여기 있는 간단한 연산들이 추후 만들게 될 복잡한 연산들의 한 부분이 되었으면 좋겠다.
< 0에서 n까지 숫자 배열 만들기 >
val num_array = spark.range(30).toDF("number")
< csv, tsv 파일 읽기 >
val csv_data = spark.read.csv("[PATH]").toDF
val tsv_data = spark.read.option("sep","\t").csv("[PATH]").toDF
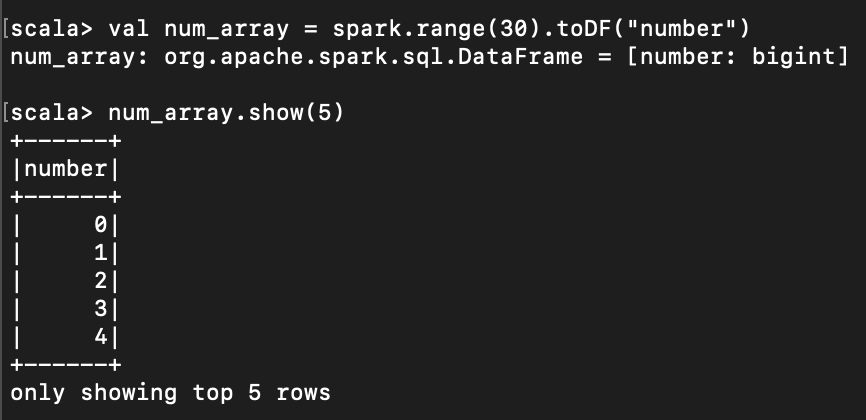
< json 파일 읽고 스키마 출력 >
val json_data = spark.read.format("json").load(" [hdfs 의 json 파일 경로] ")
json_data.schema()
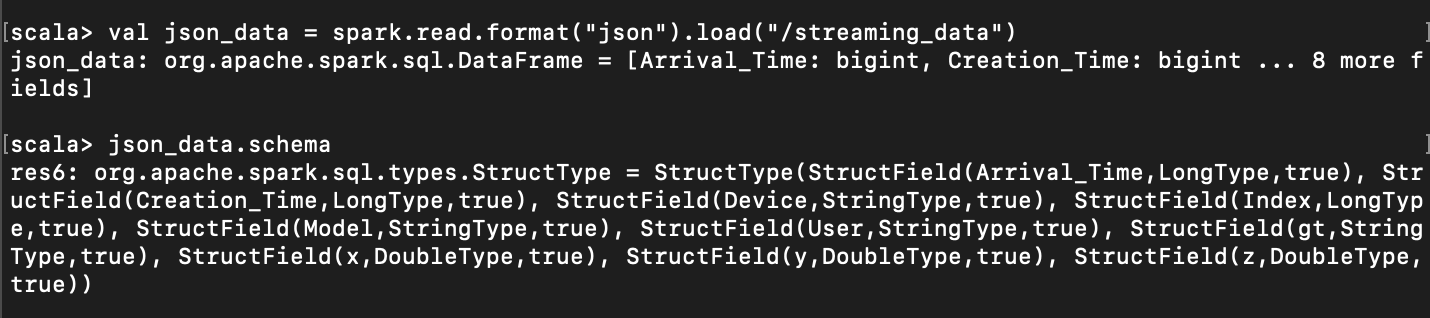
다른 json 데이터를 읽을 때 schema 가 똑같다면, 위와 같은 방식으로 가져와서 schema 를 지정할 수 있다.
예를 들어,
val other_json_data = spark.read.format("json").schema(json_data.schema).load(" [hdfs 경로] ")
readStream 으로 스트리밍 기능을 사용할 때는 schema 를 무조건 지정해줘야한다.
일일이 schema 를 타이핑하기에는 무리가 있으니,
똑같은 데이터를 read 로 읽고 schema를 가져온 뒤
readStream으로 읽을 때 schema 를 위와 같은 방식으로 지정해주면 쉽다.
예를 들면,
val schema = spark.read.format("json").load("/streaming_data").schema
val df = spark.readStream.format("json").schema(schema).load("/streaming_data")
< 파일 쓰기 >
아래 참고
https://eyeballs.tistory.com/166
https://stackoverflow.com/questions/33174443/how-to-save-a-spark-dataframe-as-csv-on-disk
https://spark.apache.org/docs/latest/sql-data-sources-load-save-functions.html
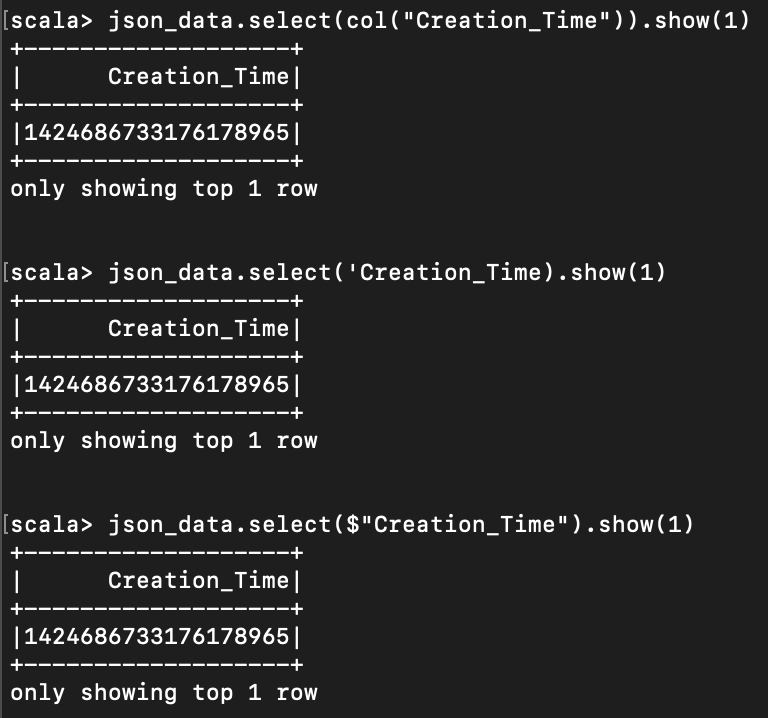
< dataframe 에서 column 지정하기 >
아래 세 가지 방법으로 column 에 접근 가능하다.
