Map Task 에선 input split 이라는 단위만큼의 데이터를 대상으로 작업을 진행된다.
데이터는 block size 단위로 나뉘어 저장된다 (input split 과 block size 는 서로 다른 개념)
따라서 데이터를 이루고 있는 row(record, line) 가 중간에 잘려서 저장될 수 있다.
이러한 데이터에 대해 MR 을 실행하면, Map은 input 으로 어떤 데이터를 받을까?
Map은 input split 만큼의 데이터를 가져오는데 이때 중간에 끊어진 row 는 볼 수 없다.
이유를 그림과 함께 아래서 설명한다.

위의 그림을 보면 11줄로 이루어진 file 이 똑같은 크기 만큼의 block size 로 잘려있다.
line 은 제각각 크기가 다르므로 block size 에 딱 맞질 않아 중간에 잘려버렸다( 5번, 9번 줄)
이 file 을 대상으로 MR 을 시도할 때 Map은 (크기를 바꾸지 않았다면) block size 만큼의 input split 데이터를 읽을 것이다.
이 때 input split 은 5번처럼 잘려있는 데이터를 잘린 곳 까지 읽지 않고, 해당 line 의 끝(EOL : End Of Line)까지 읽는다.
두 번째 block 을 처리하는 Map 의 input split 은 어떻게 동작할까?
두 번째 block 은 5번의 중간부터 시작하고 있다.
input split 내에서 호출하는 RecordReader 메소드에 의해 "block의 첫번째 line 이 5번처럼 중간에 잘려있는 경우, 첫째 line은 읽지 않고(skip) 넘어가게 된다".
즉, input split 에서 5번 데이터는 읽지 않고 6번부터 읽기 시작하여 9번의 EOL 까지 읽어온다.
이제 그림을 보면 이해가 될 것이다.
서로 다른 곳에 저장된 5번, 9번 데이터를 EOL 까지 읽게 되면
(두 개로 나뉘어진 5번 혹은 9번 line 이 같은 장소에 있지 않고 다른 장소에 있을 수 있기 때문에)
다른 지역/원격의 장소에 있는 데이터를 읽어야 하기 때문에
네트워크 오버헤드가 발생하는 게 아니냐?
라는 질문에는 그렇다. 잘 이해했다 라고 답변할 수 있겠다.
아래는 하둡 완벽가이드 4판의 p305 에서 발췌한 내용이다.
< 입력 스플릿과 HDFS 블록 간의 관계 > FileInputFormat 이 일반적으로 정의하는 논리적인 레코드는 HDFS 블록과 딱 맞아 떨어지지 않는다. 예를 들어 TextInputFormat 의 논리적인 레코드는 개행 문자 등으로 분리되는 행인데, 각 행이 HDFS 의 블록 경계를 넘나드는 경우가 빈번하다. 하지만 이것이 프로그램이 제대로 동작하는 데 문제가 되지는 않는다. 예를 들어 행이 유실되거나 끊어지지 않기 때문이다. 하지만 데이터-로컬 맵(즉, 입력 데이터와 같은 호스트에서 수행되는 맵)이 약간의 원격 읽기 작업을 수행할 수 있으므로 이러한 점을 이해하는 것은 물론 의미가 있다. 이것 때문에 발생하는 약간의 오버헤드는 심각한 문제가 아니다. 위의 그림을 살펴보자. 단일 파일이 여러 행으로 나눠지고 각 행의 경계가 HDFS 블록의 경계와 일치하지 않는다. 스플릿은 논리적인 레코드 경계를 지키며(여기서는 행), 따라서 5번째 행이 첫 번째와 두 번째 블록에 걸쳐 있지만, 첫 버너째 스플릿은 이 행을 제대로 포함하고 있다. 두 번재 스플릿은 6번째 행에서 시작된다. |
다른 예를 들어보자.
두 줄 밖에 안 되는 파일이 있다.
근데 한 줄당 100mb 크기이다.
이것을 64mb block size 기준으로 HDFS 에 저장하였고
아래 그림처럼 block 4개로 나뉘어졌다.
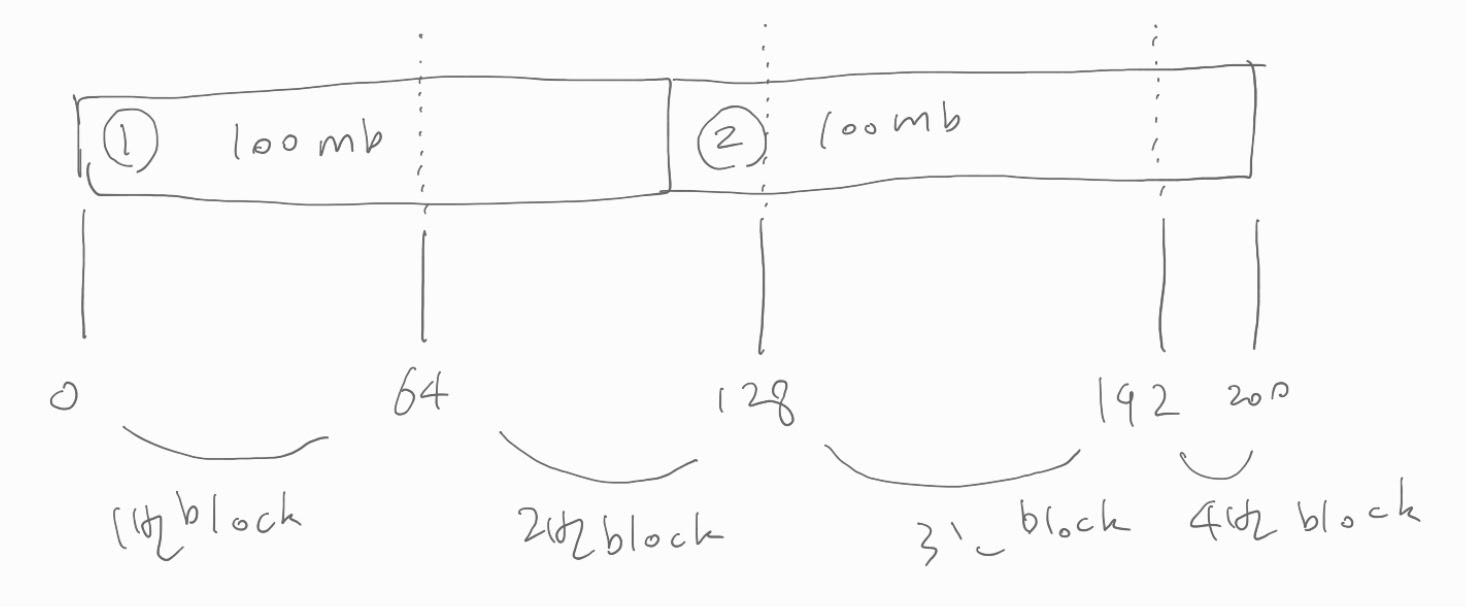
4개의 block 을 하나씩 읽어 총 4개의 Mapper 가 동작하게 된다.
순서대로 보자.

