core.ewha.ac.kr/publicview/C0101020140401134252676046?vmode=f
반효경 [운영체제] 11. CPU Scheduling 2 / Process Synchronization 1
설명이 없습니다.
core.ewha.ac.kr
Synchronization 문제는
하나의 데이터에 여러 Process 가 쓰기 작업을 했을 때 발생하는 Race Condition,
여러 Process 가 서로의 데이터를 가져가려고 기다리는 Dead Lock 등을 말 함.
Race Condition이 어떤 상황에서 생길까. 동일한 데이터를 서로 다른 두 곳에서 읽고 쓰게되는 상황에서 발생.
- multi processor 가 있는 상황에서, memory 의 값을 1번 core 가 읽어가고
그 때 2번 core 역시 읽어 갈 때
- Process 들 간 공유 memory 를 사용할 때(공유 메모리 주소 공간) 1번 Process 가 데이터 읽어가고
그 때 2번 Process 가 데이터를 읽어갈 때
- Kernel 수행 중 인터럽트 발생할 때. A 데이터 대상으로 작업중인 와중에
A 데이터 대상인 인터럽트가 발생. 그럼 인터럽트 먼저 처리하고나서
아까 작업하던 것을 마무리 함. 결과적으로 인터럽트가 반영되지 않음.
바로 위의 경우, A 데이터 대상으로 하던 작업 중에 인터럽트가 와도
인터럽트 먼저 처리하지 않고 기존 작업을 먼저 끝냄. 그 후에야 인터럽트를 처리하도록 함.
이렇게 Race Condition 을 피할 수 있음.
또한 공유되는 데이터를 가져가면 다른 process 나 CPU 가 가져가지 못하도록
lock을 걸고, 공유된 데이터가 반납되면 lock 을 푸는 방식으로 Race Condition 을 피함.

좀 더 일반적으로 살펴보자.
Process Synchronization 문제는 공유 데이터 동시 접근때문에 발생.
이를 해결하고 일관성(consistency)를 유지하기 위해서는
협력 process 간 실행 순서를 정하는 메커니즘 사용.
즉, 공유 데이터를 사용하는 Process 간 동기화가 잘 되어야 한다.
< Critical-Section Problem >
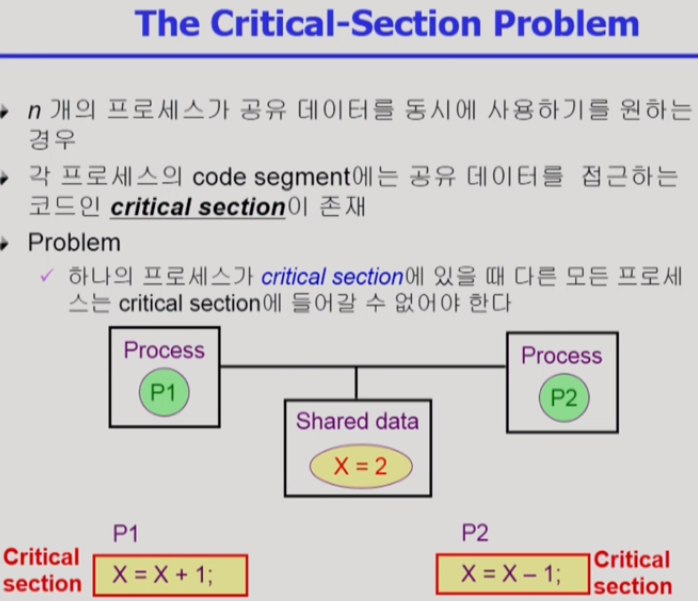
Critical-Section : 공유 데이터에 접근하는 코드
프로세스 하나가 Critical-Section 을 실행중일 때
다른 프로세스들이 Critical-Section 에 들어가지 못하게 하면
동기화 문제가 해결됨!
즉, Critical-Section 을 실행할 수 있는 프로세스는 단 하나
왜냐면 공유 데이터에 접근하는 코드(Critical-Section) 자체가 실행되지 않으니까.
다른 Critical-Section에 들어가지 못하게되면, 먼저 실행된 Critical-Section 이 끝날 때 까지 기다려야 함

위와 같은 코드를 사용.
entry section 에서 critical section 들어가기 전에 lock 을 걸고
critical section 에는 하나의 Process 만 들어가게 함.
exit section 에서 critical section 나오면서 lock 을 풀어줌
위와 같은 코드를 통해 소프트웨어적으로 동기화 문제를 해결하려면 다음과 같은 조건들이 필요함.

