core.ewha.ac.kr/publicview/C0101020140321144554159683?vmode=f
반효경 [운영체제] 8. Process Management 1
설명이 없습니다.
core.ewha.ac.kr
프로세스는 부모 프로세스로부터 복제되어 생성된다.
즉, 최초의 프로세스 하나가 실행되고 그 프로세스를 복제하여 여러 자식 프로세스들을 만든다.
자식 프로세스들은 또 자신들을 복제하여 생성한 자식 프로세스를 만들 수 있다(즉, 부모가 될 수 있다).
프로세스는 트리 구조를 형성한다.
프로세스는 실행을 위해 자원(CPU와 memory)을 필요로 한다.
부모 프로세스가 자식 프로세스를 만들었지만, 이 둘은 서로 자원을 얻기 위해 경쟁한다.
자원을 받는 방법은 크게 두 가지가 있음.
여태 공부해 온 것처럼 os 가 할당해주는 방법이 있고,
특이하게 부모와 자원을 공유해서 얻는 방법이 있다.
부모 프로세스가 갖는 것은 memory 주소 공간(code, data, stack), os 의 데이터(pcb, 자원 등), context(pc) 등.
자식 프로세스를 생성(fork)할 때, 부모가 갖고 있는 위의 것들을 모두 복사함(pid는 제외).
그 후에 자식 프로세스 위에 새로운 프로그램을 덮어 씌워서(exec) 새로운 작업을 하도록 함.
여기서 부모 프로세스를 복사하는 system call 이 fork() 이고
자식이 자신의 프로세스 위에 새로운 프로그램을 덮어 씌우는 것이 exec() 이다.
fork() :
ㄴ새로운 프로세스 생성
ㄴ부모(pid 제외한 OS data 와 메모리 주소 공간)를 그대로 복사
ㄴ주소 공간 할당
exec() :
ㄴ새로운 프로그램을 메모리에 올림
아니 그러면 부모의 모든 것을 복사하면 자식이 따로 떨어질 일이 없지 않나?
더군다나 똑같은 게 두 개가 생겨버려서 메모리 공간이 낭비되는 것이 아닌가?
자식은 분명 처음 생성 될 땐 부모와 데이터가 똑같지만, 코드의 다른 부분을 실행하므로써
생성되거나 쌓이는 데이터도 달라지게 되고, 쌓이는 stack 역시 달라지게 된다.
그렇게 함으로써 자식은 부모와 별개의 것이 된다.
자식의 새로운 코드(부모에게는 없는)가 언제 추가되느냐? 바로 exec() 시스템 콜이 호출되고 난 후.
exec() 을 호출하면 새로운 프로그램이 메모리에 올라간다(자식이 실행시키는 system call)
자식이 부모와 데이터나 stack 상으로 독립?하는 과정에서 부모와 다른 값을 갖게 되는데, 이 때
Copy-on-write(COW) 가 일어난다.
자식이 처음 생성 될 때는 부모와 똑같은 데이터, 똑같은 메모리 공간을 갖고 있기 때문에
자식을 위해 따로 공간을 마련해주면 자원 낭비가 맞다.
따라서 자식이 처음 생성 될 때는 자식을 위한 메모리 공간을 주지 않다가
(자식에게 code data stack 등 부모의 데이터를 copy 해주지 않고 부모의 것을 공유),
자식이 데이터, stack 상으로 부모와 다른 길을 걷게 되었을 때 비로소 메모리 공간을 따로 준다.
이것이 COW(copy-on-write) 이라고 함.
말을 해석해보면 'write' 했을 때 'copy' 한다 라고 하는데...
즉, 부모와 달라지게 되는 값이 write 되기 전까지는 부모와 메모리, 데이터, stack 등을 공유하다가
부모와 달라지게 되는(내용이 수정되면) 값이 write 되고 나면
그제서야 부모의 code data stack 등을 copy 하여 자식에게 준다(이 때 os 의 fork() 가 호출됨)는 의미라고 함.
아래 예제를 보면, (위의 설명과는 다르게) 부모와 달라져서 folk 를 하는 게 아니라
folk 를 하기 때문에 부모와 달라짐
즉, folk 를 하면 부모와 다른 코드 flow 를 타게 되고, 이 때 부모의 메모리 공간과 pcb 등을 복사해서 자식에게 줌(COW)
프로세스 세계에서는 자식이 부모보다 항상 먼저 죽음
자식이 내부적으로 직접 죽으면 exit() 이라는 system call 을 호출.
