databricks 의 Adaptive Query Execution: Speeding Up Spark SQL at Runtime 을 기반으로 함.
해당 포스트는 위 링크의 내용을 (모자란 실력이나마) 한글로 풀어 쓴 것에 다양한 추가 내용을 덧붙인 것임.
모자란 부분이나 잘못된 내용이 있으면 덧글로 알려주세용.
해당 포스트 내용의 출처는 가장 아래 '참고'에 있음.
이탤릭 처리 되어있는 것은 필자의 주관이므로 그냥 넘겨도 무방.
Adaptive Query Execution 을 이하 AQE 라고 부름.
Spark 에는 최적화 기능들(optimizer) 을 갖추고 있다.

1.x 버전에서는 Rule-Based Optimizer 만 갖고 있었다.
2.x 버전에서 Cost-Based Optimizer 가 추가되었다.
최근에 업데이트 된 3.x 버전에는 Runtime 에 동작하는 Optimizer 가 추가되었는데
그것이 바로 이 포스트에서 설명하는 Adaptive Query Execution(AQE) 이다.
AQE 는 Spark 버전이 3.x 로 올라가면서 새롭게 추가된 기능 중 하나임.
Stage 는 한 차례 마무리 되고 그 다음 Stage 가 동작하기 전,
데이터 파이프라인이 끊기고 실행을 멈춘다.
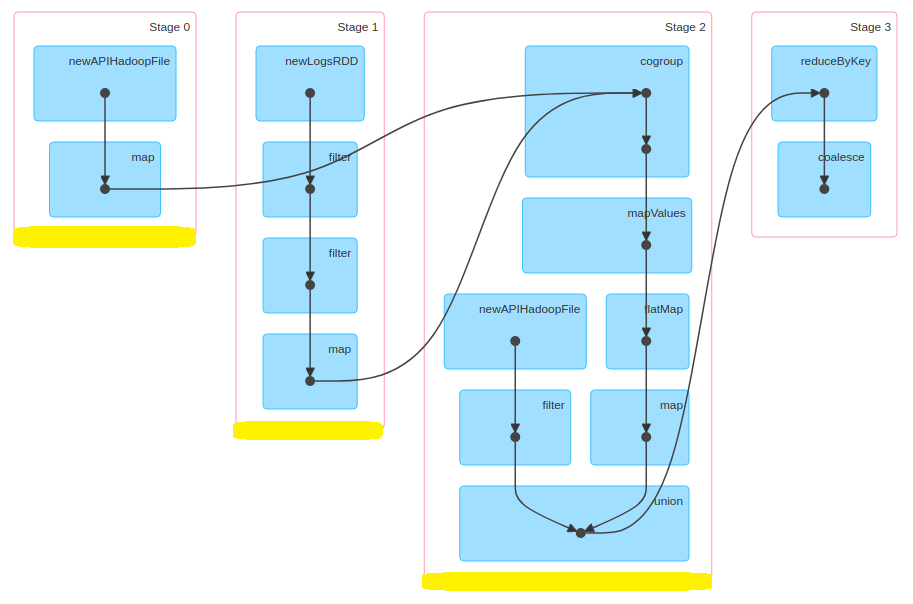
그리고 중간 결과물을 구체화(materialization)하고, 해당 스테이지의 병렬 처리가 완벽하게 끝난 후에야
다음 스테이지를 동작시킨다.
이 때를 "materialization points" 라고 부르는데, 이 포인트가 '다시 최적화'(reoptimization)를 할 기회이다.
이 최적화는 통계치를 바탕으로 런타임에 진행된다.
(reoptimization은 모든 파티션들에 대한 데이터 통계값들이 '사용 가능'하고, 다음 스테이지 연산을 시작하기 전에 가능)


