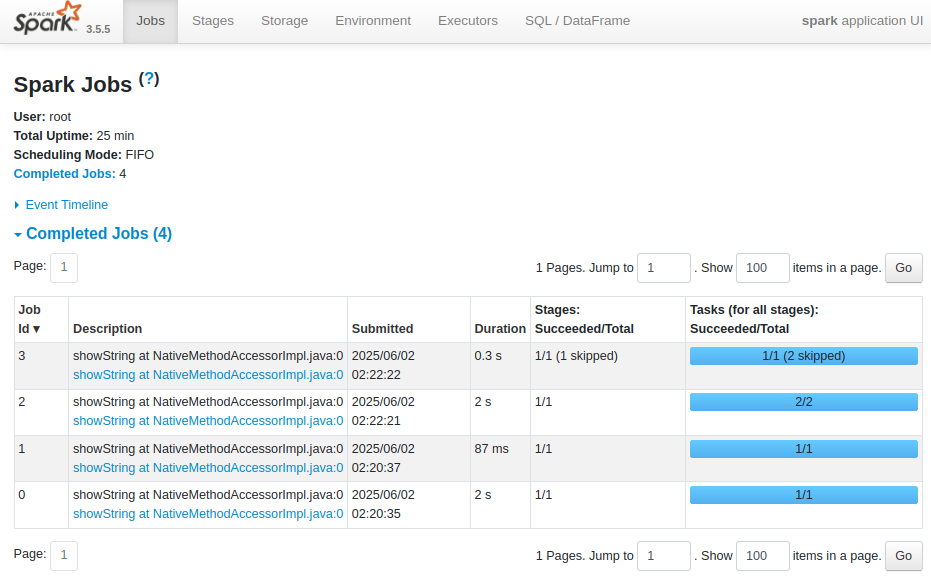
| Jobs : Spark Application 내에서 실행된 개별 Spark Job들의 목록과 상태를 보여주는 탭 |
| Total Uptime : Spark 애플리케이션이 시작된 후 경과된 총 시간 |
| Completed Jobs : 실행이 완료된 각 Spark Job에 대한 상세 정보 |
| Description : Job을 생성한 액션(Action) 연산 또는 사용자가 지정한 설명 링크를 누르면 해당 job 의 상세 정보를 볼 수 있는 페이지로 들어감 (showString at NativeMethodAccessorImpl.java:0 은 show() 액션에 의해 실행된 작업이라는 의미) |
| Stages: Succeeded/Total : 해당 Job을 구성하는 Stage들의 성공한 수와 전체 수 괄호 안의 (skipped)는 해당 Stage가 이미 이전 Job에서 성공적으로 완료되어, 다시 실행되지 않고 건너뛰어진 경우를 나타냄 |
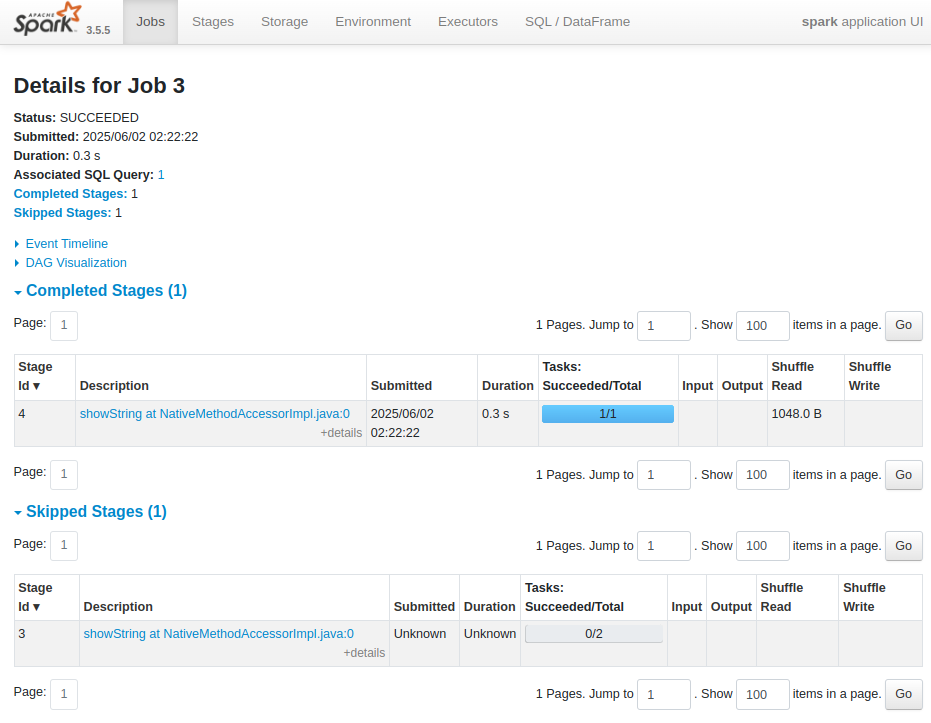
| Input : 해당 stage 가 (HDFS 등의) storage 로부터 읽은 데이터 양(bytes) Stage의 처리 대상 데이터 크기를 파악하여 성능에 미치는 영향을 분석할 때 사용됨 입력 데이터가 매우 크다면 해당 Stage가 병목 지점이 될 가능성을 고려할 수 있기 때문 |
| Output : 해당 Stage 가 (HDFS 등의) storage 에 쓴 데이터 양(bytes) 출력 데이터의 크기는 다음 Stage의 입력 크기에 영향을 미치므로, 데이터 흐름을 이해하는 데 중요함 |
| Shuffle Read : 해당 Stage가 Shuffle 과정에서 다른 Executor들로부터 읽어온 데이터의 총 양 Shuffle은 (groupByKey, reduceByKey, join 등의) 넓은 의존성(wide dependency)을 가진 연산 후 발생하며 데이터를 파티션 간에 재분배하는 과정임 네트워크 자원을 소모하는 작업이기에, shuffle read 양이 많다면 네트워크 I/O 부하 발생 가능 불필요한 shuffle 을 줄이거나, 좀 더 효율적인 셔플 파티셔닝 전략을 사용해야 함 |