첫번째 Mapper 는 1번 block 을 읽어온다.
1번 block 의 처음 부분이 나뉘어지지 않는, 시작점을 갖고 있으므로 skip 하지 않고 읽는다.
어디까지 읽냐면, line 의 끝(EOL) 까지.
따라서 1번 block 을 넘어가는 부분(2번 block 위치)은 remote read 를 할 수 있는 상황이 된다.

두번째 Mapper 는 2번 block 을 읽어온다.
2번 block 의 처음 부분은 나뉘어져서, 시작점을 갖지 않으므로 skip 하고 다음 line 을 읽는다.
다음 line 이라고 하면 ② 라고 표시한 부분.
어디까지 읽냐면, line 의 끝(EOL) 까지.
따라서 2번 block 을 넘어가는 부분(3번, 4번 block 위치) 은 remote read 를 할 수 있는 상황이 된다.

세번째 Mapper 는 3번 block 을 읽어온다.
3번 block 의 처음 부분은 나뉘어져서, 시작점을 갖지 않으므로 skip 하고 다음 line 을 읽는다.
다음 line 을 읽으려고 봤더니 이미 다 읽었네.
그럼 아무것도 하지 않는다.
네번째 Mapper 역시 마찬가지로 아무것도 하지 않는다.
input split 크기와 block size 는 대개 같은 크기로 지정한다.
만약 input split 크기가 block size 보다 크거나 작다면,
위에서 여태 설명한 것처럼 block size 를 기준으로 조각이 생겨서
서로 다른 노드에 저장 될 것이고
Map Task 에서 하나의 input split 을 읽기 위해
서로 다른 노드에 저장된 데이터를 읽을 것이고
그에 따라 귀중한 '네트워크 대역폭'이라는 자원이 소모되기 때문이다.
이 사실을 알게 되어 기쁘다.
역시 공부는 즐거워
'Hadoop' 카테고리의 다른 글
| [HDFS] du 옵션 출력 결과 설명 (0) | 2020.12.01 |
|---|---|
| [Parquet] csv, tsv 데이터를 Parquet 으로 변환하는 방법 링크 (0) | 2020.08.26 |
| [Hadoop] Balancer vs Diskbalancer 차이를 이제 알겠다 (2) | 2020.08.17 |
| [Hadoop] 하둡 스트리밍에 대한 설명 링크 (0) | 2020.07.31 |
| [Hadoop] RPC 에 대한 간단한 설명 및 링크 (0) | 2020.07.29 |