AQE 는 세 가지 기능으로 제공된다.
- 동적 셔플 파티션 통합 Dynamically coalescing shuffle partitions
- 동적 전환 조인 전략 Dynamically switching join strategies
- 스큐 조인을 동적으로 최적화 Dynamically optimizing skew joins
< 동적 셔플 파티션 통합 Dynamically coalescing shuffle partitions >
셔플은 네트워크를 통해 데이터를 교환하기 때문에 매우 비싼 연산이다.
이 셔플의 주요 속성 중 하나는 셔플 파티션 개수이다.
셔플 파티션 수가 너무 적으면, 각 셔플 파티션 당 데이터 크기가 커진다.
큰 데이터는 executor 의 ram 을 벗어나는 상황을 만들 가능성이 있고
(벗어나게 되면 디스크를 이용하여 연산을 해야 함)
적은 셔플 파티션 개수에 의해 병렬성이 떨어지므로 처리 속도가 떨어진다.
반대로 셔플 파티션 수가 너무 크면, 각 셔플 파티션 당 데이터 크기가 작아진다.
셔플 파티션의 메타 데이터를 보관하는 스파크 드라이버에 부담이 커지고(Drive memory errors, Drive overhead errors)
각 셔플 파티션을 스케줄링 하기 위한 비용이 커지고,
작은 크기의 데이터들을 생성하기 위한 IO가 많이 발생하기 때문에 처리 속도가 떨어진다.
영어 설명 :
Too small shuffle partitions # : GC pressure; disk spilling
Too large shuffle partitions # : Inefficient I/O; scheduler pressure
(https://www.slideshare.net/databricks/whats-new-in-the-upcoming-apache-spark-30)
위와 같이 파티션에 의한 단점이 있기 때문에 적절한 수의 파티션을 결정하는 것이 좋다.
(대부분 처음에는 파티션 수를 많이 잡아둔 후, 결과 통계치를 보고 파티션 수를 줄이면서 조절한다고 한다.)
AQE 는 셔플 통계를 보고,
런타임에 많은 수의 작은(samll size) 셔플 파티션들을 합쳐 하나의 큰 파티션으로 뭉쳐주는 기능을 제공한다.
기존의 방식으로 셔플을 진행하면, 아래 그림과 같이 5개의 셔플 파티션이 생기고 각 파티션마다 크기가 달라질 수 있다.

AQE 는 (reoptimization 타임에) 작은 크기의 셔플 파티션들을 합쳐주어,
5개의 작업이 아닌 3개의 작업만 할 수 있게 하여 처리 속도를 올릴 수 있다.
리듀서가 줄어드는 효과를 갖는다.

(내 생각이지만, 결과 파티션 크기가 작다고 죄다 합쳐버리지는 행동은 하지 않을 것이고,
다른 파티션들과 비교하여 비슷한 수준으로 (작은 파티션들을) 합쳐줄 것 같다.
이 기능이 제공하는 것은 shuffle partition 개수 조절, 균등한 partition 생성, Reducer 개수 줄이기 인 듯.
영어 설명에 따르면, Automatically coalesce partitions if needed after each query stage
각 쿼리 스테이지가 끝난 후 '필요시' 자동으로 파티션들을 합쳐준다고 함.
https://www.slideshare.net/databricks/whats-new-in-the-upcoming-apache-spark-30)
< 동적 전환 조인 전략 Dynamically switching join strategies >
Spark 는 여러가지 조인 전략을 지원한다. 브로드캐스트 해시 조인, 소트 머지 조인 등.
한 차례 셔플이 끝난 뒤 Reoptimization 을 할 때,
조인 전략이 바뀌어 더 높은 성능을 낸다는 결론이 나오면 조인 전략이 바뀐다.
구체적으로 말하자면, 어떤 조인에서 브로드캐스트 해시 조인으로 조인 전략이 바뀐다.
왜냐면 브로드캐스트 해시 조인이 셔플을 사용하지 않아서 성능이 좋거든.
아래 그림처럼, 처음 논리적 실행 계획은 Sort Merge Join 을 계획했지만,
(조인 관계의 예상 크기가 브로드캐스트 크기 임계값보다 작다는 것을 판단한 뒤) 브로드캐스트 조인이 낫다고 판단하여
Reoptimization 을 할 때, 조인 전략을 브로드캐스트 해시 조인으로 바꿀 수 있다.
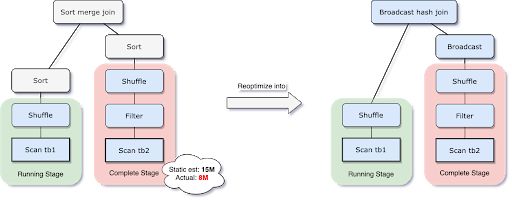
조인 전략을 바꿔 최적화 함으로써
셔플을 피하는 브로드캐스트 해시 조인을 사용할 수 있게 되었고
이에 따라 네트워크 트래픽을 줄이는 등의 이점을 보게 된다.
(브로드캐스트 해시 조인 참고 https://eyeballs.tistory.com/247)
< 스큐 조인을 동적으로 최적화 Dynamically optimizing skew joins >
파티션 하나에 데이터가 몰려있는 상황을 skew 되었다(데이터가 쏠려있다)라고 한다.
skew 파티션으로 조인을 진행하는 예를 들어보자.