| Shuffle Write : 해당 Stage가 Shuffle 과정에서 다른 Executor들이 읽어갈 수 있도록 로컬 디스크에 쓴 데이터의 총 양 shuffle write 양이 많다면 네트워크 I/O 부하 발생 가능 불필요한 shuffle 을 줄이거나, 좀 더 효율적인 셔플 파티셔닝 전략을 사용해야 함 |
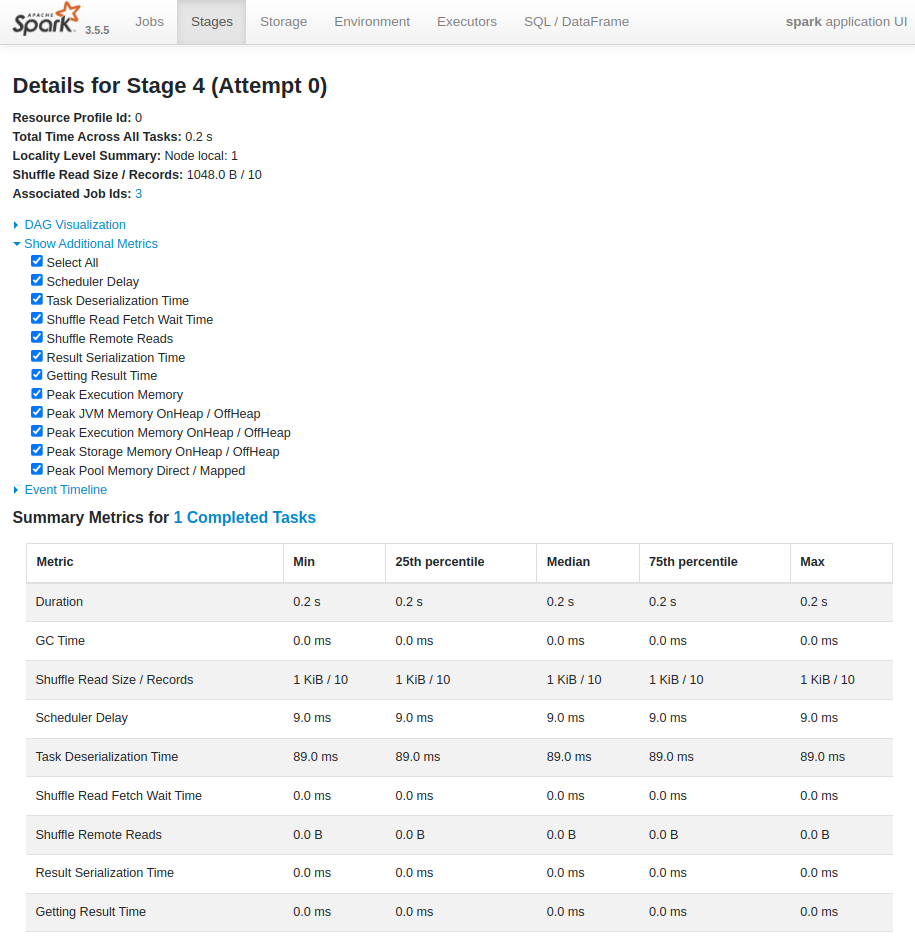
| Stages : Spark Application 내에서 실행된 개별 Spark Stage들의 목록과 상태를 보여줌 Stage는 넓은 의존성(wide dependency, shuffle 발생)을 기준으로 Job을 분리한 작업 단위임 |
| Min (Minimum) : 완료된 Task들 중에서 해당 메트릭의 최솟값 예를 들어, 'Duration'의 Min 값이 0.2 s라면, 완료된 Task 중 가장 짧게 실행된 Task의 실행 시간이 0.2초라는 의미 |
| 25th percentile : 완료된 Task들을 해당 메트릭 값에 따라 정렬했을 때, 하위 25%에 해당하는 값 즉, 25%의 Task가 이 값 이하의 메트릭 값을 가짐 예를 들어, 'Shuffle Read Size / Records'의 25th percentile 값이 1 KB / 10이라면, 25%의 Task가 읽은 Shuffle 데이터 크기가 1 KB 이하이고, 읽은 레코드 수가 10개 이하라는 의미 |
| Median (중앙값) : 완료된 Task들을 해당 메트릭 값에 따라 정렬했을 때, 정중앙에 위치하는 값 즉, 50%의 Task가 이 값 이하의 메트릭 값을 가지고, 나머지 50%는 이 값 이상의 메트릭 값을 가짐 |
| 75th percentile : 완료된 Task들을 해당 메트릭 값에 따라 정렬했을 때, 상위 25%를 제외한 하위 75%에 해당하는 값 즉, 75%의 Task가 이 값 이하의 메트릭 값을 가짐 |
