본 포스트에서는 Docker 를 이용하여 spark 클러스터 환경을 구성하는 방법에 대해 설명한다.
Mac local 에서 작업하였다.
spark image 는 Kookmin Univ Bigdata Lab 에서 사용하는 spark image 를 사용한다.
Docker 를 사용하는 자세한 방법은 여기 참고.
Docker 를 설치하는 방법은 여기 적지 않는다.
1.
spark 이미지를 받는다.
sudo docker pull kmubigdata/ubuntu-spark:latest
받는데 시간이 좀 걸림
아래 명령어로 image 가 잘 받아졌는지 확인한다.
sudo docker images
2.
네트워크를 만든다.
가장 마지막에 있는 "my-net" 이 지금 만들고자 하는 네트워크의 이름이다.
sudo docker network create --subnet 10.0.0.0/24 my-net
아래 명령어로 network 잘 만들어졌는지 확인한다.
sudo docker network ls
subnet 옵션으로, 8bit 네개로 구성된 ip 에서 얼마만큼의 범위로 ip 를 사용할 수 있는지 정할 수 있다.
뒤에 slash 다음에 나오는 숫자만큼, ip 의 앞단 범위가 고정되고, 나머지가 우리가 사용할 수 있는 ip 범위가 된다.
이를테면
10.0.0.0/8 는 10.0.0.0 bold 한 곳은 고정되고 나머지 부분이 사용가능하기 때문에,
10.0.0.1 ~ 10.255.255.254 만큼 사용 가능하다.
10.0.0.0/16 은 10.0.0.0 bold 한 곳은 고정되고 나머지 부분이 사용가능하기 때문에,
10.0.0.1 ~ 10.0.255.254 만큼 사용 가능하다.
10.0.0.0/24 은 10.0.0.0 bold 한 곳은 고정되고 나머지 부분이 사용가능하기 때문에,
10.0.0.1 ~ 10.0.0.254 만큼 사용 가능하다.
왜 10.0.0.0 ~ 10.0.0.255 가 아닐까?
왜냐면 사용 가능한 ip 중 가장 앞의 ip (10.0.0.0) 은 Network-ID 으로 사용되고,
사용 가능한 ip 중 가장 뒤의 ip (10.0.0.255) 는 Broadcast 에 사용되기 때문이다.
저 두 ip 는 특수 목적용이기 때문에, 우리 자체적으로 사용할 수 없음.
참고로 Docker swarm 을 한 상태에서 overlay network 를 만들고 싶다면 아래 명령어 참고
sudo docker network create -d=overlay --subnet 10.0.0.0/24 --attachable my-net
(swarm 참고 : 링크)
3.
spark 에 사용할 master, slave-1, slave-2 를 만든다.
master 의 이름은 반드시 master 여야 하지만, slave 의 이름은 마음대로 정하여도 좋다.
master 여야 하는 이유는, 해당 image 의 Docker 내부 세팅이 "master" 라는 이름으로 하드코딩 되어있기 때문이다.
sudo docker run -itd --network my-net --name master --ip 10.0.0.2 -p 28088:8088 -p 9870:9870 -p 28080:18080 kmubigdata/ubuntu-spark:latest /bin/bash
sudo docker run -itd --network my-net --name slave-1 --ip 10.0.0.3 -p 28089:8088 kmubigdata/ubuntu-spark:latest /bin/bash
sudo docker run -itd --network my-net --name slave-2 --ip 10.0.0.4 -p 28090:8088 kmubigdata/ubuntu-spark:latest /bin/bash
--ip 를 이용하여 일부러 각 container 마다 static 한 ip 를 할당하였다.
--ip 옵션이 없으면 ip 를 자동으로 할당하게 된다.
나중에 해당 container 를 stop, start 하고 나면 ip 가 바뀌고 그것이 문제의 원인이 될 수 있기 때문에 미리 static 하게 만들어둔다.