Mutual Exclusion : critical section 에는 단 하나의 process 만 접근 가능.
Progress : critical section 에 아무도 없고, 들어가고자 하는 Process 가 있으면 들여보내줘야 함.
Bounded Waiting : critical section 에 들어가기 위해 기다리는 시간이 너무 오래 걸리면 안 됨.
유한한 시간 내에 들여보내줘야 함.

위의 알고리즘이 바로 critical section 에 단 하나의 Process 만 들여보내는 알고리즘.
바로 피터슨의 알고리즘(Peterson's Algorithm) 이라고 함.
동기화 문제를 타파하는 방법임.
Pi 와 Pj 가 있고, 현재 Pi 가 CPU 를 잡고 있음.
코드에서 가장 먼저 나의 flag[i] 에 true 를 할당(critical section 에 들어가고 싶다는 표현)
그리고 turn 이라는 공유 변수에 상대방의 이름을 넣음.
while 문에서 flag 가 나의 것이고, turn 이 상대 이름이면 계속 while 돌면서 기다림.
flag 가 나의 것이 아니거나, turn 이 내 이름이거나, 혹은 둘 다 라면
그제서야 critical section 에 들어간다고 함.
나올때는 flag 를 내려서 나 critical section 에서 볼 일 다 봤다고 표현함.
피터슨의 알고리즘을 사용하면, 코드 중간 어디에서 context switching 이 일어나도
critical section 에는 단 하나의 Process 만 들어가도록 제대로 동작한다고 함.
근데 이 코드의 문제점은, critical section 을 위해 기다리는 Process 들이
모두 While 문에서 busy waiting 을 하며 기다린다는 점임.
이것을 spin lock 이라고 하나 봄.

Semaphore : 공유 자원을 얻고 반납하는 작업을 처리해 줌.
하나 이상의 프로세스가 critical section 에 접근 가능하도록 하는 장치
lock 을 걸고 해제하는 것을 도와주는 추상적 자료형이라고 생각하자.
정수값을 갖는 변수라고 생각하면 쉽다.
초기에 자원의 개수를 의미하는 정수값을 갖고 있음.
P 라고 되어있는 것이 공유 자원을 얻는 연산
V 라고 되어있는 것이 공유 자원을 돌려주는 연산
예를 들어 자원이 다섯개라고 하자. (5)
세마포어를 통해 자원을 얻게 되면 정수값이 하나 떨어짐 (4)
자원을 하나 더 얻게 되면 정수값이 하나 더 떨어짐 (3)
...이러다가 0이 된 이후에는 자원을 얻을 수 없음. (0)
자원을 다 쓰고 돌려주면 정수값이 하나 올라감 (1)
이런 방식으로 공유 자원을 관리함.