| Max (Maximum) : 완료된 Task들 중에서 해당 메트릭의 최댓값 예를 들어, 'Peak Execution Memory'의 Max 값이 32.1 MiB라면, 완료된 Task 중 가장 많은 메모리를 사용한 Task의 최대 실행 메모리가 32.1 MiB라는 의미 |
| 위와 같은 백분위수 지표들은 Task들의 성능 분포를 이해하고 이상치를 식별하는 데 사용됨 Min, Median, Max 값을 통해 Task들의 성능 범위와 일반적인 성능 수준을 알 수 있음 25th, 75th percentile 값과 Min, Max 값을 비교하여 Task들의 성능 편차가 얼마나 큰지, 극단적으로 느리거나 많은 리소스를 사용하는 이상치 Task가 존재하는지 파악할 수 있음 Max 값이 Median이나 75th percentile 값과 크게 차이 난다면 특정 Task에 문제가 있을 가능성을 의심해 볼 수 있음 25th, Median, 75th percentile 값이 서로 가깝다면 Task들의 성능이 비교적 안정적이라고 판단할 수 있음 반대로 값의 차이가 크다면 성능 변동성이 크다는 것을 의미함 특정 메트릭 (예: Duration, Shuffle Read Time)의 높은 백분위수 값을 보이는 경우, 해당 부분의 성능 개선을 우선적으로 고려할 수 있음 |
| On-Heap (힙 메모리) : JVM이 관리하는 메모리 영역. Garbage Collection (GC)의 대상이 됨 - RDD에 저장된 데이터. RDD[String], RDD[(Int, Double)] 등 - DataFrame.collect() 등으로 데이터를 JVM 객체 (Row) 형태로 가져온 데이터 - 사용자 정의 함수(UDF) 내에서 생성되는 Java 또는 Scala 객체 - Spark 드라이버 및 Executor의 실행 계획, 스테이지 정보, Task 정보 등의 메타데이터 객체 - SparkContext, SparkSession, DataFrame, Dataset 등의 Spark API 객체 |