json_data.select(col("[column 명]")).show(1)
json_data.select($"[column 명]").show(1)
json_data.select('[column 명] ).show(1)
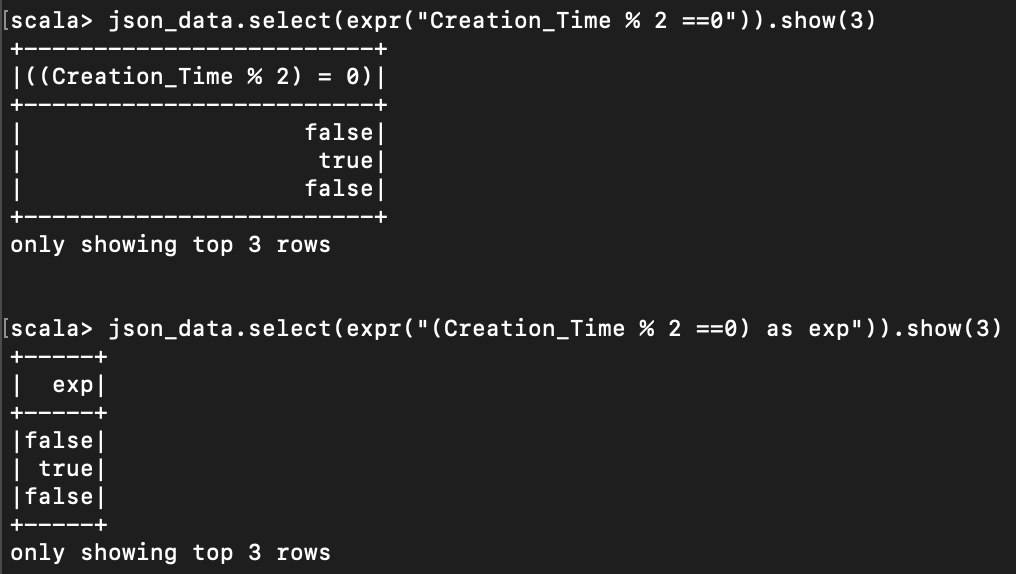
< 표현식으로 column 연산하기 >
expr 을 사용하여 원하는 대로 연산할 수 있다.
json_data.select(expr("Creation_Time % 2 ==0")).show(3)
json_data.select(expr("(Creation_Time % 2 ==0) as exp")).show(3)
" " 안에서 가장 끝에 as something 을 붙이면, column 의 이름으로 바뀐다.
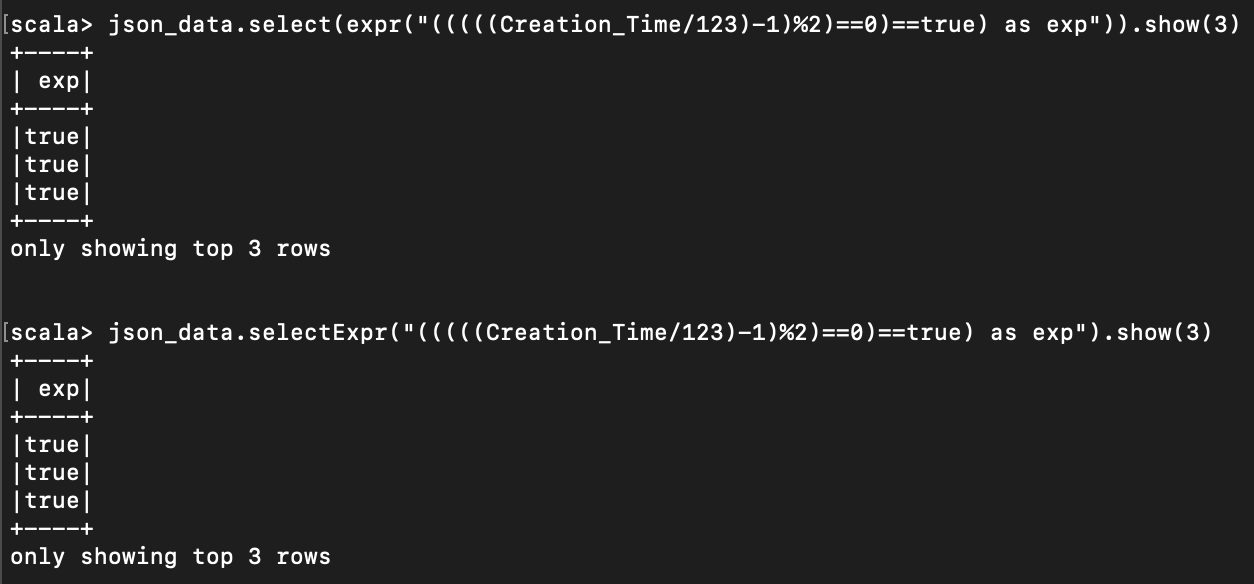
가령, Creation_Time 을 123 으로 나눈 값에서 1을 뺀 값이 짝수인지 나타내는 bool 값이 true 인 값은 아래처럼 쓸 수 있다.