공유 데이터를 얻고 싶은 Process 들이
while 문을 돌면서 기다리는 busy waiting (spin lock) 을 하는 것 보다
Process 를 block 상태로 만들어버리는 block & wake up (sleep lock) 을 하는 것이 더 효율적임
이 때 사용하는 것이 Mutex(Mutual Exclusion object)
Mutex 가 제공하는 lock() 을 통해 lock 을 얻으면 critical section 에 들어갈 수 있음
다른 프로세스가 lock 얻는 것에 실패하면, lock 얻는 것을 실패한 프로세스를 큐에 넣고 잠듦(잠들 때 context switching 발생)
lock 을 얻었던 프로세스가 critical section 이 끝나고 unlock() 을 통해 lock 을 해제할 때
큐에 잠들어있는 프로세스가 있다면 깨우고 그 프로세스에게 lock 을 넘김
lock 을 넘겨받은 프로세스는 critical section 에 들어갈 수 있게 됨
만약 멀티 코어 환경이고, critical section 길이가 짧다면,
busy waiting 보다 오히려 Mutex(block & wake up) 의 오버헤드가 더 클 수 있음
반대로 길이가 길다면 busy waiting 은 심각한 낭비가 될 것.
일반적으로는 Mutex 방식이 더 좋다고 함.
세마포어와 Mutex 의 차이
Mutex 는 lock 을 가진 프로세스만 lock 을 해제할 수 있음
세마포어는 lock 을 가지지 않은 다른 프로세스도 해제 가능
Mutex 는 하나의 프로세스만 lock 을 얻도록 함
세마포어는 (이진 세마포어가 아닌 이상) 여러 프로세스에게 lock 을 줄 수 있음
Mutual Execlusion 기능만 필요하면 Mutex,
여러 프로세스 간 작업 실행 순서 동기화가 필요하다면 세마포어 사용
아래서는 데드락을 설명하고 있음

하나의 프로세스에서 두 개의 리소스(s,q) 를 모두 사용해서 일을 해야 하는데,
P0 에서 s 를 얻은 상태에서 interrupt 가 걸려서 p1 에게 cpu 가 넘어감
P1 에서 q 를 얻음.
p1 은 s 를 얻고 싶지만 p0 가 갖고 있기 때문에(세마포어 때문에) 기다림
p0가 다시 cpu 를 얻은 후 q 를 얻으려고 봤더니 p1 이 q 를 갖고 있기 때문에 역시 기다림
이렇게 두 process 모두 기다리면서 일을 처리하지 못하게 됨.
이를 해결하기 위해서는 resource( 여기서의 s, q ) 를 얻는 순서를 정해주면 해결된다고 함.
즉, 무조건 s 를 얻은 다음 q 를 얻어야 하는 식.
starvation : 어떤 프로세스가 자원을 얻기 위해 무한정 기다리는 것.
스케줄링이 잘못되면 이런 경우가 생기지 않을까? 맞다.
확실하게 말하지만,
sychronization 문제는, 공유 데이터를 쓸 때 생김
공유 데이터를 읽을 때는 괜찮음.
하지만 읽기와 쓰기가 동시에 진행되면 안 됨
예를 들어 쓰기가 먼저 진행중인데도 불구하고 읽기가 처리된다면?
혹은 읽고있는 중인데도 불구하고 쓰기가 처리된다면?
읽는 도중에 값이 바뀔 것임
그래서 읽는 와중에는 쓰기를 금지(lock)시키고,
쓰는 와중에는 읽기를 금지(lock)시켜야 함
데드락을 방지하는 방법
1 - 공유 데이터(resource) 를 얻는 순서를 정한다.
예를 들어 a,b,c resource 들을 모두 얻어야 실행이 가능하다면,
반드시 a - b - c 순서로 resource 를 얻게 만듦.
2 - critical section 은 atomic 하게 만든다.
여러 공유 데이터(resource) 를 얻는 와중에 interrupt 가 걸리면 데드락이 생길 수 있기 때문에,
중간에 interrupt 가 걸리지 않는 것이 보장되도록 만듦.
'Linux' 카테고리의 다른 글
| [Linux] 리눅스 서버 60초안에 상황 파악하기 공부 필기 (3) | 2021.02.14 |
|---|---|
| [Alpine Linux] Openjdk 설치하는 방법 링크 (0) | 2021.01.04 |
| [운영체제] 이화여대 반효경 교수님 수업 필기 CPU Scheduling 1,2 (0) | 2020.10.21 |
| [Linux] memory cache 삭제하는 방법 (2) | 2020.10.15 |
| [운영체제] 이화여대 반효경 교수님 수업 필기 Process Management 1,2 (0) | 2020.10.08 |