| Off-Heap (힙 외부 메모리) : JVM이 직접 관리하지 않는 메모리 영역. 애플리케이션이 명시적으로 할당하고 해제함 GC 의 대상에서 벗어남 - DataFrame/Dataset 데이터 (Tungsten 활성화 시) - Shuffle 데이터 (Tungsten 활성화 시): Shuffle 과정에서 Executor 간에 데이터를 주고받을 때, 데이터를 Off-Heap 메모리에 저장하여 직렬화/역직렬화 비용을 줄임 |
| Storage : Spark Application 내에서 생성된 RDD (Resilient Distributed Dataset) 및 Cache된 DataFrame/Dataset의 정보를 보여줌. 메모리 및 디스크에 캐싱된 데이터의 크기, 파티션 수, 저장 수준 등 확인 가능 |
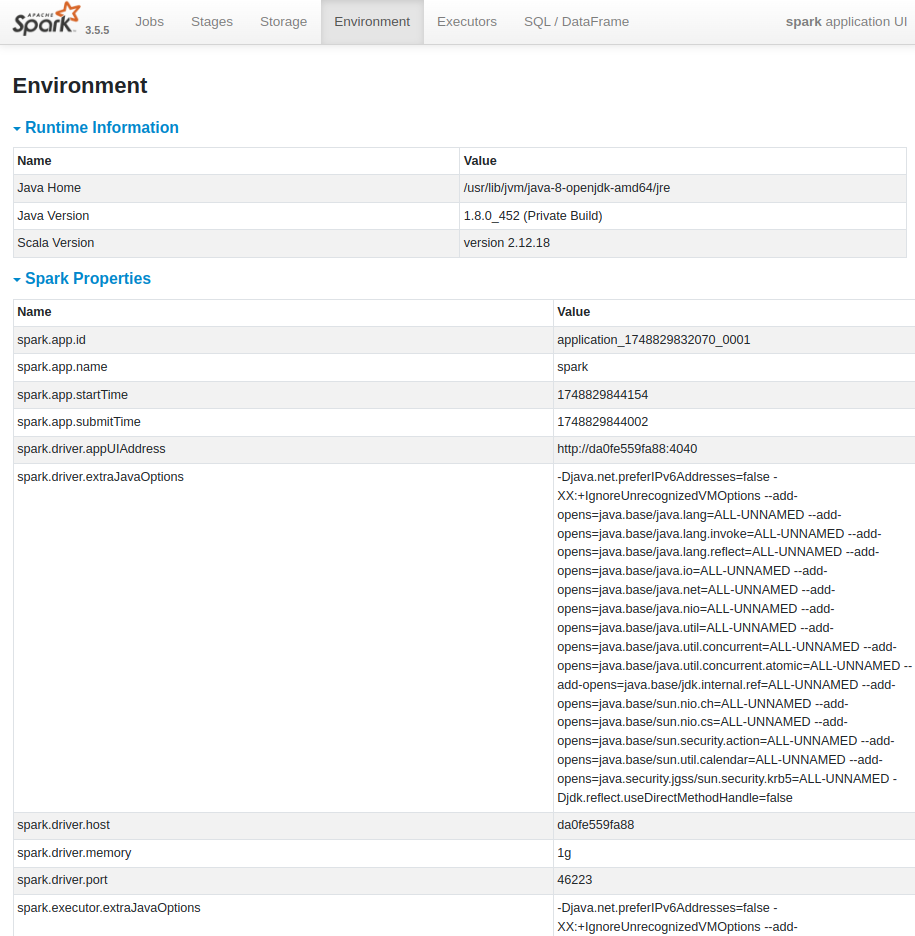
| Environment : Spark Application이 실행되는 환경에 대한 다양한 설정 정보를 보여줌 JVM 설정, Spark 속성, 시스템 속성, 클래스패스 정보 등 확인 가능 |
| spark.driver.memory : 드라이버 프로세스에 할당된 메모리 크기 충분한 메모리가 할당되지 않으면 OutOfMemoryError가 발생하거나 성능이 저하될 수 있음 |
| spark.executor.instances : 애플리케이션에 할당될 Executor의 총 개수. 애플리케이션의 병렬 처리 수준을 결정 |
| spark.executor.memory : 각 Executor 프로세스에 할당된 메모리 크기 |
| spark.executor.cores : 각 Executor에 할당된 CPU 코어 수. (Executor가 동시에 실행할 수 있는 Task의 수) |
| spark.default.parallelism : RDD 또는 DataFrame의 파티션 수를 명시적으로 지정하지 않았을 때 사용되는 기본 파티션 수 너무 작으면 병렬 처리가 제대로 이루어지지 않고, 너무 크면 Task 수가 늘어나 오버헤드 증가 |
| spark.sql.shuffle.partitions : Spark SQL에서 Shuffle 작업 시 생성되는 파티션의 수 |
