사전에 미리 mongodb와 연동이 되도록 lib도 모두 세팅하고,
configuration 을 모두 올바르게 작성했다는 전제 하에 아래 설명을 이어간다.
withPipeline 이라는 함수가 있는데 이걸 사용하면 된다.
만약 mongo db 에 dataset.data 위치에 아래와 같은 데이터가 있다고 하자.

아래처럼 " :: " 을 기준으로 split 하고 싶다고 할 때 쿼리를 어떻게 넣어야 할까

아래처럼 하면 된다.
import com.mongodb.spark._
import org.bson.Document
val rdd = MongoSpark.load(sc)
val query = "{ $project : { _id:0, splits : { $split: ['$data', '::'] }}}" // mongo aggregate 쿼리를 넣어준다.
val result = rdd.withPipeline(Seq(Document.parse(query)))

이렇게 나온 결과를 어떻게 사용할까
아래처럼 map 을 사용한 후, 그 안에서 doc.get* 메소드를 사용하여 꺼내 사용한다.
val data = result.map( (doc : Document) => { doc.get("splits") } )

get 뿐 아니라 getInteger, getDouble, getClass, getString... 등이 있으니 타입에 맞춰 골라 사용하면 된다.
위의 예제에서는 하나의 쿼리만 날렸는데, 만약 mongo aggregate 를 여러번 하고 싶을 땐 어떻게 할까?
아래처럼 하면 된다. (쿼리 내용은 신경쓰지 말고 전체적으로 어떻게 구성되어있는지 보라)
val firstQry = "{ $project : { _id:0, splits : { $split: ['$data', '::'] }}}"
val secondQry = "{ $project : { a : { $arrayElemAt : ['$splits', 0] }, b : { $arrayElemAt : ['$splits', 1] }, c : { $arrayElemAt : ['$splits', 2] }, d : { $arrayElemAt : ['$splits', 3] }}}"
val result = rdd.withPipeline(Seq(Document.parse(firstQry), Document.parse(secondQry)));
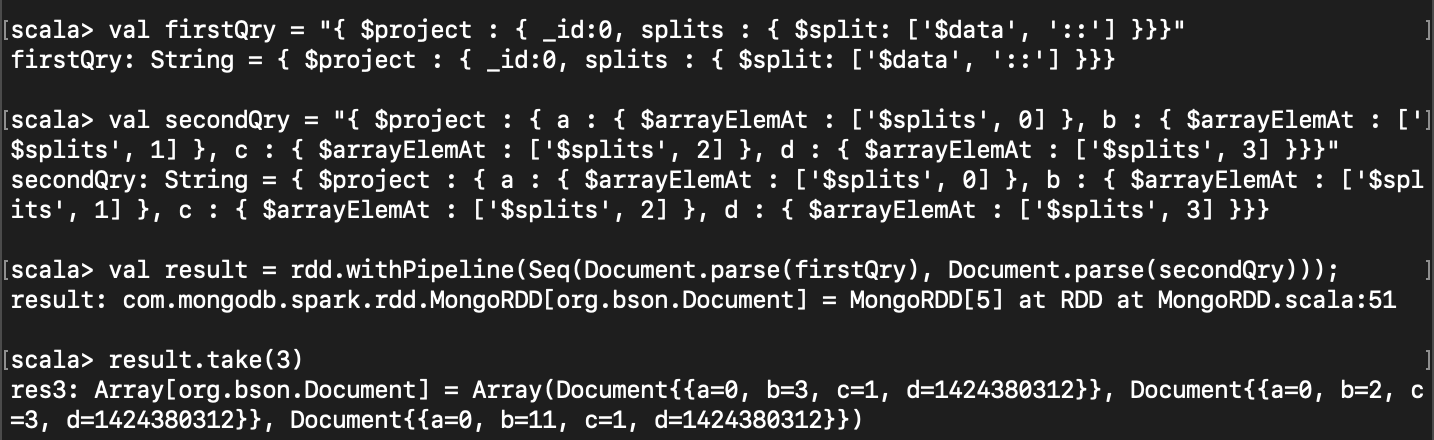
val data = result.take(3).map((doc:Document)=>{
(doc.getString("a"), doc.getString("b"), doc.getString("c"), doc.getString("d"))
})

