Hadoop MR(MapReduce) 에서 흔하게 사용하는 파일 포맷은 text 파일 포맷임
하지만 binary 파일도 사용가능한데, Sequence File 이 바로 Binary 파일 포맷임.
Sequence File 은, 직렬화된 k-v 쌍으로 이루어짐.
(Hadoop Sequence File is a flat file structure which consists of serialized key-value pairs)
Sequence File 은 내부적으로 kv 쌍으로 이루어진 데이터들을 갖는 일종의 binary 파일 포맷이라고 생각하자.
장점 :
- text 파일 포맷보다 읽기, 쓰기 속도가 빠르다.
- 하둡이 처리하기 힘든 작은 크기의 수많은 파일들을 Sequence File 하나로 묶으면(k는 파일이름(+타임스탬프), v는 파일 내용 등으로) 쉽게 처리할 수 있다. 그러면 YARN NameNode 메모리에 올라가는 메타데이터 양을 줄이는 이득을 볼 수 있다.
- 분할이 가능하기 때문에 지역성 이득을 보면서 분산 처리가 가능하다.
- 압축 가능하기 때문에 저장 공간을 아낄 수 있다.
Sequence File 은 공간 절약을 위한 압축도 가능하다.
다음 세 가지 타입으로 압축 가능.
- Uncompressed (압축하지 않는 것)
- Record Compressed
- Block Compressed (HDFS 의 128mb 그 블럭이 아님)
Sequence File 에는 헤더가 붙어있고, 그 헤더는 meta-data 를 갖고 있음.
이 meta-data 는 이 파일의 포맷정보, 압축 된 것인지 아닌지에 대한 정보 등을 담고 있으며
file reader 가 파일을 읽을 때 사용함.
(This header consists of all the meta-data which is used by the file reader to determine the format of the file or if the file is compressed or not.)
File 헤더는 다음과 같이 구성됨

- Version : 헤더의 가장 첫 번째 데이터. 처음 3byte 는 "SEQ" 라는 고정값이 들어오고, 다음 1byte 에 버전값이 들어온다. 만약 6버전이라면 Version 은 "SEQ6", 13버전이라면 "SEQ13"
- Key Class Name : k-v 쌍에서 key 의 클래스를 나타냄. text class 가 오거나 함.
- Value Class Name : k-v 쌍에서 value 의 클래스를 나타냄. text class 가 오거나 함.
- Is Compression : 파일이 압축되었는지 여부를 알려줌.
- Is Block Compressed : 파일이 블록 압축되었는지 알려줌.
- Compression Codec : 데이터를 압축하고 압축 해제하는 데 사용하는 코덱의 클래스를 나타냄. 여기서 '코덱'을 압축 알고리즘이라고 생각하면 편함.
- Metadata : 혹시 더 필요할지 모를 또 다른 metadata 를 제공하는 k-v 페어
(Key-value pair which can provide another metadata required for the file.) - Sync Marker : 헤더의 끝을 나타내는 마커.
좀 더 확실한 이해를 위해 예를 들어봄.
아래 데이터처럼 k-v 로 되어있는 text 파일이 존재함.
(k 와 v 는 white space 로 구분되어 있음)

지금부터 할 것은 위의 text 데이터를
하둡 Map Reduce 를 통해 HDFS 에
Sequence file 형태로 저장 할 것임
간단한 MR 코드를 아래처럼 작성
참고로 Reducer 는 없고 Mapper 만 동작하도록 함
굵게 bold 처리 한 부분만 읽어도 됨
< SequenceFileWriterMapper.java >
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 맵리듀스 패키지의 매퍼 클래스(Mapper class)
* 크게 하는 일은 없고, 단지 key-value 로 읽은 데이터를 context 에 곧바로 씀
*
* @author Raman
*
*/
public class SequenceFileWriterMapper extends Mapper {
/**
* map 함수. 아무 일도 안함.
