Continue from below posting.
https://eyeballs.tistory.com/m/729
| SQL 데이터베이스와 NoSQL 데이터베이스의 주요 차이점은? |
구조: SQL 데이터베이스는 구조화된 스키마를 사용하는 반면, NoSQL 데이터베이스는 스키마가 없거나 유연한 스키마를 사용 확장성: SQL 데이터베이스는 scale-up 이 더 용이한 경우가 많고, NoSQL 데이터베이스는 일반적으로 scale-out 이 더 용이함 데이터 모델: SQL 데이터베이스는 테이블과 행을 사용하는 반면, NoSQL 데이터베이스는 document, Key-Value 또는 그래프와 같은 다양한 모델을 사용할 수 있음 ACID 준수: SQL 데이터베이스는 일반적으로 ACID를 보장하는 반면, NoSQL 데이터베이스는 성능 및 확장성을 위해 일부 ACID 속성을 희생할 수 있음 |
| 정규화와 비정규화 차이? |
정규화 : 데이터 중복을 최소화하여 무결성을 높이는 과정 삽입,삭제,수정 이상(Anomaly)을 없애기 때문에, 무결성이 높아짐 join 쿼리가 필수이므로 쿼리 성능은 높지 않음 정규화를 진행하면, 테이블들을 최대한 나누고, 각 테이블들을 외래키를 통해 연결 비정규화 : 성능 향상을 위해 의도적으로 데이터를 중복시켜 조회 속도를 높이는 과정 비정규화를 진행하면, 테이블들을 최대한 결합 https://eyeballs.tistory.com/m/504 |
| 저장 프로시저(stored procedure)란? |
저장 프로시저는 데이터베이스에 저장되고 한 번의 호출로 실행될 수 있는 미리 컴파일된 SQL 문 모음 매개변수를 받아 복잡한 연산을 수행하고 결과를 반환할 수 있어 성능 향상과 코드 재사용성 증대에 기여 마치 import 하여 사용할 수 있는 함수같음 https://eyeballs.tistory.com/m/504 |
| 람다 아키텍처란? |
실시간으로 데이터 확인하기 위해 (결과는 부정확하지만) 데이터 스트림 처리를 하는 부분을 만들고 똑같은 데이터를 배치 데이터 플로우로 처리하여 나중에 일, 월 등의 긴 주기를 갖고 배치처리 한 결과를 정확한 결과로 보는 것 배치 처리 결과는 서빙레이어라는 부분에 모여서 사용자에게 서빙됨 배치 결과가 나오기 전까지, 스트리밍으로 처리된 결과는 참고용으로 볼 수 있음 람다 아키텍처의 단점은 같은 로직을 두 번 사용(스트림에서 한 번, 배치에서 또 한 번)한다는 것임 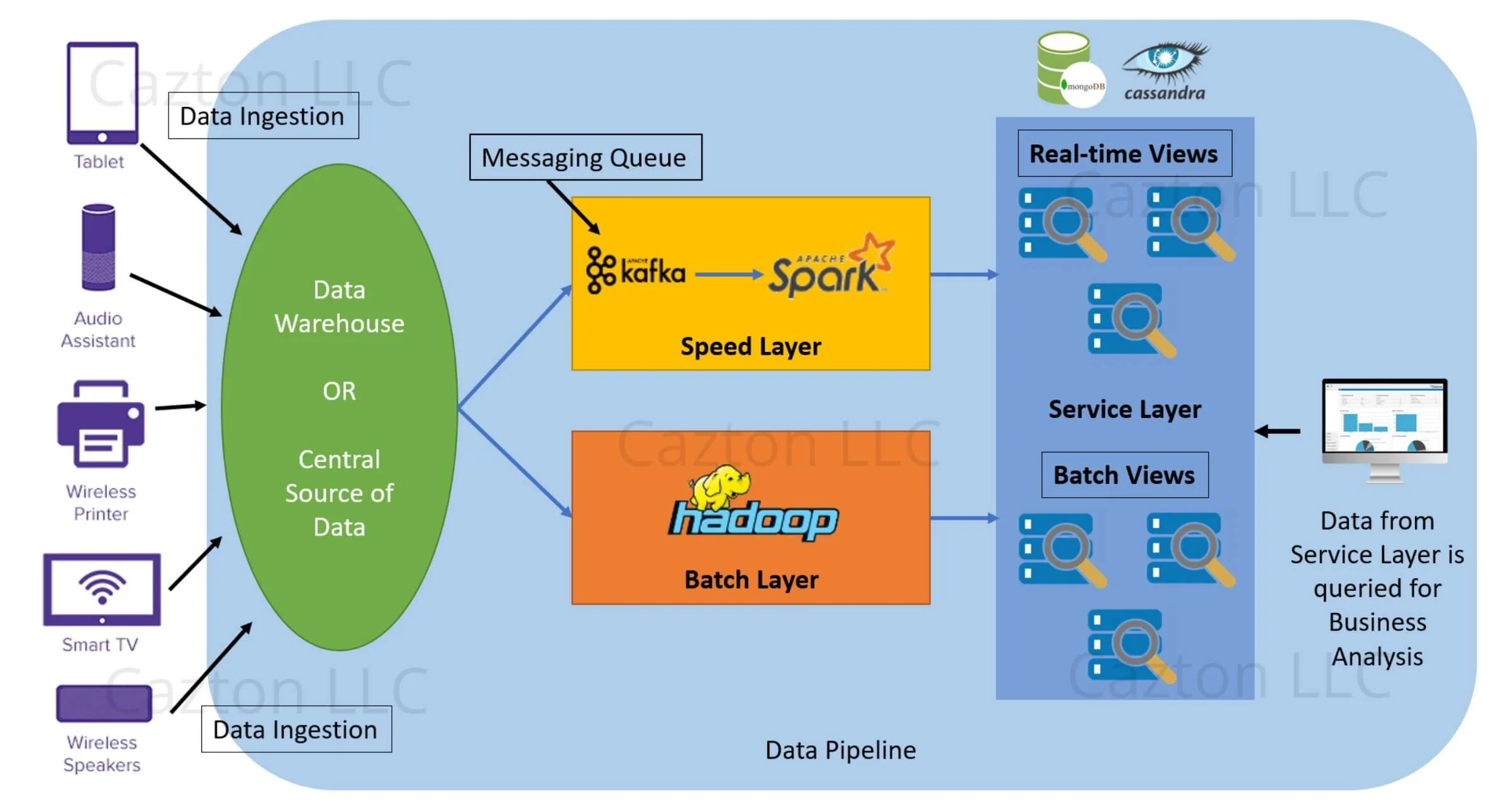 람다를 대체하기 위해 카파 아키텍처를 선택할 수 있음 카파 아키텍처는 배치와 서빙 레이어를 완전히 없애고 스트리밍 부분만 남긴 것 kafka 에 데이터 쌓아두는 기간을 늘림 과거 데이터를 재처리하고 싶다면, kafka 로부터 다시 읽음 카파의 단점은 부하가 급격하게 높아질 수 있다는 것 예를 들어 재처리를 위해 과거 한달 데이터를 한 번에 보내면 스트리밍 처리에 부하가 높아질 수 있음 https://eyeballs.tistory.com/m/574 https://eyeballs.tistory.com/m/720 |
| 데이터 파이프라인에서 진행 가능한 테스트 방법들 |
- 개별 구성 요소에 대한 단위 테스트 - 구성 요소들이 서로 제대로 작동하는지 확인하기 위한 integrity 통합 테스트. 각 구성 요소들의 interface 가 잘 연결되는지 확인 - 전체 파이프라인에 대한 엔드투엔드 테스트 - 데이터 무결성을 보장하기 위한 데이터 유효성 검사 테스트 - 무결성 테스트 - 정합성 테스트 - 이슈 테스트 - 다양한 부하 조건에서의 성능 테스트 - 오류 처리 검증을 위한 오류 주입 테스트 - 변경 후 회귀 테스트 |