| spark.memory.fraction : Executor 메모리 중 Spark이 데이터 저장 및 연산에 사용할 수 있는 비율 나머지 부분은 사용자 코드 실행에 사용됨 메모리 부족으로 인한 디스크 Spill을 줄이기 위해 조정하는 부분 |
| spark.memory.storageFraction : spark.memory.fraction으로 할당된 메모리 중 캐시에 사용할 수 있는 비율 캐싱을 많이 사용하는 애플리케이션의 경우 이 값을 늘리는 것이 성능 향상에 도움이 됨 |
| spark.driver.extraJavaOptions / spark.executor.extraJavaOptions : 드라이버 및 Executor JVM에 전달할 추가 JVM 옵션 GC 튜닝, 로깅 설정 등에 사용 |
| spark.dynamicAllocation.enabled : 동적 할당 기능 활성화 여부 |
| spark.dynamicAllocation.minExecutors / spark.dynamicAllocation.maxExecutors : 동적 할당 기능이 활성화되었을 때 Executor의 최소 및 최대 개수. |
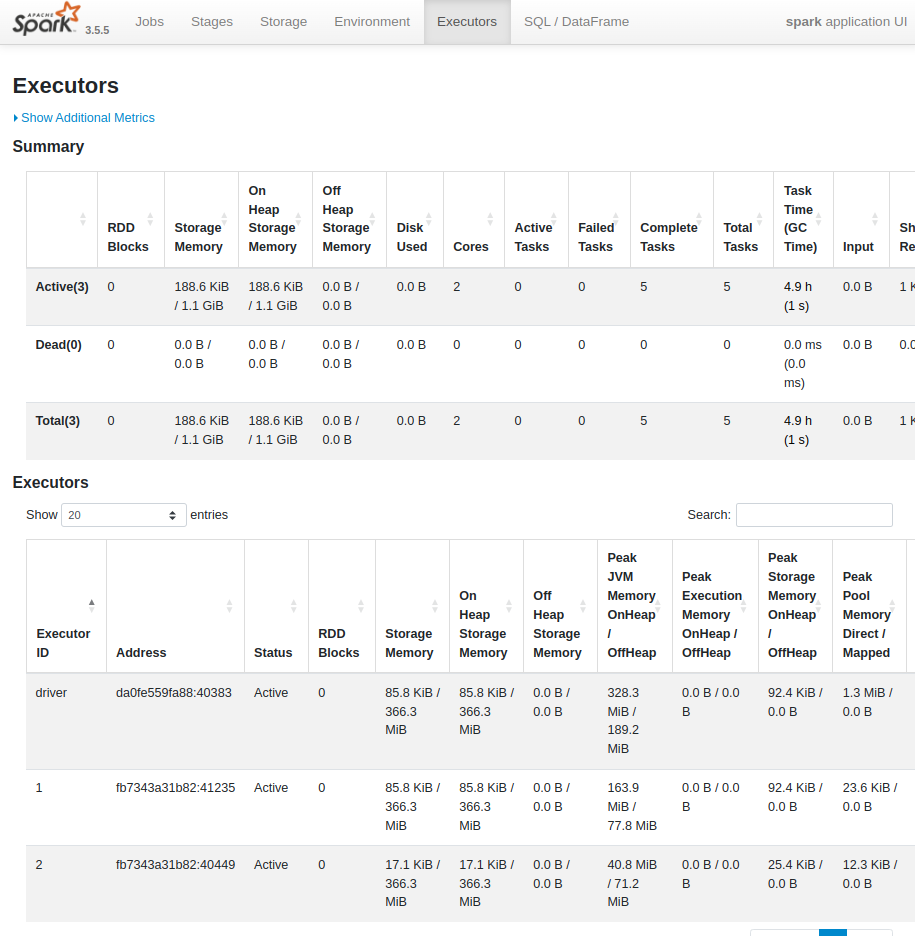
| Executors : Spark Application에 할당된 Executor들의 상태 및 리소스 사용 정보를 보여줌 각 Executor의 ID, 호스트, 활성/완료된 Task 수, CPU 사용률, 메모리 사용량 등 확인 가능 |
| Excluded : Spark 애플리케이션에서 제외된 (Excluded) Executor들의 목록과 그 이유를 보여줌 Reason for Exclusion : Executor가 제외된 구체적인 이유 표시 (예: 노드 장애, 메모리 부족, 네트워크 문제 등) |
| Thread Dump : 각 Executor JVM의 현재 스레드 상태 스냅샷 (프로세스 내에서 병렬처리를 위해 동작하는 그 스레드 맞음) Executor 내에서 어떤 스레드가 실행 중인지, 각 스레드의 상태 (RUNNABLE, BLOCKED, WAITING 등), 스택 트레이스 등 확인 가능 특정 Executor가 응답하지 않거나 (hang), CPU 사용률이 