* 단지 key-value 페어를 context 에 그대로 쓰기만 함
* 쓰여진 key-value 페어는 Sequence file 포맷으로 저장 될 예정
*/
@Override
protected void map(Text key, Text value,Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
|
cs |
< SequenceFileWriterApp.java >
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* The entry point for the Sequence Writer App example,
* which setup the Hadoop job with MapReduce Classes
*
* @author Raman
*
*/
public class SequenceFileWriterApp extends Configured implements Tool
{
/**
* Main function which calls the run method and passes the args using ToolRunner
* @param args Two arguments input and output file paths
* @throws Exception
*/
public static void main(String[] args) throws Exception{
int exitCode = ToolRunner.run(new SequenceFileWriterApp(), args);
System.exit(exitCode);
}
/**
* Run method which schedules the Hadoop Job
* @param args Arguments passed in main function
*/
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s needs two arguments files\n",
getClass().getSimpleName());
return -1;
}
//Initialize the Hadoop job and set the jar as well as the name of the Job
Job job = new Job();
job.setJarByClass(SequenceFileWriterApp.class);
job.setJobName("SequenceFileWriter");
//Add input and output file paths to job based on the arguments passed
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//input 은 text file 포맷으로 설정. 왜냐면 읽을 데이터가 text 파일이니까
//output 은 sequence file 포맷으로 설정. 왜냐면 sequence file 로 저장하고 싶으니까
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
//위에서 만든 매퍼의 클래스가 여기 적용됨
job.setMapperClass(SequenceFileWriterMapper.class);
//리듀서는 사용하지 않을 예정기에 리듀스 태스크 수는 0 으로 세팅
job.setNumReduceTasks(0);
//Wait for the job to complete and print if the job was successful or not
int returnValue = job.waitForCompletion(true) ? 0:1;
if(job.isSuccessful()) {
System.out.println("Job was successful");
} else if(!job.isSuccessful()) {
System.out.println("Job was not successful");
}
return returnValue;
}
}
|
cs |
위의 코드로 MR 작업을 실행한 후 결과를 출력해보면
아래와 같이 이상한 모양으로 출력되는 것을 확인할 수 있음
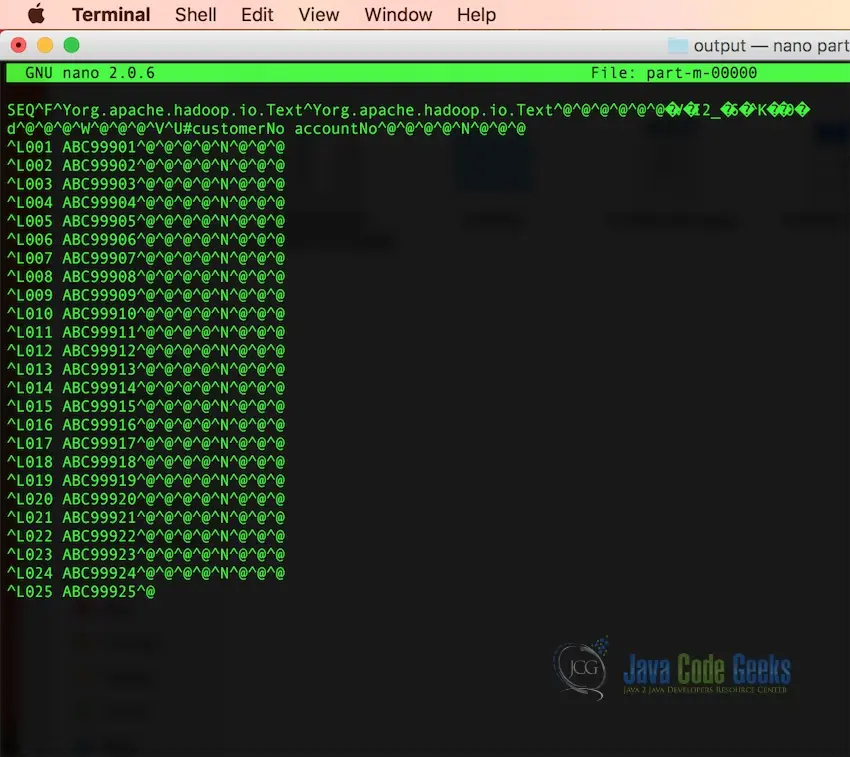
text 파일을 Sequence 파일로 변환하는 과정을 보여주는 예제이고
물론 그 반대로도 변환이 가능함
또한, 위의 예제에서는 Sequcne 파일을 압축하지 않았는데
압축을 하려면 다음과 같은 코드를 추가하여 Snappy 등을 사용하면 됨
|
1
2
3
|
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, SnappyCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(job,CompressionType.BLOCK);
|
cs |
< 궁금한 것 >
애초에 k-v 형태로 되어있는 데이터만 sequence file 형태로 바뀔 수 있는 것인지 궁금함
k-v 형태가 아니었다면 sequence file 이 될 수 없었을까?
sequence file 포맷을 사용하려면 무조건 원본 데이터 자체가 k-v 형태여야 하는 조건이 붙는 것인가?
아무도 그런걸 설명을 안 해줘 -_-
참고
https://examples.javacodegeeks.com/enterprise-java/apache-hadoop/hadoop-sequence-file-example/
https://www.edureka.co/community/775/what-is-the-use-of-sequence-file-in-hadoop
https://stackoverflow.com/a/34252006
'Hadoop' 카테고리의 다른 글
| [Hadoop] vm.swappiness 값은 어떻게 해야 할까 (0) | 2021.12.10 |
|---|---|
| [Hadoop] 로컬(Standalone), 의사분산(Pseudo Distributed), 완전분산(Fully Distributed) 모드 차이 (0) | 2021.11.24 |
| [YARN] NodeManager 재실행하면, 실행중이던 job들은 죽을까? (0) | 2021.07.20 |
| [Hadoop] pseudo-distributed mode 설치 방법 (0) | 2021.03.25 |
| [HDFS] du 옵션 출력 결과 설명 (0) | 2020.12.01 |