| 데이터 양이 갑자기 증가하는데 수직적, 수평적 증가가 불가능한 상황에서 데이터 양이 증가하면 어떻게 대응 할 것인가? 즉, 데이터 양은 증가하지만 추가 리소스를 사용할 수 없는 상황 |
스파크 리소스를 늘릴 수 없다면, ‘처리해야 할 데이터의 양’과 ‘재처리 범위’를 줄이고 ‘파이프라인의 성격’을 바꿔야 함 파이프라인: MySQL → binlog (CDC) → Spark → Lakehouse 제약: 리소스를 더 추가할 수 없는 상황 목표: 데이터 파이프라인의 안정성을 유지하고, 작업 실패나 이슈 등 방지 핵심 질문은: “정말 10배 데이터를 ‘똑같이’ 처리해야 하는가?” 1. 가장 먼저 해야 할 것: CDC 범위 줄이기 (CDC 대상 컬럼 / 테이블 재검토) MySQL 데이터가 10배 늘었다고 해서, 그 모든 데이터가 가치 있지 않을 수 있음 확인해야 할 질문:
입력 데이터 자체를 줄이는 게 가장 큰 효과 2. Append-only + Incremental 처리 강제 여기서 append-only 란, 일단 append 로 저장하고 추후 재처리를 진행. Hudi upsert 진행시, 덮어쓰기 위한 데이터를 찾는 과정에서 partition 을 찾을 수 없다면 full scan 이 발생하게 되므로 엄청난 오버헤드가 발생함 따라서, Hudi upsert 스캔에서 full scan 방지를 위해 반드시 partition pruning 되어야 함 Partition 전략 재설계 (필수) ❌ 잘못된 예: partition = ingestion_date ➡️ 하루에 10배 → 하루 partition 하나 → hotspot ✅ 개선: partition = event_date or partition = (event_date, hash(user_id)) 👉 “한 배치가 건드리는 파일 수”를 줄이는 게 핵심 event_time 으로 파티셔닝하게되면, late-arriving data 처리는 (일단은) 생략되어 데이터양이 줄어듦 late-arriving data 는 나중에 다시 처리하면 됨 3. Spark 작업 자체를 가볍게 만들기 Spark executor 못 늘리면, executor가 할 일을 줄여야 함 Shuffle 최소화
Task 수 줄이기
CDC 이벤트 정규화 (중요) MySQL binlog는 종종:
해결
4. “실시간에 가깝게”에서 “지연 허용”으로 전환 리소스 고정이면 선택지는 둘 중 하나: 1. Throughput 을 유지하는 걸 선택. 그럼 Latency 는 포기해야 함 2. Latency 를 유지하는 걸 선택. 그럼 데이터가 누락되거나 작업이 실패할 수 있음 따라서, 현실적으로 "지연 허용 + 안정성 유지" 를 선택해야 함 방법
5. “절대 하면 안 되는 대응” (면접에서 말하면 감점) “Spark executor 더 달라고 요청한다” “지금은 어쩔 수 없다” “하드웨어 증설이 답이다” 면접관이 듣고 싶은 말: “리소스는 고정되어 있으니, 저는 파이프라인의 성격을 바꾸겠습니다.” 이 질문에서 면접관이 진짜 보고 싶은 것 - 데이터 엔지니어링 관점 - 시스템 트레이드오프 이해 - 현실적인 판단 - 리소스 제약 하 설계 |