비정상적으로 높거나, 데드락이 의심될 때 확인하는 부분 - Hang 분석 : 스레드 덤프를 통해 특정 스레드가 어떤 상태로 멈춰 있는지 (예: 특정 리소스에 BLOCKED 상태로 오랫동안 대기 중인지) 파악하여 hang의 원인을 진단할 수 있음 어떤 쓰레드가 오랜 시간동안 BLOCKED, WAITING 상태라면 혹시 이게 hang의 원인이지 않을까 의심해볼 수 있지. 어떤 락을 기다리고 있는지, 어떤 스레드가 깨워주기를 기다리는지 등을 파악하여 데드락이나 장기 지연 문제를 진단할 수 있음 - CPU 병목 분석 : CPU를 많이 사용하는 스레드의 스택 트레이스를 분석하여 어떤 코드가 CPU를 집중적으로 사용하고 있는지 확인하고, 성능 개선의 힌트를 얻을 수 있음. 특정 스레드가 과도한 CPU를 사용하는지 분석 가능! - 데드락 감지 : 여러 스레드가 서로 다른 리소스를 점유하고 놓지 않아 영원히 대기하는 데드락 상황을 스레드 덤프를 통해 감지 - Executor 내부 상태 파악: Executor가 현재 어떤 작업을 수행하고 있는지, 어떤 라이브러리 함수를 호출하고 있는지 등을 스택 트레이스를 통해 자세히 확인 가능. 스레드가 특정 자원 (락, I/O 완료 등)을 기다리는 상황을 파악하여 자원 경쟁을 줄이거나 비효율적인 자원 사용 패턴을 개선 |
| Miscellaneous Process : 각 Executor JVM 내에서 Spark Task 실행 외에 다른 프로세스 또는 스레드가 사용한 리소스 (CPU 시간, 메모리 등)에 대한 정보 확인 이는 Spark Task 실행 자체와 관련 없는 JVM 내부 활동이나 다른 백그라운드 프로세스의 리소스 사용량을 파악하는 데 도움이 됨 |
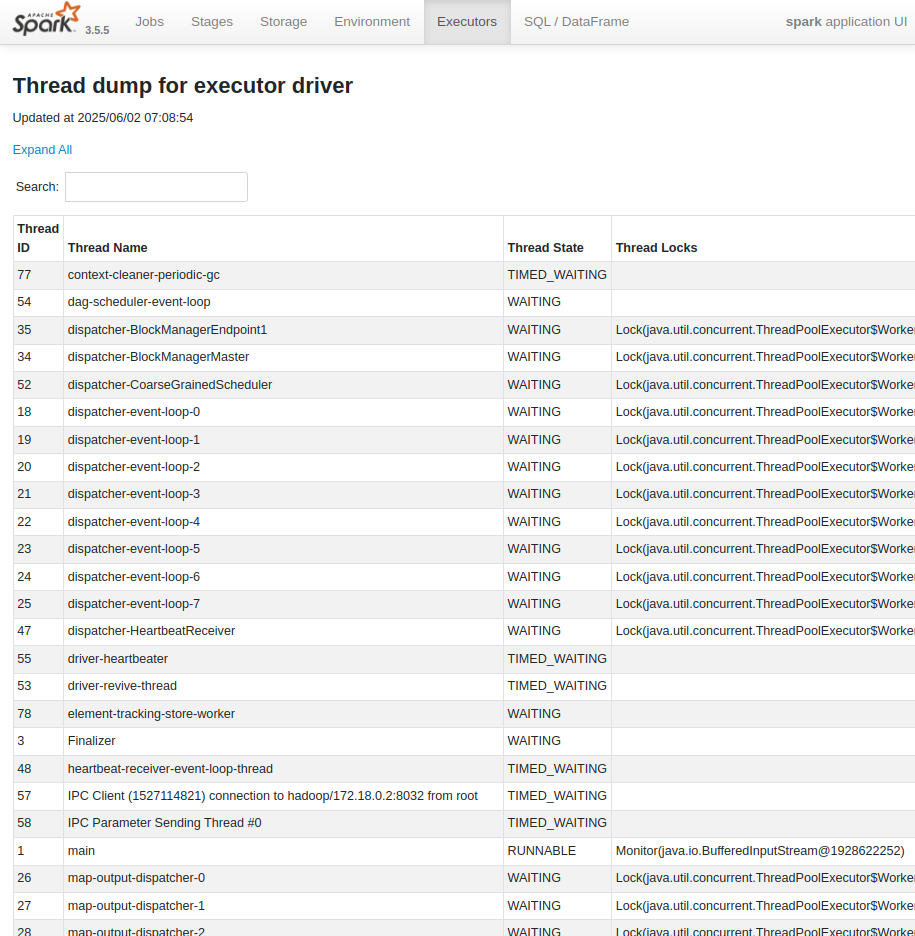
| Thread State (스레드 상태) : 각 스레드가 특정 시점에 갖는 상태 - NEW : 스레드가 생성되었지만 아직 시작되지 않은 상태. start() 메서드가 호출되기 전 - RUNNABLE : 스레드가 실행 중이거나, 실행될 준비가 되어 스케줄러의 할당을 기다리는 상태. CPU 시간을 