(port number는 내가 임의로 지정했으므로, 예제로만 보길 바람. 실제로 사용할 땐 port 충돌이 있을 수 있으니 직접 바꿔서 사용하길 바람)
-p 옵션을 넣어서 외부 port 를 Docker container 내의 port 로 연결되도록 했다.
-p [외부 port]:[Container 내부 port]
특별히 알아두면 좋은 port number를 여기 적어둔다.
|
<해당 내용은 오래된 정보일 수 있으니 최신 정보를 갖고 있는 여기를 참고하자>
HDFS : 50070, 19888 Spark : 4040, 8080, 18080 MongoDB : 27017 HBase : 60010 YARN : 8088
|
컨테이너들이 잘 동작하고 있는지, 아래 명령어로 확인한다.
sudo docker ps -a
STATUS 가 exit 이나 create 가 아니라, Up n seconds 여야 한다.
port number 에 따라 접근한 webui 의 모습을 보면 아래와 같다.
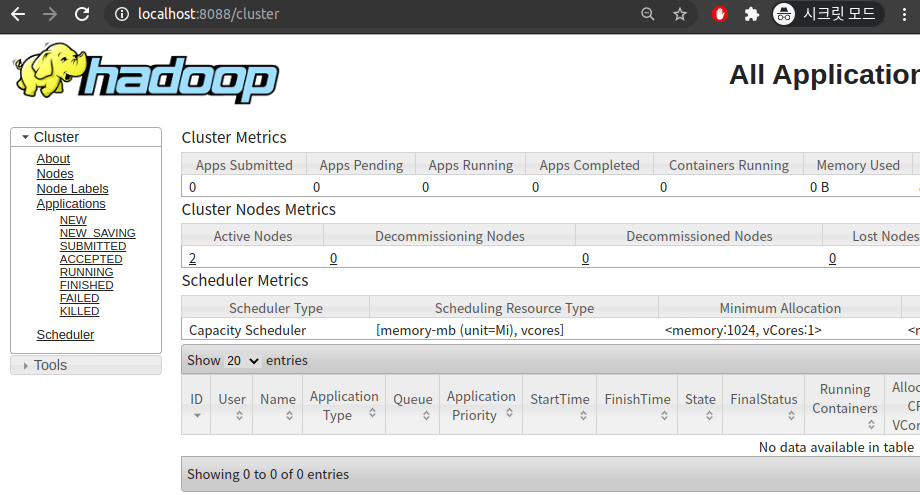
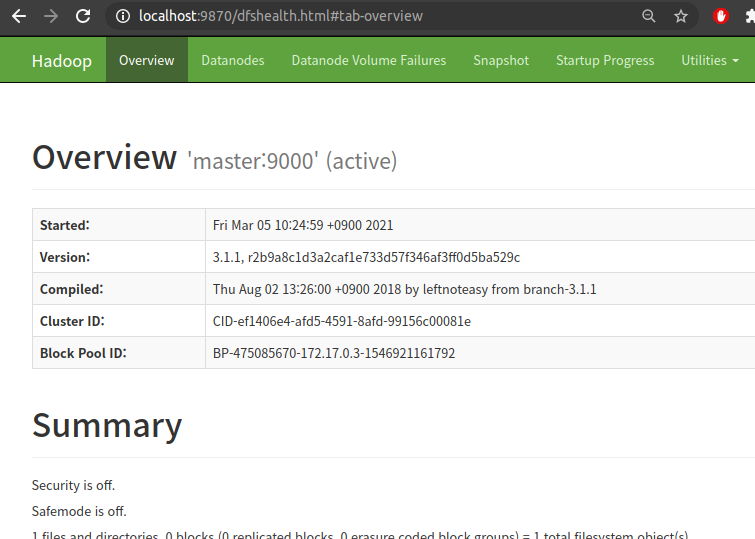
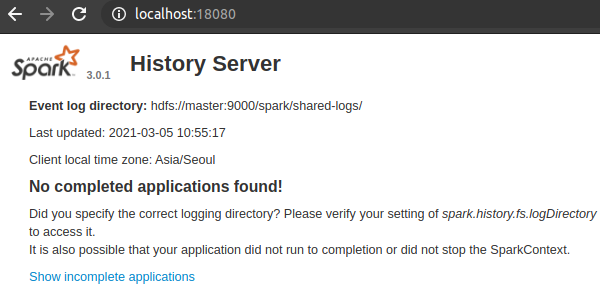
4.