데이터가 10배로 들어오는 상황에서 리소스를 늘릴 수 없을 때, 내가 생각한 방법 - 들어오는 데이터는 일단 모두 lake house 에 넣고, lakehouse 에서 한 번의 배치가 건드는 데이터 범위를 제한. 여기서 lake house 는 s3 처럼 무한한 저장 공간을 갖는다는 전제임 - 데이터 처리 병목 지점을 프로파일링해서 해결해야 함. 셔플 사이즈 이슈, IO 이슈 등이 발생할 가능성이 높음 - 데이터 처리하는 코드를 튜닝해야 함. 이를테면, 파티션 사이즈를 조절한다던지(AQE 등), 셔플을 최대한 줄일 수 있도록 broadcast join 을 활용한다던지(dimension table이 충분히 작아야 함), repartition 대신 coleasce 를 사용하고 groupbykey 대신 reducebykey 를 사용한다던지, skew 발생을 막기 위해 skew join hint 등을 사용한다던지. 물론 이것들은 '데이터양이 늘어났을 때 대책'이 아니라 일반적인 튜닝 방법임. 이걸 미리 해둬야 함 - 데이터양이 많아졌기 때문에, 읽는 데이터 양을 줄여야 함. 예를 들어, 데이터를 읽는 코드가 날짜 기준으로(날짜 파티셔닝 된 상태) 데이터를 읽는다면, 그 날짜 내 데이터를 모두 한 번에 읽는게 아니라 한 job이 스캔하는 파일 수 / 파티션 수를 제한해서 조금씩 읽고 처리하도록 만든다던가 하루치 데이터를 → 1시간 단위 / shard 단위 / hash bucket 단위로 쪼개서 → 여러 번 실행 - hudi 의 upsert 비용이 비싸기 때문에, 일단 append-only 로 데이터를 저장하고, 나중에 처리하는 것으로 진행. 이것은 throughput 은 지키되 latency 를 희생(DS/BA 가 사용 가능한 데이터는 나중에 생김)하는 방법. |
| 데이터 파티셔닝의 개념과 분산 데이터 처리에서의 이점에 대해 설명해 주시겠습니까? |
데이터 파티셔닝은 분산 시스템에서 데이터 세트를 더 작은 하위 집합 또는 파티션으로 나누어 여러 노드에 분산시키는 것을 말합니다. 이를 통해 데이터의 병렬 처리가 가능해져 자원을 효율적으로 활용하고 성능을 향상시킬 수 있습니다. 또한 파티셔닝은 데이터를 노드 전체에 고르게 분산시켜 부하 분산을 용이하게 하고, 핫스팟 발생을 방지하며 시스템 확장성을 개선합니다. 더 나아가 데이터 파티셔닝은 노드 장애가 전체 시스템에 미치는 영향을 최소화하여 내결함성을 강화합니다. ?? how?? 일반적인 파티셔닝 전략으로는 특정 값 범위에 따라 데이터를 분할하는 범위 파티셔닝, 해시 값에 따라 데이터를 분산하는 해시 파티셔닝, 그리고 고유 식별자 또는 키에 따라 데이터를 분할하는 키 파티셔닝이 있습니다. |
| 데이터 웨어하우스 환경에서 데이터의 최신성과 일관성을 어떻게 보장합니까? |
최신성을 보장하려면 기준이 되는 날짜값 혹은 incremental value 가 있어야 할 것 같아. 이를테면 updated_date 를 기준으로 최신성을 판단하되, updated_date 가 동일하면 데이터가 생성될 때 받는 유니크한 incremental value 를 기준으로 최신성을 판단하면 좋을 것 같아. hudi 의 upsert 기능을 이용하면 편하겠지만, 사용할 수 없는 경우에는 직접 PK가 동일한 데이터끼리 updated_date+incremental value 를 통해 비교해서 가장 최신 데이터만 남기는 쪽으로 진행해야 할 것 같아. 여기서 일관성을 보장한다는 말은 integrity 를 말 하는 거겠지? integrity 를 보장하려면 hash 값, checksum 등을 만들어 비교해본다던가, 해당 컬럼값이 정상 범위인지 (not null 혹은 음수 체크 혹은 2301년 등의 이상한 미래값 등) 확인해본다던가, 소스DB 의 값과 비교해본다던가 할 것 같아. ⚠️ 보완하면 좋은 점