json_data.select(expr("(((((Creation_Time/123)-1)%2)==0)==true) as exp")).show(3)
json_data.selectExpr("(((((Creation_Time/123)-1)%2)==0)==true) as exp").show(3)
< 간단하게 직접 DataFrame 만들기 >
val myDF = Seq(("String", 100)).toDF("String", "Integer")
혹은
val sentenceData = spark.createDataFrame(Seq(
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
)).toDF("label", "sentence")
위와 같이 toDF 괄호 사이에 값들을 넣어주면, 그것이 그 열의 이름이 된다.
< Row 에 접근하기 >
import org.apache.spark.sql.Row
val myRow = Row("String", 100)
myRow(0) //"String"
myRow(1) //100
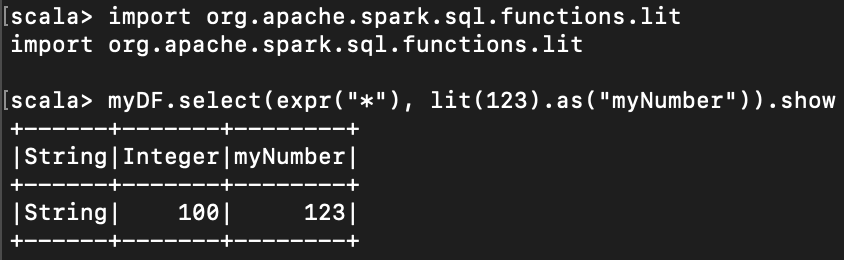
< 명시적인 값을 직접 dataframe 에 넣기 >
내가 직접 123 값을 dataframe column에 넣을 수 있다.
import org.apache.spark.sql.functions.lit
myDF.select(expr("*"), lit(123).as("myNumber")).show
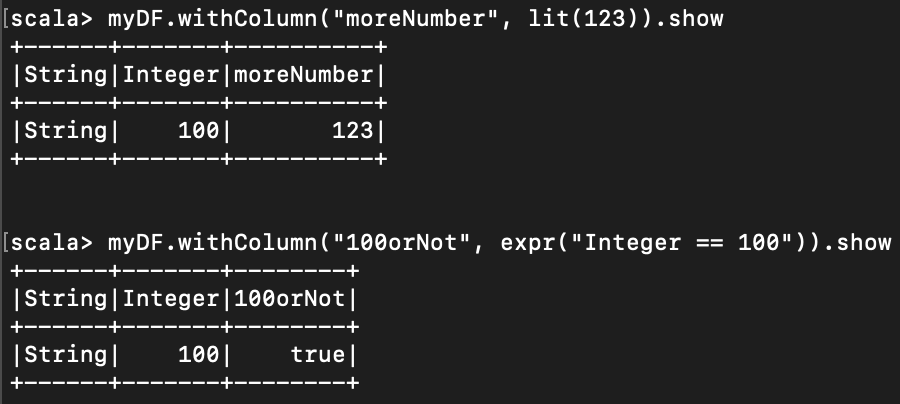
위에서처럼 select 를 써도 좋지만, withColumn 을 사용할 수 도 있다. 이게 더 직접적인 방법.
myDF.withColumn("moreNumber", lit(123)).show
myDF.withColumn("100orNot", expr("Integer == 100")).show
lit("five"), lit(3.0), lit(4) 등을 넣을 수 있다.
< column 제거하기 >
myDF.drop("Integer").show
myDF.drop("Integer","abc").show
< column 캐스팅. 형변환 >
아래 명령어를 통해, Int 형이었을 "Integer" column 이 String 으로 바뀐 걸 볼 수 있다.
myDF.withColumn("Integer", col("Integer").cast("string"))

< column 명 변경 >
아래 명령어로 "A" 컬럼의 이름을 "B" 로 바꿀 수 있다.
myDF.withColumnRenamed("A", "B").columns
< Row 필터링 하기 >
아래처럼 filter 명령어를 사용한다.
filter 대신 where 를 사용해도 무방.
filter 내에는 bool 값이 들어가야 한다.