여담으로, 위의 데이터 값은 숫자값인데 String 으로 받고 있다.
애초에 MongoDB 에서 가져올 때 String으로 가져오기 때문에 String 으로 tpye 이 정해지게 된 것인데,
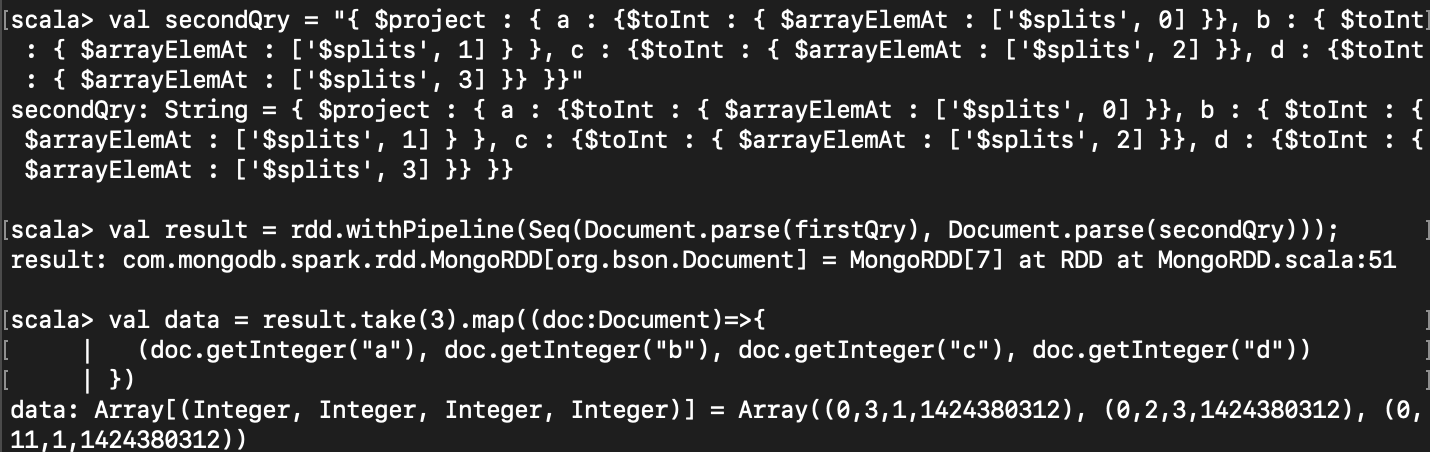
만약 Int 로 바꾸고 싶다면 $toInt 혹은 $convert 를 사용하면 된다.
예를 들면
val secondQry = "{ $project : { a : {$toInt : { $arrayElemAt : ['$splits', 0] }}, b : { $toInt : { $arrayElemAt : ['$splits', 1] } }, c : {$toInt : { $arrayElemAt : ['$splits', 2] }}, d : {$toInt : { $arrayElemAt : ['$splits', 3] }} }}"
val result = rdd.withPipeline(Seq(Document.parse(firstQry), Document.parse(secondQry)));
val data = result.take(3).map((doc:Document)=>{
(doc.getInteger("a"), doc.getInteger("b"), doc.getInteger("c"), doc.getInteger("d"))
})
movielens sample data : https://github.com/apache/spark/blob/master/data/mllib/als/sample_movielens_ratings.txt
multiple queries : https://stackoverflow.com/questions/39305572/how-to-provide-multistage-in-with-pipeline-of-javamongordd-in-java-code
MongoDB $toInt : https://docs.mongodb.com/manual/reference/operator/aggregation/toInt/
MongoDB $convert : https://docs.mongodb.com/manual/reference/operator/aggregation/convert/
'Spark' 카테고리의 다른 글
| [Spark] YARN 위에서 Application 을 실행하는 단계 (0) | 2019.07.25 |
|---|---|
| [Spark] value toDF is not a member of org.apache.spark.rdd.RDD 에러 (0) | 2019.07.19 |
| [Spark] MongoDB로부터 데이터 읽고 pagerank 알고리즘 구현하기 (0) | 2019.06.17 |
| [Scala] 공부하기 좋은 블로그 링크 (0) | 2019.06.17 |
| [Spark] Spark-SQL 튜토리얼/가이드 링크들(영어) (0) | 2019.06.17 |