< 면접관이 의도한 개념 정리 > 최신성 (Freshness) : “가장 최신 상태의 데이터를 제공하고 있는가?” 핵심 질문: - 최신 기준이 무엇인가? - 늦게 도착한 데이터는 어떻게 처리하는가? - 중복 실행해도 결과가 동일한가? (idempotency) - 실패 시 재처리 가능한가? (재처리 시 중복이나 과거 데이터 overwrite는 안전한가) 일관성 (Consistency) : “데이터가 신뢰 가능한 상태인가?” '일관성' 에 포함되는 의미들 - Schema consistency : 타입, 컬럼 구조 - Record-level consistency : PK 유일성, 최신 row - Cross-table consistency : fact–dimension 관계 - Source-to-target consistency : 원본과 동일한 의미 (흔히 말하는 정합성) - Temporal consistency : 시간 기준 정합성 integrity는 그중 일부일 뿐 (내가 볼 땐 4번 빼고 다 일관성임...) < 추가하면 좋은 포인트들 >
event_time 을 기준으로 생성 순서를 알 수 있고, 재처리 할 때도 도움이 되고 event_time 으로만 집계 가능한 값, 이를테면 DAU(하루에 활동한 사용자 수) 집계에 도움이 됨 대신 late-arriving data 처리 등 추가 단계가 필요해서 "이제 한 번 사용해볼까?" 할 때는 processing_time 보다 느림(latency 가 있음) (정확도를 위해 latency 를 희생함) 그럼 processing_time 은 언제 쓸까? 정확성은 높지 않지만, 빠른 집계 결과가 필요할때 사용함 (latency 를 위해 정확도를 희생함) Hudi 못 쓸 때의 대안 ROW_NUMBER() OVER ( PARTITION BY pk ORDER BY updated_date DESC, seq DESC ) = 1 이걸 "deterministic deduplication" 이라고 표현함 |
| state-level idempotency 란? event-level idempotency 란? |
< State-level Idempotency > 같은 데이터를 여러 번 처리하더라도 최종 상태(state)가 변하지 않도록 보장하는 것 여러번 처리란, 재처리, 중복된 데이터 처리, 재시도 등을 의미함 배치 처리가 실패해서 재처리하거나, 백필하거나, CDC 에서 중복 데이터가 들어왔거나....등등 결과적으론 다 같은 말 같지만... 아무튼 재처리 진행 후에도 테이블 상태는 동일해야 함 사용자 프로필 정보가 담긴 테이블을 만든다거나 계좌 잔액 정보가 담긴 테이블을 만든다거나 demension 테이블을 만드는 등 여러번 실행한 후에도 정보가 바뀌지 말아야 하는 테이블에서 사용됨 State-level Idempotency 는 주로 UPSERT / MERGE 기반 파이프라인으로 완성됨 예를 들어, user_id = 1 의 이름 변경 이벤트가 여러 번 들어옴 (user_id=1, name=Alice, updated_at=2024-01-01) 아래 쿼리를 통해 통합 진행 ROW_NUMBER() OVER ( PARTITION BY pk ORDER BY updated_date DESC, seq DESC ) = 1 MERGE INTO users USING updates ON users.user_id = updates.user_id -- 동일한 PK 기준 WHEN MATCHED AND updates.updated_at > users.updated_at --최신 레코드만 남김 THEN UPDATE SET ... 