json_data.filter(expr("Creation_Time % 2 == 0")).select(col("Creation_Time")).show(2)

df.filter(col("count") < 2)
df.where("count < 2")
filter 여러번 하는 명령어 예제
df.whee(col("count") < 2).where(col("COUNTRY_NAME") =!= "KOREA").show(2)
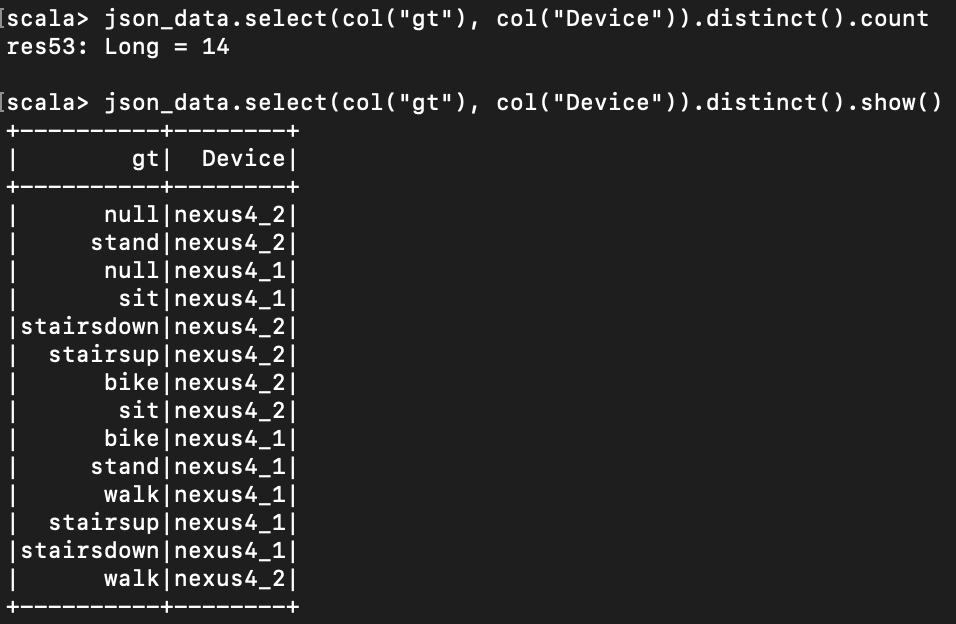
< 중복 제거하기 >
select로 gt 와 Device 쌍을 가져온 다음, 중복되지 않은 쌍들만 남겨두는 명령어는 다음과 같다.
json_data.select(col("gt"), col("Device")).distinct().count
json_data.select(col("gt"), col("Device")).distinct().show()
< 로우 정렬 하기 >
"A" 와 "B" 를 정렬한다고 하자.
df.sort("A")
df.orderBy("A", "B")
df.orderBy(col("A"), col("B"))
df.orderBy(expr("A desc"))
df.orderBy(asc("A"), desc("B"))
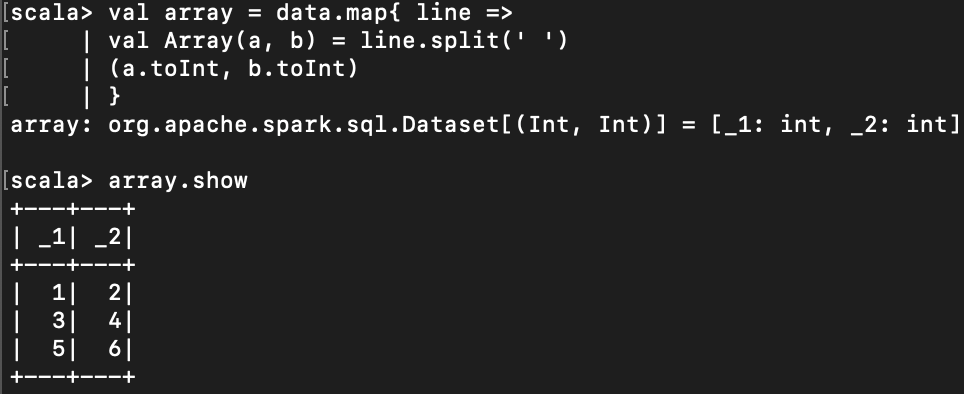
< split >
아래 예에서는 white space (공백 문자)를 기준으로 나누었다.
val array = data.map{ line =>
val Array(a, b) = line.split(' ')
(a.toInt, b.toInt)
}
< dataframe 에서 null 값이 없는 부분만 필터링하여 처리 >
아래처럼 if 와 None, Some, try-catch 를 사용하여 처리한다.
val array2 = data.flatMap{ line =>
val Array(a, b) = line.split(" ")
if(a.isEmpty) {
None
} else {
try {
Some ((a.toInt, b.toInt))
} catch {
case _: NumberFormatException => None }}}
< csv 파일 읽을 때 option 넣는 법>
아래와 같은 방식으로 csv 파일을 읽을 수 있다. 이 때 옵션을 달 수 있고, 아래처럼 달면 된다.
val df = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("/csvData")
옵션들 설명 출처
Spark의 csv 관련 옵션들Spark 2.x에서는 다음과 같은 csv 관련 옵션을 제공한다. 출처는 Scala 공식 API 문서 이며, 소스 코드가 궁금한 분들은 여기를 보면 된다. 이해하기 어렵거나 중요한 옵션에만 설명을 달았다.
|
< Socket Streaming >
아래는 socket 으로 받은 데이터를 실시간으로 워드카운트 하는 코드임.