테이블 A와 테이블 B를 서로 조인하는 상황이고, 테이블 A의 A0 파티션에 데이터가 몰려있다(skew)
A와 B를 조인하는 과정에서 A0와 B0가 조인하는 시간이 A1,2,3 와 B1,2,3 가 조인하는 시간보다 오래 걸리므로 처리 속도가 떨어진다.
또한 skew 데이터는 disk spill 과 oom 을 불러일으킬 수 있다.
AQE 는 이러한 skew 데이터를 감지하고, skew 데이터를 더 작은 하위 파티션으로 나눈다.

예제에서는 A0 를 A0-0 와 A0-1 로 나누었다.
나눈 수 만큼 B0 도 복제한다. 그 뒤 서로 조인을 진행한다.
이렇게되면 A0과 B0의 조인 시간이 줄어들고 전체적인 처리 속도가 향상된다.
(내 생각. 블로그 설명에는 없지만, 나눌 때 두 개 이상으로 나눌 수도 있을 것 같다.
나누거나 복제하는 오버헤드도 있지 않을까 싶은데..?)
개발자가 신경쓰지 않아도 AQE 가 제공하는 내부적인 최적화 기술들이 적용되므로
개발자의 일거리를 덜어주어 효율적인 작업이 가능하다.
가장 위에 링크에 들어가보면, 마지막에 AQE 를 적용하는 방법(Enabling AQE 부분)에 대해서도 간략하게 나온다.
나중에 직접 해보고 이 포스트에 덧붙여 업데이트 하겠음.
Spark 3.x 이후 버전에서 SQL config 에 spark.sql.adaptive.enabled 을 true 로 세팅하면 AQE 를 사용할 수 있다.
AQE 를 적용하기 위해 SparkSession configuration 의 아래처럼 세팅한다.
spark.conf.set("spark.sql.adaptive.enabled", "true")
셔플 파티션 최적화를 사용하려면 아래처럼 세팅한다.
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
혹은 spark-defaults.conf 에 위의 값을 넣어도 됨.
구체적인 옵션 값은 아래 공식 문서를 참고한다.
https://spark.apache.org/docs/latest/sql-performance-tuning.html#adaptive-query-execution
https://github.com/Intel-bigdata/spark-adaptive
참고
https://jaceklaskowski.gitbooks.io/mastering-spark-sql/spark-sql-adaptive-query-execution.html
https://blog.knoldus.com/adaptive-query-execution-aqe-in-spark-3-0/
https://spark.apache.org/docs/latest/sql-performance-tuning.html#adaptive-query-execution
https://github.com/Intel-bigdata/spark-adaptive
https://www.slideshare.net/databricks/whats-new-in-the-upcoming-apache-spark-30
'Spark' 카테고리의 다른 글
| [Spark3] Dynamic Partition Pruning (1) | 2020.07.15 |
|---|---|
| [Spark] Broadcast Hash Join 간단한 설명 (0) | 2020.07.15 |
| [Spark3] 버전 3 새로운 기능 설명 및 링크 (0) | 2020.07.15 |
| [Spark] 아파치 스파크 기본 설명 링크 (0) | 2020.07.15 |
| [Spark] Dataframe 만드는 여러가지 방법 링크 (0) | 2020.03.26 |