아래 명령어로 master container 에 들어간다.
sudo docker exec -it master bash
컨테이너 내부에서, workers 파일을 수정한다.
cd /usr/local/hadoop/etc/hadoop/
vi workers
workers 에 있는 localhost 를 지워버리고, 아래 내용으로 대체
slave-1
slave-2
master 서버에서 slave 을 연결할 때 slave들의 ip 값을 여기 적는건데,
같은 Docker network 에 있는 container 들끼리는, ip 값 대신 container 이름을 대신 적어도 ip 로 인식된다.
5.
아래 명령어로 master 를 slave 들과 잇는다.
해당 Docker image 에서 ssh 연결 세팅을 다 해두었기 때문에 추가적인 작업이 필요하지 않다.
만약 해당 image가 아닌 다른 image 로 spark 환경 구성을 하고 있다면, 각 container 마다 ssh 연결 세팅을 해야 한다.
start-all.sh
연결이 잘 되었는지 확인하기 위해 아래 두 개의 명령어를 사용해본다.
명령어를 통해 나온 list에서, slave-1 과 slave-2 에 해당하는 녀석들이 있는지 확인해본다.
에러가 나는 명령어가 있다면, 연결에 문제가 있다는 소리.
hdfs dfsadmin -report
yarn node -list
6.
아래 명령어로 spark shell 을 실행시켜본다.
spark-shell --master yarn
만약
2019-08-30 05:04:21 ERROR Main:91 - Failed to initialize Spark session.
java.io.FileNotFoundException: File does not exist: hdfs://master:9000/spark/shared-logs
위의 에러가 나면, 아래 명령어로 hdfs 내에 directory 를 만들어주자.
hdfs dfs -mkdir -p /spark/shared-logs
spark shell 에서 나오려면 ctrl+c 를 누르거나, quit 를 타이핑 한다.
7.
spark history server WebUI 를 보기 위해, 아래 명령어를 실행한다.
/usr/local/spark/sbin/start-history-server.sh
그리고 웹 브라우저에서 아래 포트로 접근해본다.
localhost:28080
spark history server WebUI 를 볼 수 있다.
여기서 spark app 이 실행되고 난 후에 정리된 log 들을 볼 수 있다.
(나중에 살펴보니 port 번호가 다르단 것을 알게되어 취소선을 그어놓음. 8088은 hadoop 으로 연결된다.)
28080 이란 포트는 어디서 왔는가?
master container 를 처음 만들 때 -p 라는 옵션으로 28080:18080 을 넣어주었다.
"local 컴퓨터에서 28080 으로 접근하면, Docker container 의 18080 으로 연결시켜라" 라는 의미이다.
즉, Docker container 에서 18080 으로 포트를 열어 Web Page 를 띄우고 있고,
우리가 거기에 접근하기 위해선 local 컴퓨터의 28080 로 접근하면 된다는 이야기.
docker 의 18080 으로 접근이 안 된다면,
start-history-server.sh 를 실행시킨 후 spark 를 한 번 실행시키면 된다.
'Spark' 카테고리의 다른 글
| [Spark Streaming] java.lang.IllegalArgumentException: Option 'basePath' must be a directory 에러 (0) | 2019.09.03 |
|---|---|
| [Spark Streaming] Structured Streaming 공부에 도움 되는 사이트 (0) | 2019.09.03 |
| [Spark] 스칼라 DataFrame 다양한 연산 모음 (1) | 2019.08.28 |
| [Spark Streaming] trigger, window, sliding 이해 하기 (0) | 2019.08.22 |
| [Spark] YARN 위에서 Application 을 실행하는 단계 (0) | 2019.07.25 |