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate()
import spark.implicits._
spark.conf.set("spark.sql.shuffle.partitions", 5)
val lines = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split(" "))
// Generate running word count
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream.outputMode("complete").format("console").start()
query.awaitTermination()
다른 터미널에서 nc -lp 9999 로 9999 포트를 연 후
원하는 문자를 타이핑하면 된다.
< 같은지 다른지 확인 >
아래처럼 === 와 =!= 를 사용하여 같은지 다른지 확인 가능하다.
참고로 Array 의 indexing 하려면 괄호로 ( index ) 이렇게 하면 된다.
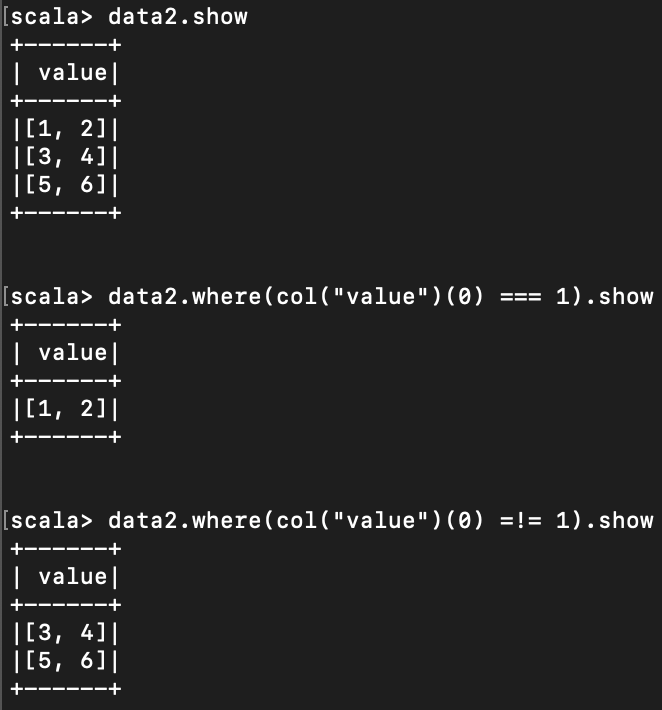
===대신 = 를,
=!= 대신 <> 를 사용할 수 있다.
둘의 차이는 나중에 찾아봐야겠다
ㅎㅎ
< 현재 날짜와 타임스탬프 구하기>
import org.apache.spark.sql.functions.{current_date, current_timestamp}
val timeDF = spark.range(3)
.withColumn("today", current_date())
.withColumn("now", current_timestamp())
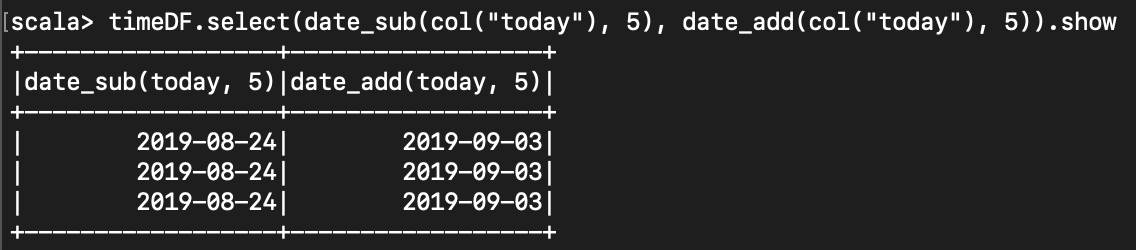
< 현재 날짜에서 일 수 더하기 >
import org.apache.spark.sql.functions.{date_add, date_sub}
timeDF.select(date_sub(col("today"), 5), date_add(col("today"), 5)).show
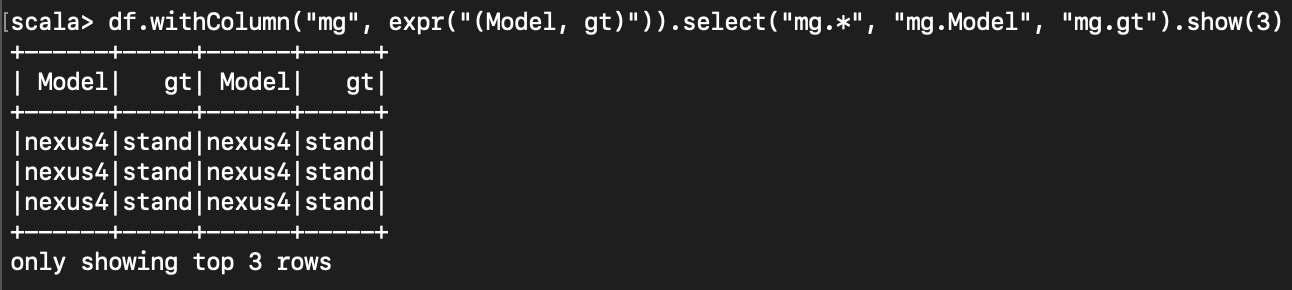
< dataframe 안에 dataframe 만들기 >
아래와 같이, select 등을 할 때 표현식과 소괄호() 를 이용하여 구조체를 만들 수 있다.
