이저가 사용자의 코드에서 최적화 할 수 있는 부분을 찾아 최적화
2. 물리적 실행 계획 : 논리적 실행 계혹이 실제 클러스터에서 실행하는 방법을 정의. 비용 모델을 비교하여 최적의 전략 선택.
이 과정에서 사용자 쿼리를 RDD 트랜스포메이션으로 컴파일함.
3. 실행 : RDD 를 대상으로 코드 실행
- 브로드캐스트 변수 : 모든 task 에서 볼 수 있는(공유되는) 불변값. 직렬화/역직렬화 하지 않아서 큰 데이터 공유하는 데 효율적임.
- SparkSession : 저수준 API, 기존 컨텍스트, 관련 설정 정보 등에 접근 가능.
df, ds 를 생성하거나, 사용자 정의 함수 udf 를 등록할 때 사용.
SparkContext : SparkSession 으로 접근 가능. 스파크 클러스터에 대한 연결을 나타냄.
App Name 이나 현재 worker nodes 위에서 돌고있는 executor 의 메모리 크기, 코어 수 등의 정보를 갖고 있음
RDD 같은 저수준 API, 브로드캐스트 변수 등을 사용 가능.
- 실행 계획 : job > stage > task
ㄴ job : action 에 의해 생성. action 이 2개면 job 2개 생성됨. 여러 stages 로 구성됨
ㄴ stage : 넓은 transformation 에 의해 생성. 다수의 머신에서 동일한 연산을 수행하는 여러 tasks 의 그룹.
하나의 stage 내에 tasks 들은 모두 같은 일을 하며, 병렬 처리 한다.
따라서 stage 1 이 끝나고 난 뒤에야 stage 2 가 시작된다.
ㄴ task : 단일 익스큐터에서 실행할 데이터의 블록과 다수의 좁은 transformation 의 조합.
파티션 개수에 따라 task 가 만들어짐. 만약 파티션이 5개면 5개의 task 가 만들어져서 5개가 병렬 실행됨.
병렬 처리되는 모든 task 는 서로 다른 데이터를 대상으로 동일한 코드를 실행한다.
- DAG 에서 각 job 의 스테이지 그래프를 만들고, 각 task 가 실행될 위치를 결정한다.
- action 에 의해 실행되는 job 은 하나의 DAG 를 만든다.
액션이 한 번 호출된 이후에는 더 이상 DAG 에 추가 안 됨.
- spark 가 빠른 이유는, in memory 를 사용하기 때문도 있지만,
코드 최적화 ( 좁은 transformation 을 파이프라인으로 뭉쳐서, IO 없이 한 번에 처리 ) 가 잘 되기 때문도 있다.
- Spark 에서 셔플이 발생하면, ( 사용자가 직접 캐싱하지 않아도 ) 셔플 결과가 디스크에 저장되어진다.
나중에 재사용 할 일이 생기면, 셔플 결과를 다시 가져와서 사용한다. 마치 캐싱 한 것 처럼!
- 잡 스케줄링을 할 수 있다.
스파크 애플리케이션에서 별도의 스레드를 사용해 여러 job을 동시에 실행 가능하다 ( 스레드 안정성은 보장 ).
기본적으로 FIFO 큐를 사용하며, head 부분의 job이 전체 자원을 사용하지 않는다면, 남은 자원은 두번째 job 이 사용하여 병렬 처리 가능하다.
FIFO 처럼 순서대로 처리할 수 있고, 또 round robin 방식을 사용할 수 있다. 이것을 fair scheduler 라고 한다.
긴 job이 오면 처리하다가 짧은 job 이 오면 잠깐 자원을 줘서 실행시키고 다시 긴 job 을 처리하는 방식.
- 정적 할당 : 하나의 클러스터에서 여러 스파크 애플리케이션을 실행하려면,
실행될 애플리케이션을 위해, 클러스터가 갖고 있는 제한적인 자원을 최대한 할당해줌.
자원을 갖고 있는 애플리케이션이 끝나야 다음 애플리케이션이 실행됨.
- 동적 할당 : 하나의 클러스터에서 여러 스파크 애플리케이션을 실행하려면,
워크로드에 따라 애플리케이션이 점유하는 자원을 동적으로 조정해야 함.
애플리케이션이 사용하지 않는 자원을 클러스터에 반환하고 필요할 때 다시 요청하는 방식. 필요할 때 받고 다 쓰면 반납
다수의 애플리케이션이 하나의 스파크 클러스터 자원을 공유하는 환경에서 유용함.
