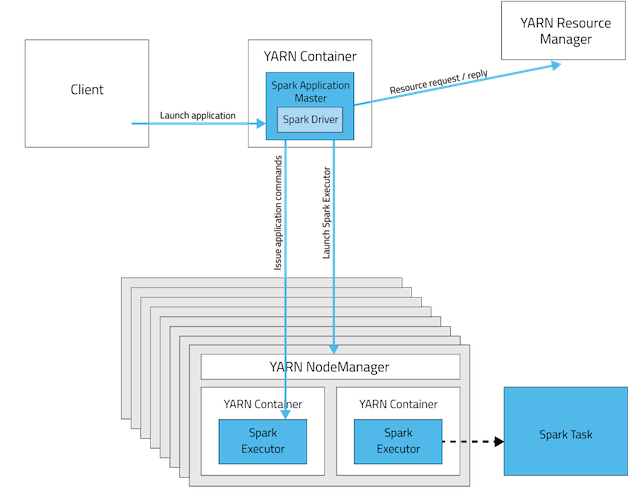
스파크 어플리케이션이 YARN에서 실행되면 먼저 어플리케이션 마스터(Application Master) 프로세스가 생성이 되는 데 이것이 바로 Spark Driver를 실행하는 컨테이너가 됩니다.
그리고 이 Spark Driver가 YARN의 리소스 매니저와 협상하여 이 어플리케이션을 실행하기 위한 리소스를 받아냅니다.
리소스를 받아내면 YARN 노드 매니저(Node Manager)에게 Spark Executor를 실행하기 위한 컨테이너를 생성하도록 지시합니다.
이 후에 이 Spark Executor가 태스크들을 할당받아서 실제로 태스크를 수행하는 프로세스입니다.
실제로 executor 에 job(tasks)을 제출하는 것은 spark context
하둡 YARN 클러스터에서 Spark Application을 실행하는 모델 (Hadoop Yarn and Spark App model)
This article is based on Hortonworks Partner Content and Expertise 하둡 2.0의 리소스 관리 플랫폼이라고 할 수 있는 YARN(Yet Another Resource Negotiator)에 대해서는 여러 기사에서 소개를 드렸습니다. 하둡 2.0 YARN의 컨셉에 대한 검토와 적용방법 현대적인 하둡 아...
asdtech.co
https://www.slideshare.net/datamantra/spark-on-yarn-54201193
Spark on yarn
Introduction to Machine Learning in Spark. Presented at Bangalore Apache Spark Meetup by Shashank L and Shashidhar E S on 17/10/2015. http://www.meetup.com/Ba…
www.slideshare.net
https://spark.apache.org/docs/latest/cluster-overview.html
standalone 으로 Spark 를 실행할 때의 Spark Application 을 실행하는 단계를
아래 링크에서 자세히 설명해주고 있다.
https://www.samsungsds.com/global/ko/support/insights/Spark-Cluster-job-server.html
클러스터 리소스 최적화를 위한 Spark 아키텍처 ①
클러스터 리소스 최적화에 대해 쉽게 설명한 글입니다. Spark Cluster에 대한 기본적인 개념과 Spark Job Server를 활용한 효율적인 리소스 관리 방법에 대한 궁금증을 해결해 보세요.