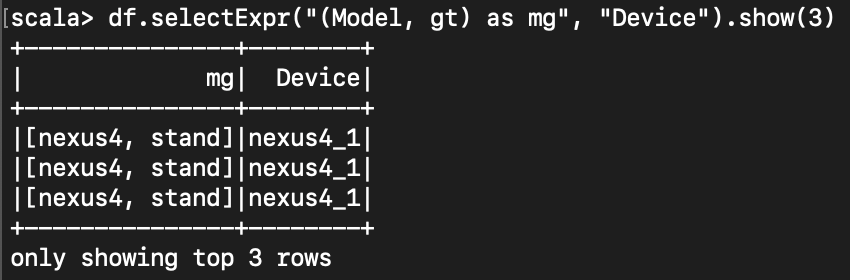
구조체에 접근할 땐 dot ( . ) 을 사용한다.
df.withColumn("mg", expr("(Model, gt)")).select("mg.*", "mg.Model", "mg.gt").show(3)
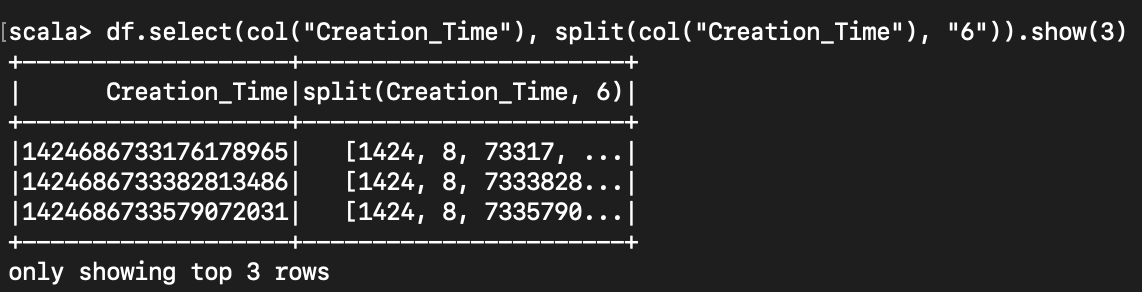
< String 을 split 하여 배열로 만들기 >
df.select(col("Creation_Time"), split(col("Creation_Time"), "6")).show(3)
배열에 column name 을 주고 싶을 때는 alias 를 사용하고,
배열에 직접 indexing 하여 접근할 때는 표현식과 대괄호[] 를 사용함.
df.select(split(col("Creation_Time"), "6").alias("bySix")).selectExpr("bySix[2] as bySix").show(3)

"A" 를 tap 으로 잘라서 배열로 만들기
df.split("A", "\t")
그럼 위위의 그림처럼, 하나의 컬럼 내에 [a,b,c....] 라는 배열이 만들어짐 -_-
< split 개수 세기 >
df.select(size(split(col("Creation_Time"), "6"))).show(3)
"Creation_Time" column 의 값들을 6을 기준으로 나누고, 그 나눈 개수를 보여준다.
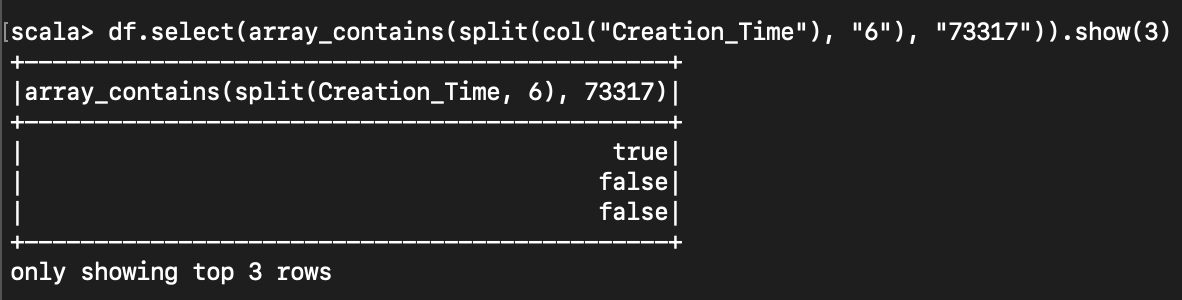
< 배열안에 포함되어있는지 확인 >
import org.apache.spark.sql.functions.array_contains
df.select(array_contains(split(col("Creation_Time"), "6"), "73317")).show(3)
< 함수 만들기 >
def 를 통해 함수를 만들 수 있다.
받은 값의 세제곱을 하는 power3 함수를 만들어보자.
def power3(number: Double):Double = {
number * number * number
}
def 함수이름(인자값이름: 인자값타입): 함수반환값타입 = { 함수 내용}
사용할 땐 함수이름(인자값) 식으로 사용 가능하다.