여기서 merge into 는, '두 테이블을 비교해서 조건에 따라 insert, update, delete 를 수행'하는 명령어. merge into = upsert 문법이라고 보면 됨 MySQL 에서 지원하지 않고, SparkSQL 에서는 지원함 MERGE INTO [target_table] : 타겟 테이블 USING [source_table] : 소스 테이블 ON : 매칭 기준 SparkSQL 의 쿼리 예시 MERGE INTO users t USING updates s ON t.user_id = s.user_id WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT * MySQL 의 쿼리 예시 INSERT INTO users (...) VALUES (...) ON DUPLICATE KEY UPDATE name = VALUES(name), updated_at = VALUES(updated_at); |
< Event-level Idempotency > 같은 이벤트(event)가 여러 번 처리되더라도, 그 이벤트의 효과가 한 번만 반영되도록 보장하는 것 여기서 핵심은: - event 단위 - side effect 방지 Append-only event log 에서 사용하거나, 스트리밍 / CDC / 로그 기반 파이프라인 에서 사용함 매출 집계해야하거나, 클릭수를 확인해야하는 상황에서 사용함 클릭수 집계해야하는데 재처리, 중복전송 등에 의해 동일한 이벤트를 여러번 처리하면 클릭수가 늘어나면 잘못된 집곗값을 볼 수 있음 따라서 event-level idempotency 가 필요한 것 event_id를 immutable PK로 사용 event log에서 dedup 을 반드시 진행해야 함 아래와 같은 쿼리를 사용하여 구현 가능함 WITH temp AS ( *, SELECT ROW_NUMBER() OVER (PARTITION BY event_id ORDER BY ingestion_time) as rn FROM events ) SELECT * FROM temp WHERE rn = 1; 여기서 ingestion_time 으로 정렬한 이유는, 같은 event_id 를 가지면 논리적으로 동일하 내용을 갖기 때문에 굳이 event_time 을 사용할 필요가 없어서(=late-arriving data 를 구분 할 필요가 없어서) |
그래서 둘이 무슨 차이냐? event-level idempotency 에서 다루는 데이터는 '이벤트 데이터'임 이벤트 데이터는 그 자체로 의미가 있음 클릭수+1 이벤트, 매출+100 이벤트 등 이 이벤트 데이터는 테이블에 들어가기 전에 deduplication 되어야 함 테이블에 중복 적용되는 순간 이슈가 됨 state-level idempotency 는 테이블 기준으로 멱등성을 제공함 테이블에 들어오는 로그들이 재처리되거나 중복 처리되어도 테이블 자체의 상태는 그대로여야 함 간단한 예로, event-level idempotency 는 보장되지 않지만 state-level idempotency 는 보장되는 경우를 생각해보자 동일한 eventId 를 갖는 매출+100 이벤트를 중복 발생하면 이게 테이블에서+100을 올리는 처리가 두 번 될 것임 실제 아키텍처는 아래와 같음 Event Log (append-only, event-level idempotency) ↓ State Table (upsert, state-level idempotency) ↓ DS / BA / API 안전한 이벤트 처리를 위해 이벤트 deduplication 이 필수임 |