www.samsungsds.com
아래는 위의 설명을 위해 알아야 할 개념들

To know about the workflow of Spark Architecture, you can have a look at the infographic below:
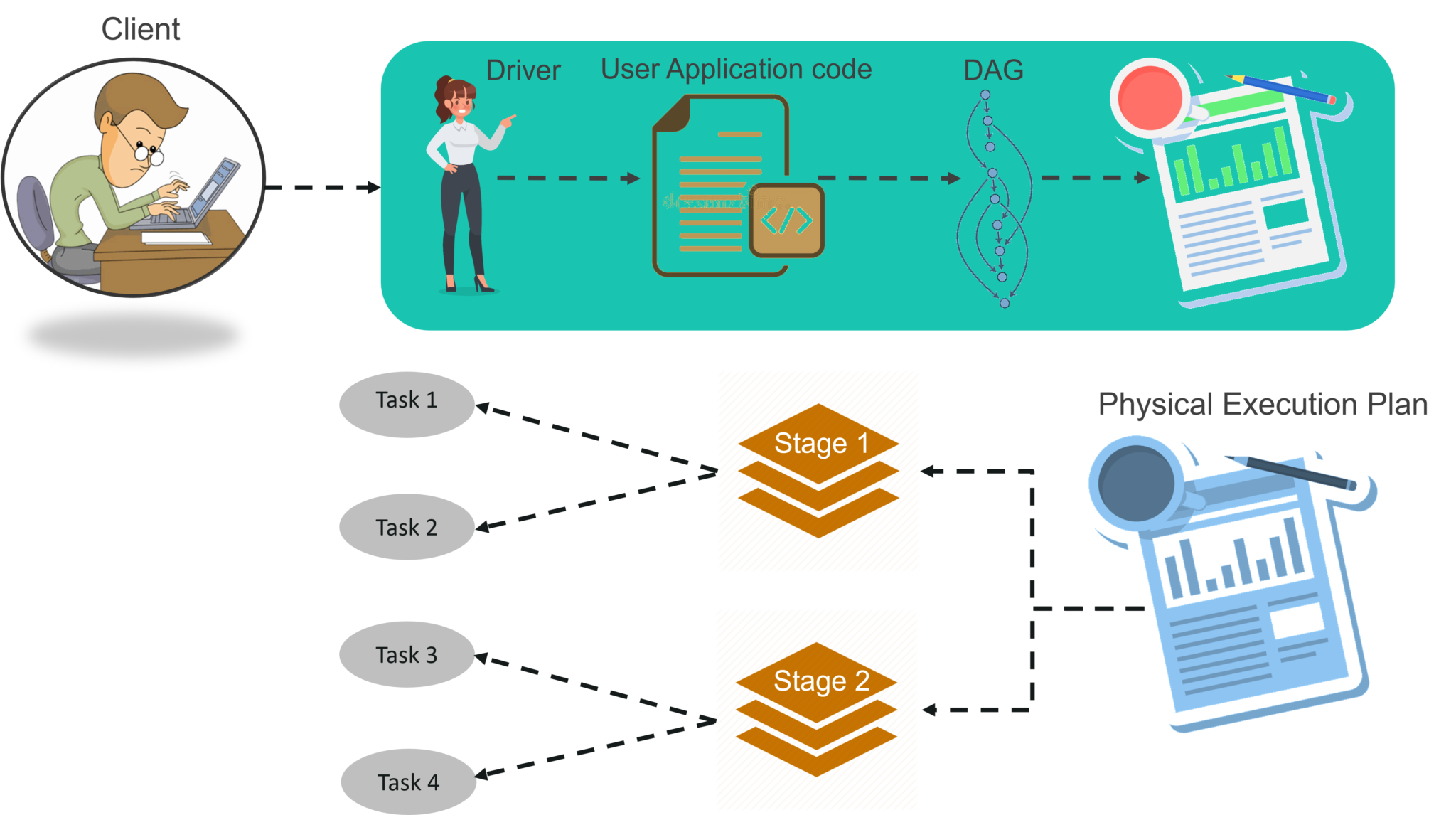
Fig: Spark Architecture Infographic
STEP 1: The client submits spark user application code. When an application code is submitted, the driver implicitly converts user code that contains transformations and actions into a logically directed acyclic graph called DAG. At this stage, it also performs optimizations such as pipelining transformations.
STEP 2: After that, it converts the logical graph called DAG into physical execution plan with many stages. After converting into a physical execution plan, it creates physical execution units called tasks under each stage. Then the tasks are bundled and sent to the cluster.
STEP 3: Now the driver talks to the cluster manager and negotiates the resources. Cluster manager launches executors in worker nodes on behalf of the driver. At this point, the driver will send the tasks to the executors based on data placement. When executors start, they register themselves with drivers. So, the driver will have a complete view of executors that are executing the task.