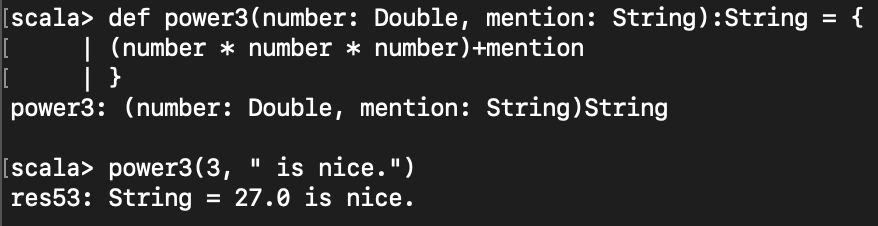
아래는 서로 다른 타입의 인자를 주는 예제이다.
def power3(number: Double, mention: String):String = {
(number * number * number)+mention
}
dataframe 에서 위의 첫번째 함수를 사용하려고 하면, 에러가 난다.
val udfEx = spark.range(5)
udfEx.select(power3(col("id"))).show
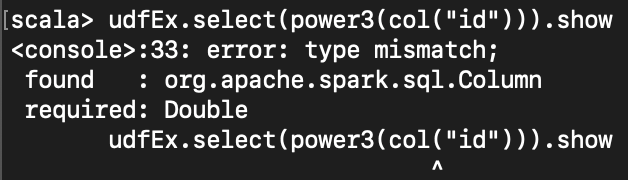
dataframe 에서 사용하기 위해선 udf 에 등록해야 한다.
val power3udf = udf(power3(_:Double):Double)
udfEx.select(power3udf(col("id"))).show
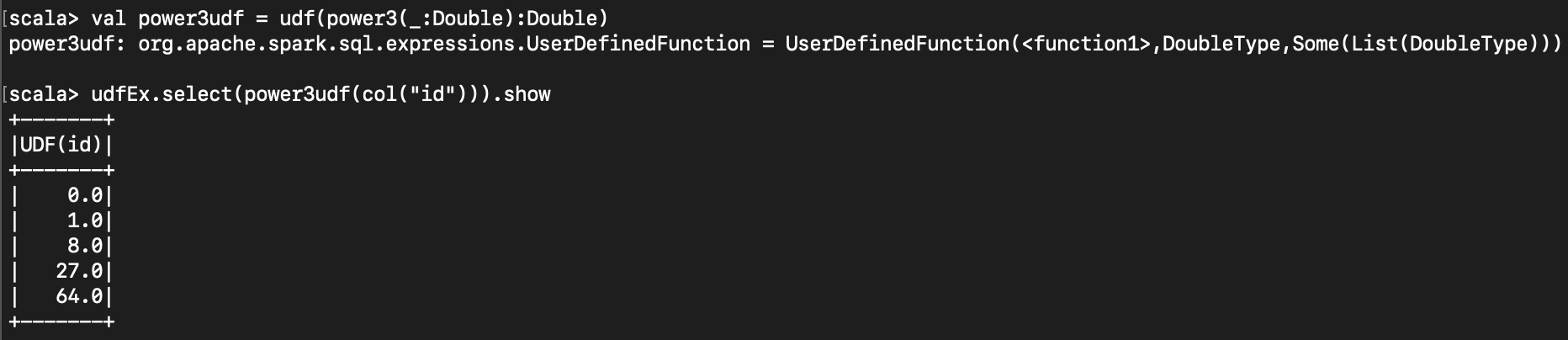
표현식 ( expr ) 에서 해당 함수를 사용하고 싶다면, sql 함수로 등록해야 한다.
spark.udf.register("power3" , power3(_:Double):Double)
udfEx.selectExpr("power3(id)").show
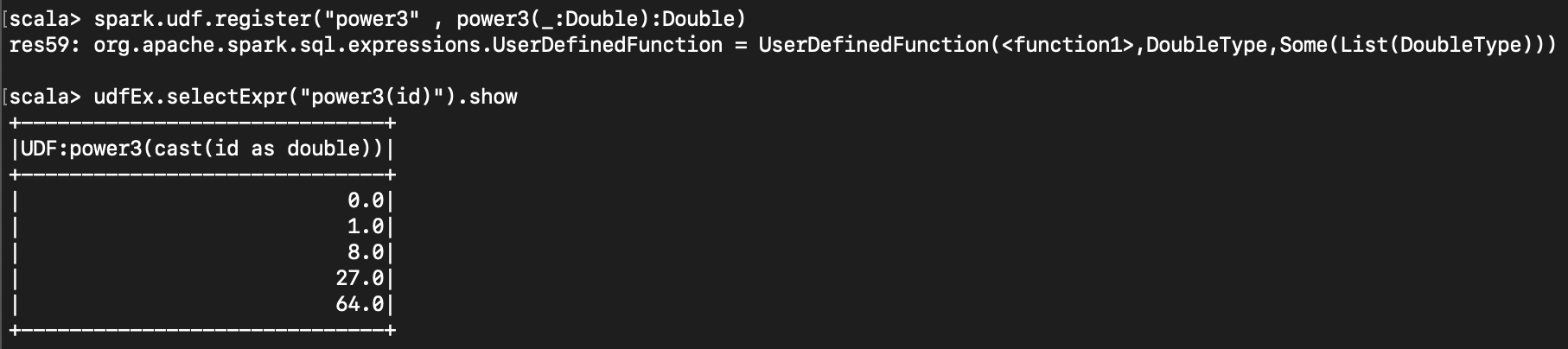
< boolean 값으로 filtering 하기 >
df.where(col("InvoiceNo").equalTo(12345))
.select("InvoiceNo")
.show
df.where(col("InvoiceNo") === 12345)
.select("InvoiceNo")
.show
df.where(col("InvoiceNo") =!= 12345)
.select("InvoiceNo")
.show
이렇게 조건문을 따로 만들어서 넣을 수 있다.