얻으면 실제로 실행됨 - BLOCKED : 스레드가 모니터 락(synchronized 블록이나 메서드 진입 시 획득하는 락)을 획득하기 위해 대기하고 있는 상태 다른 스레드가 해당 락을 소유하고 있어 락을 얻을 때까지 멈춰 있음 - WAITING : 스레드가 특정 조건이 만족될 때까지 대기하고 있는 상태. 아래와 같은 메소드들에 의해 대기하게 됨 Object.wait() (다른 스레드가 notify() 또는 notifyAll()을 호출할 때까지 대기) Thread.join() (다른 스레드가 종료될 때까지 대기) LockSupport.park() (명시적으로 unpark될 때까지 대기) - TIMED_WAITING : 스레드가 특정 시간 동안 대기하고 있는 상태. Thread.sleep(long) 등에 의해 멈춰있음 - TERMINATED : 스레드의 실행이 완료된 상태 |
| Thread Locks (스레드 락) : 각 스레드가 현재 획득하고 있는 락(owned monitors)과 획득하기 위해 대기하고 있는 락(waiting to lock on) 정보를 보여줌 락은 공유 자원에 대한 동시 접근을 제어하여 데이터의 무결성을 보장하는 데 사용됨 |
| 참고 : 스레드 덤프 분석하기 https://d2.naver.com/helloworld/10963 |
| SQL / DataFrame : Spark Application 내에서 실행된 SQL 쿼리 및 DataFrame 연산들의 정보를 보여줌 각 쿼리의 ID, 설명, 실행 계획, 실행 시간 등 확인 가능 |
'Spark' 카테고리의 다른 글
| [Spark] Scala 다양한 연산 모음 (0) | 2022.09.26 |
|---|---|
| [PySpark] sample dataframe 만들기 (0) | 2022.05.09 |
| [PySpark] 컬럼의 합 구하는 방법 (0) | 2021.06.16 |
| [PySpark] 여러 path 에서 데이터 읽는 방법 (0) | 2021.06.16 |
| [Spark] SQL Built-in Functions 문서 링크 (0) | 2021.06.16 |