간단한 기능 테스트를 위한 Hadoop 의사 분산 (pseudo-distributed) 모드 설치 방법을 설명한다.
localhost 에 설치할 것이고, 각종 옵션 등의 설명은 없다.
오로지 기능 테스트를 위해 간단하게만 설치한다.
docker 를 이용하면 쉽게 설치할 수 있지만, 여기서는 그냥 local 에 곧바로 설치한다.
< 환경 >
Ubuntu 20.04.2 LTS 64비트
java 가 local 에 1.8 이상 버전으로 설치되어 있어야 한다.
설치하는 dir 는 /home/eye/standalone 이라고 하자.
< 사전 준비 >
참고 : password 없이 ssh 연결하기
자신의 local 로 ssh 통신을 비밀번호 없이 진행해야 한다.
| ssh-keygen -t rsa |
비밀번호를 물으면 enter 를 계속 쳐서 넘어가자.
그래야 비밀번호가 없는 상태로 ssh 통신이 가능하다.
마지막으로 아래 명령어를 실행한다.
| cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys service ssh start service ssh status |
아래 명령어로 localhost 에 ssh 접근시 비밀번호 없이 접근 가능하면 성공
| ssh localhost |
< Hadoop Standalone >
hadoop download : hadoop.apache.org/releases.html
Apache Hadoop
Download Hadoop is released as source code tarballs with corresponding binary tarballs for convenience. The downloads are distributed via mirror sites and should be checked for tampering using GPG or SHA-512. Version Release date Source download Binary dow
hadoop.apache.org
원하는 버전의 binary 를 다운받는다.
나의 경우 3.3.0 버전을 받으려고 한다.
| wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz --no-check-certificate |
압축을 해제한다.
| tar zxvf hadoop-3.3.0.tar.gz |
압축이 풀리면 hadoop-3.3.0 dir 가 생긴다.
이제부터 Hadoop home(HADOOP_HOME) 의 path 는 /home/eye/standalone/hadoop-3.3.0 이다.
아래 설명부터, HADOOP_HOME 이라고 된 부분을
/home/eye/standalone/hadoop-3.3.0 로 대체해서 생각하면 된다.
여기를 참고하여 HADOOP_HOME 을 설정한다.
| export HADOOP_HOME=/root/hadoop-3.3.2 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin |
path 추가한 뒤 source 명령어를 통해 적용하는 것을 잊지 말자.
HADOOP_HOME/etc/hadoop 으로 이동한다.
core-site.xml 에 다음과 같은 property 를 추가한다.
| < core-site.xml > |
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> |
hdfs-site.xml 에 다음과 같은 property 를 추가한다.
아래 property는 추가하지 않아도 동작은 한다
테스트용으로 만드는 standalone 의 replication 을 3(default) 으로 두면
디스크 공간 차지하니까 1로 바꾸는 것.
| < hdfs-site.xml > |
| <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> |
hadoop mapreduce 를 사용하려면 아래 mapred-site.xml 와 yarn-site.xml 를 업데이트한다.
사용하지 않고 그냥 hdfs 와 yarn 만 사용하려면 아래 두 가지는 업데이트 안 해도 됨.
mapred-site.xml 에 다음과 같은 property 를 추가한다.
| < mapred-site.xml > |
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=[A. HADOOP_HOME path 를 넣음]</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=[A. HADOOP_HOME path 를 넣음]</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=[A. HADOOP_HOME path 를 넣음]</value> </property> <property> <name>mapreduce.application.classpath</name> <value>[B. hadoop classpath 를 넣음]</value> </property> </configuration> |
위에서 [A. HADOOP_HOME path 를 넣음] 이라고 된 부분에는
echo ${HADOOP_HOME} 명령으로 출력된 결과를 넣으면 된다.
위에서 [B. hadoop classpath 를 넣음] 이라고 된 부분에는
echo $(hadoop classpath) 명령으로 출력된 결과를 넣으면 된다.