val priceFilter = col("UnitPrice") > 600
val descripFilter = col("Description").contains("EYEBALLS")
df.where(col("Code").isin("DOT"))
.where(priceFilter.or(descripFilter))
.show
df.withColumn("isExpensive", not(col("Price").leq(250)))
.show
< 숫자형 다루기 >
column 값으로 제곱이나 더하기, 곱하기 등의 식을 만들어 본다.
column 으로부터 읽은 숫자들을 이용하여
(수량 * 가격)^2 + 5 를 계산해보자.
import org.apache.spark.sql.functions.{expr,pow}
val calc = pow(col("Quantity") * col("Price"), 2)+5
df.select("CustomerId", calc.alias("result")).show
혹은
df.selectExpr(
"CustomerId",
"(POWER((Quantity * Price), 2.0) + 5) as "result")
.show
< 문자열 데이터 다루기 >
문자 전체를 대문자, 혹은 소문자로 바꾸는 명령어
import org.apache.spark.sql.functions.{lower, upper}
df.lower(col("Str")).show
df.upper(col("Str")).show
1->a 로, 2->b 로 치환하는 명령어
df.translate("Str", "ab", "12")
val alpha = Seq("A","B","C","D")
val selectedColumns = alpha.map( item => {
col("alphabet").contains(alpha.toUpperCase).alias(s"$alpha")
})
< null 값 다루기 >
coalesce 함수는 지정한 여러 컬럼 중 null 이 아닌 첫번째 값을 반환
만약 모든 컬럼이 null 이 아니라면 첫번째 컬럼값 반환
df.select(coalesce(col("A"), col("B"))).show
drop 메소드로 null 값을 가진 로우를 제거
df.na.drop()
df.na.drop("any")
df.na.drop("all")
any : 로우의 컬럼값 중 하나라도 null 값을 갖으면 해당 로우 제거
all : 모든 로우의 컬럼값이 null 이거나 NaN인 경우에만 해당 로우 제거
null 값을 다른 값으로 바꾸는 명령어
df.na.replace("AA", Map(""=>"replaced"))
< X 로 시작하는 글자 필터링 >
함수 하나를 만든 후, 그 함수에 map 으로 값을 넣어서 true 가 나온 것만 필터링한다.
def startsWithX(item : String) = {
item.startsWith("X")
}
words.filter(word => startsWithX(word)).show
< map 사용 예제 >
val result = words.map( word=>(word, word(0)))
._2에 boolean 값이 있다면 ._2 가 true 인 것만 필터링
val result = words.map( word => word._2).show
< 빈 dataframe 만들기 >
val empty = Seq.empty[(String,String,String)].toDF
val empty2 = Seq.empty[(String,Int, Int, String)].toDF("name","age","weight","sex")
< column 값을 Array List 로 만들기 >
아래 명령어를 사용하면 되지만, collect 를 사용하는 명령어이므로
너무 큰 column 을 대상으로 하면 안 되겠다.
dataFrame.select("YOUR_COLUMN_NAME").rdd.map(r => r(0)).collect()
< 외부 scala import >
import 하고 싶은 스칼라가 위치하는 path 가 ./src/main/scala/Hello.scala 라고 하자.
scala> :load ./src/main/scala/Hello.scala
< URL UTF-8 encoding, decoding >
data 에 인코딩/디코딩 하고 싶은 값을 넣는다.
import java.net.URLDecoder
import java.net.URLEncoder
val decode = URLDecoder.decode(data, "UTF-8")
val encode = URLEncoder.encode(data, "UTF-8")
아래처럼 함수를 만들어 써도 좋다.
def decodeUTF8(str : String) : String = {
URLDecoder.decode(str, "UTF-8")
}
def encodeUTF8(str : String) : String = {
URLEncoder.encode(str, "UTF-8")
}
아래 사이트에서 encoding/decoding 을 해볼 수 있다.
< 시간 관련 기능들 >
너무 길어져서 따로 씀
아래 참고
https://eyeballs.tistory.com/274
'Spark' 카테고리의 다른 글
| [Spark Streaming] Structured Streaming 공부에 도움 되는 사이트 (0) | 2019.09.03 |
|---|---|
| [Spark] Docker 로 Spark 클러스터 구성하는 방법 (2) | 2019.08.30 |
| [Spark Streaming] trigger, window, sliding 이해 하기 (0) | 2019.08.22 |
| [Spark] YARN 위에서 Application 을 실행하는 단계 (0) | 2019.07.25 |
| [Spark] value toDF is not a member of org.apache.spark.rdd.RDD 에러 (0) | 2019.07.19 |