- 스파크의 모든 executor는 JVM (자바 가상 머신)을 하나 실행한 후 그 위에서 실행된다.
- 스파크 드라이버에서 모든 애플리케이션의 상태가 보관되며, 안정적으로 실행 중인지 확인 가능하다.
- RDD 캐싱 : 물리적 데이터(bit 값 그 자체)를 캐시(executor 의 ram)에 저장
구조적 API 캐싱 : 물리적 실행 계획을 캐시(executor 의 ram)에 저장
- 캐싱 레벨로 Memory_only 를 사용할 때, JVM(executor) 에 할당된 메모리보다 RDD 크기가 크면, 캐싱을 하지 않는다.
- RDD 는 executor 혹은 slave node 위에 저장된다. 애플리케이션이 동작하는 동안 로드된 RDD 는 executor 노드의 메모리 위에 있다.
- executor 는 캐싱과 실행을 위한 공간을 각각 갖고 있는 JVM 이다!
- 파티션이 중간에 유실되어도, RDD 재계산에 필요한 종속성 그래프에 대한 충분한 정보를 통해 빠른 복구가 가능하다.
- 넓은 transformation 이후에 파티션 개수가 따로 지정되어있지 않다면, spark.default.parallelism 으로 직접 파티션 개수 지정이 가능하다.
- 각 executor 에 얼마만큼의 cpu cores 를 할당하는 게 좋은가?
물론 컴퓨터 환경마다 다르겠지만, 일단 책의 내용은 아래와 같다.
각 노드가 갖고 있는 cpu cores 를 5로 나눈 몫만큼 각 노드에 executor 를 설정한다.
즉, 노드마다 5개 cores를 갖는 executor 가 최대한 들어가게 만든다.
(샌디 라이자가 말하길, executor 당 코어는 최대 다섯 개 정도가 좋다고 함)

- cluster manager 가 할당한 memory 자원으로 executor 가 만들어지면, executor 는 위와 같이 ram 을 구별하여 사용한다.
1. overhead : 어디에 쓰이는 건지는 아직 모르겠지만, 아무튼 필요함. 얼마만큼 필요한지 계산하는 방법은 아래 적어둠
2. M 영역 : executor 가 갖고 있는 전체 memory 에서 overhead 를 제외한 부분.
실행(transformation)과 캐싱을 위한 공간. 기본 값은 60%이며, 늘리거나 줄일 수 있음.
3. 실행 영역 : transformation 을 처리하기 위한 공간
4. R : 캐싱된 파티션을 저장하기 위한 공간. 캐싱된 파티션이 비어있으면 이 공간을 실행 영역으로 사용할 수 있다고 함(위에 그림처럼)
(연산이 많지 않다면) R 을 벗어나 실행 영역으로 캐싱 파티션을 저장 가능하지만,
연산이 많아지게 되면, 연산에 실행 영역을 보장해줘야 하므로 가장 오래 전에 사용된 캐싱 파티션을 제거한다(LRU)
- 각 executor 가 실행할 때의 memory overhead : Max ( 요청한 executor 메모리의 n % , 기본 오버헤드 값(384mb) )
여기서 n % 는 default가 10 % 인데, 내가 맘대로 수정 가능.
yarn container 에서 executor 를 실행한다고 할 때, yarn 의 memory 가 executor 에서 요청한 메모리+overhead 보다 커야 한다.
- executor 의 memory M 공간 계산 하는 방법
M = spark.executor.memory * spark.memory.fraction
(M = 전체 executor memory * M에 할당된 비율)
- executor 의 memory R 공간 계산 하는 방법
R = spark.executor.memory * spark.memory.fraction * spark.memory.storageFraction
(R = 전체 executor memory * M에 할당된 비율 * R에 할당된 비율)




https://blog.cloudera.com/how-to-tune-your-apache-spark-jobs-part-2/
https://data-flair.training/blogs/spark-tutorial/
https://shelling203.tistory.com/33
'Spark' 카테고리의 다른 글
| [Spark Steaming] kafka 를 이용하여 Data pipeline 만들어보기 (1) | 2020.03.23 |
|---|---|
| [Spark Streaming] HDFS 를 이용하여 Data pipeline 만들어보기 (0) | 2020.03.20 |
| [Spark] SparkSession 이란? (0) | 2020.02.21 |
| [Spark] executor 개수 늘리는 방법 (0) | 2020.02.15 |
| [Spark] MongoDB connector for Apache Spark 웨비나 링크 (0) | 2020.02.05 |