참고 : https://stackoverflow.com/a/61171283
yarn-site.xml 에 다음과 같은 property 를 추가한다.
| < yarn-site.xml > |
| <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
hadoop-env.sh 에 다음과 같은 property 를 추가한다.
| < hadoop-env.sh > |
| export JAVA_HOME=[C. JAVA_HOME 을 넣음] export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root" |
위에서 [C. JAVA_HOME 을 넣음] 이라고 된 부분에는
echo ${JAVA_HOME} 명령으로 출력된 결과를 넣으면 된다.
다음 명령어를 통해 namenode 를 포맷한다.
| $HADOOP_HOME/bin/hdfs namenode -format |
다음 명령어를 통해 hdfs 와 yarn, 그리고 historyserver 를 실행시킨다.
| $HADOOP_HOME/sbin/start-dfs.sh $HADOOP_HOME/sbin/start-yarn.sh $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver |
(참고로 hdfs 와 yarn 실행을 멈추는 명령어는 다음과 같다.)
| $HADOOP_HOME/sbin/stop-dfs.sh $HADOOP_HOME/sbin/stop-yarn.sh $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh stop historyserver |
jps 명령어를 통해 나온 결과에 다음과 같이 떠 있으면 된다.
| Jps NameNode SecondaryNameNode DataNode ResourceManager NodeManager JobHistoryServer |
hdfs 사용시 binary 를 직접 지정하여 사용한다.
왜냐면 여기선 bin path 지정을 하지 않았으니까(테스트 용도)
| $HADOOP_HOME/bin/hdfs dfsadmin -report |
yarn 도 마찬가지 방법으로 사용하면 된다.
| $HADOOP_HOME/bin/yarn application -list |
다음 명령어를 통해 wordcount 예제를 실행해본다.
| hdfs dfs -mkdir -p /user/root/wordcount_input hdfs dfs -copyFromLocal $HADOOP_HOME/share/doc/hadoop/index.html /user/root/wordcount_input/ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar wordcount /user/root/wordcount_input/index.html /user/root/wordcount_output hdfs dfs -ls /user/root/wordcount_output/ hdfs dfs -cat /user/root/wordcount_output/part-r-00000 | head -n 5 |
만약 JAVA_HOME 을 찾지 못한다는 error 가 뜨면
HADOOP_HOME/etc/hadoop/hadoop-env.sh 에 JAVA_HOME 을 넣는다.
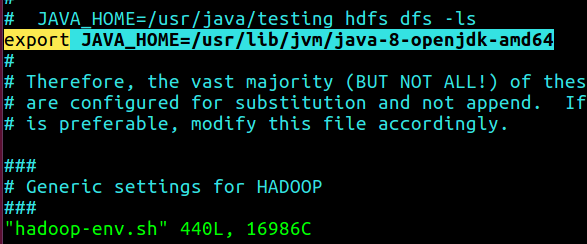
JAVA_HOME 찾는 방법은 여기 글 참고
만약 다음과 같은 에러가 뜬다면
| Starting namenodes on [localhost] ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation. Starting secondary namenodes [071a81671aa4] ERROR: Attempting to operate on hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation. Starting resourcemanager ERROR: Attempting to operate on yarn resourcemanager as root ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation. Starting nodemanagers ERROR: Attempting to operate on yarn nodemanager as root ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation. |
HADOOP_HOME/etc/hadoop/hadoop-env.sh 에 아래 내용을 넣는다.
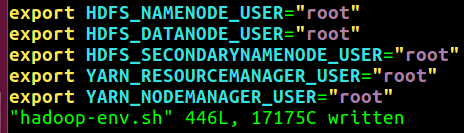
| export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root" |
출처 : stackoverflow.com/a/48170409
'Hadoop' 카테고리의 다른 글
| [Hadoop] Sequence file 간단 설명 (0) | 2021.09.04 |
|---|---|
| [YARN] NodeManager 재실행하면, 실행중이던 job들은 죽을까? (0) | 2021.07.20 |
| [HDFS] du 옵션 출력 결과 설명 (0) | 2020.12.01 |
| [Parquet] csv, tsv 데이터를 Parquet 으로 변환하는 방법 링크 (0) | 2020.08.26 |
| [Hadoop] InputSplit 이 Block Boundary 를 넘어 데이터를 읽는 방법 (2) | 2020.08.17 |