| event-based 모델이란? state-based 모델이란? |
< event-based 모델 > 생성되는 모든 이벤트를 append-only 로 table 에 추가하는 모델. 예를 들어, 수집하여 필터링한 이벤트들을 s3 에 그대로 차곡차곡 쌓는 것임 그리고 절대 건들지 않아야 함(=쌓은 데이터가 업데이트 되면 안 됨. immutable) event-based 모델 데이터를 통해 히스토리가 정확하게 보존되기 때문에 신뢰 가능한 과거의 발자취를 기록하는 용도(로깅)로 사용되거나 혹은 이 기록들을 기반으로 재처리 진행하는 데 사용됨 혹은 감사(audit)용이나, 데이터 출처 보존 및 데이터 이해를 위해 사용됨 이건 마치 data lake 에 데이터를 쌓아두는 것과 비슷하군 |
< state-based 모델 > 히스토리 유지 없이, 오로지 현재 상태만 table 에 저장하는 모델 새로운 데이터가 올 때마다 기존 데이터를 덮어쓰고 새로운 값을 유지함 저장 비용이 적음 쿼리가 단순하고 쿼리 성능이 좋음 |
그래서 이 둘은 각각 왜 언제 쓰이느냐? event-based 모델은 source of truth 로 사용되고 state-based 모델은 serving layer 로 사용됨 간단하게, data lake, data lakehouse 가 사용하는 모델들이라고 보면 됨 실제 파이프라인은 아래와 같은 구조를 갖음 [Source DB / App] ↓ [Event-based Data Lake] ↓ [State-based Lakehouse] ← MERGE / UPSERT ↓ [BI / DS / API] |
| 데이터 파이프라인에서 오류가 아닌 이상치를 어떻게 감지 & 대응하는가? |
여기서 말하는 '오류'는 파이프라인의 job 실패, mismatch 혹은 명백히 잘못된 데이터가 들어오는 경우(null PK 처럼)를 말함 '이상치'는 파이프라인의 정상 동작에 의해 생성되었지만, 기존 데이터의 분포, 패턴, 규모가 기대와 다른 경우를 말 함 예를 들어보자 - 데이터 볼륨 이상 : Volume Anomaly 평소에 100개 들어온 데이터가 오늘 갑자기 1만개 들어옴 - 값 분포 이상 : Distribution Anomaly 평균 30원 하던 물건이 갑자기 3000원이 됨 - 특정 값 이상 country="Kor" 로 답하는 비율이 30% 에서 99%가 됨 - 시간 관련 이상 event_time 이 미래시간임 - fact-dimension 테이블 간 관계가 깨진 경우 즉, fact table 에 존재하는 FK 가 dimension table 에 없는 경우 |
Ref.
- https://www.hipeople.io/interview-questions/data-engineer-interview-questions
- https://www.geeksforgeeks.org/data-engineering/data-engineer-interview-questions/
'Coding Interview' 카테고리의 다른 글
| [Spark] interview questions (0) | 2026.01.22 |
|---|---|
| [Airflow] interview questions (0) | 2025.12.14 |
| [SQL] interview questions (0) | 2025.12.12 |
| [Canada] 내가 찾아본, 채용 공고 확인하는 곳들 (0) | 2025.10.01 |
| [IT] Data Engineer 기술 인터뷰 준비를 위한 이론 + English (0) | 2025.08.20 |