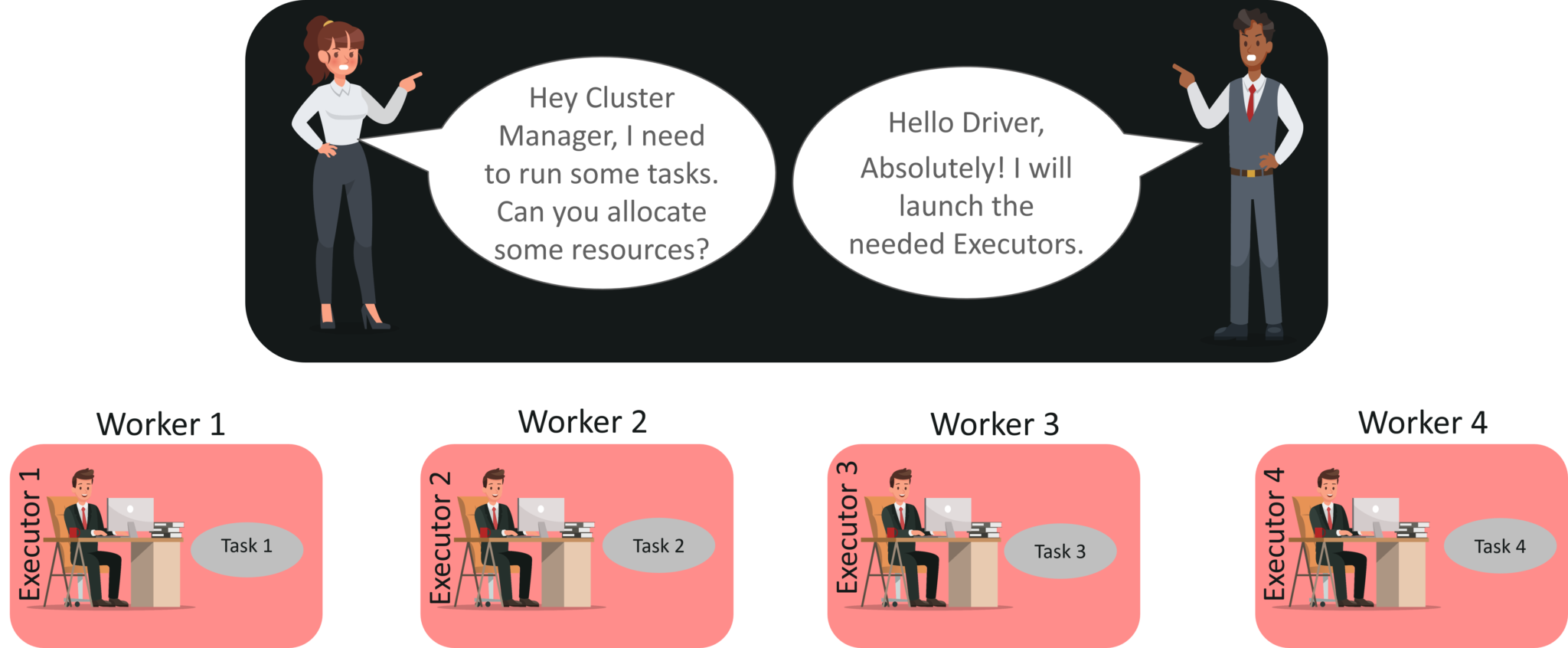
STEP 4: During the course of execution of tasks, driver program will monitor the set of executors that runs. Driver node also schedules future tasks based on data placement.
https://www.edureka.co/blog/spark-architecture/
Apache Spark Architecture | Distributed System Architecture Explained | Edureka
This article on "Spark Architecture" will help you to understand the Spark Eco-system Components and give you a brief insight of Apache Spark Architecture.
www.edureka.co
아래 slide 에 그림으로 Spark Architecture 와 YARN 의 동작이 step by step 잘 나와있다. 적극 참고.
https://www.slideshare.net/FerranGalReniu/yarn-by-default-spark-on-yarn
Yarn by default (Spark on YARN)
With the rise of the cloud, data intensive systems and the Internet of Things the use of distributed systems have become widespread. The first big player was H…
www.slideshare.net
참고 :
'Spark' 카테고리의 다른 글
| [Spark] 스칼라 DataFrame 다양한 연산 모음 (1) | 2019.08.28 |
|---|---|
| [Spark Streaming] trigger, window, sliding 이해 하기 (0) | 2019.08.22 |
| [Spark] value toDF is not a member of org.apache.spark.rdd.RDD 에러 (0) | 2019.07.19 |
| [Spark] MongoDB 와 연동시 Aggregate Query하는 방법 (0) | 2019.07.13 |
| [Spark] MongoDB로부터 데이터 읽고 pagerank 알고리즘 구현하기 (0) | 2019.06.17 |