만약 자식이 죽지 않은 상태에서 부모가 자식을 죽여야 하는 상황이라면 abort() 라는 system call 호출.
exit() :
ㄴ자식이 직접 자기 자신을 죽임(대개 program 의 마지막에 호출. main 함수가 return 될 때 자동으로 exit 가 붙음)
ㄴ자식이 죽으면 부모에게 output data 를 보냄(via wait) //이건 무슨 말인지 모르겠음
ㄴ프로세스의 각종 자원들이 os 에게 반납이 됨
abort() :
ㄴ부모 프로세스가 자식의 수행을 종료시킴
ㄴ자식이 할당받은 자원을 낭비하거나 한계치를 넘어서도록 사용하면 abort 하여 종료시킴
ㄴ자식에게 할당된 task 가 더 이상 필요하지 않으면 abort 하여 종료
ㄴ자식이 살아있는데 부모가 종료(exit)되는 경우 자식들(모든 후손들)이 줄줄이 abort 되어 종료됨
os 는 부모가 죽으면 모든 후손들의 수행을 막아버림. 따라서 단계적인 abort가 이루어지며 종료.
< fork() 시스템 콜 >
fork() 를 통해 자식 프로세스를 만드는 함수가 어떻게 동작하는지 살펴보자.
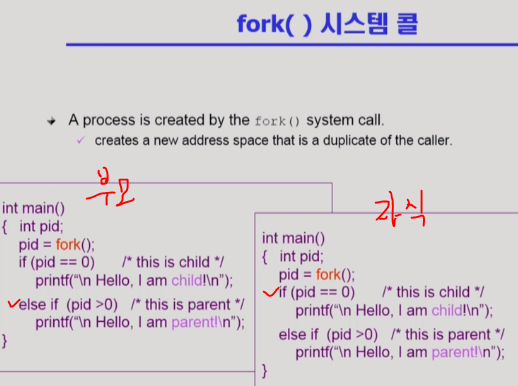
int main() 은 부모의 프로그램임.
프로그램이 돌다가 세번째 줄(pc=3) fork() 를 실행함.
fork() 를 실행하면 os 가 자식 process 를 하나 생성.
부모는 세번째 줄(pc=3) 의 fork() 의 반환값으로 양수를 받음. 그래서 else if 문을 타게 됨.
자식도 세번째 줄(pc=3) 부터 실행됨. 왜냐하면 부모의 pc 까지 복사받았기 때문.
자식은 세번째 줄(pc=3) 의 fork() 의 반환값으로 0을 받음. 그래서 if 문을 타게 됨.
이런 절차를 통해 부모와 자식의 실행문이 달라지고 다른 일을 하게 됨.
< exec() 시스템 콜 >
부모와 아예 다른 동작을 하게 되는 자식의 탄생 과정을 코드로 살펴보자.

fork() (세번째 줄) 를 통해 자식이 생성된 뒤, 자식 프로세스는 pid 0을 받고 if 문을 타게 된다.
이때까지는 부모의 데이터, 코드 등을 복사받았기 때문에 부모와 똑같은 일을 하지만,
if 문 내부에서 execlp(exec()을 호출하는 함수)를 실행함으로써
자식이 갖고 있는 코드는 모두 새로운 코드로 덮어씌워지게 된다.
이렇게 함으로써 자식은 새로운 코드와 함께 부모와는 다른 일을 하는 독립적인 프로세스가 된다.
물론 자식에서 exec() 을 실행한 것처럼,
부모 역시 자기자신의 코드를 뒤엎고 새로 덮어쓰기 위해 exec() 을 실행할 수 있다.
단, exec() 이후에 있는 코드들은 덮어씌워지므로 모두 사라지고 동작하지 않는다.
예를 들어

다음과 같은 코드에서 맨 아래 Hello, I am parent! 는 절대 실행되지 않는다.
왜냐하면 바로 위에 exec() 이 실행되기 때문에.
exec() 이 실행되어 새로 덮어쓴 코드가 끝나면 해당 프로세스는 죽는다.
(물론 그 내부에서 다시 exec() 을 실행하면 연명하겠지....)
< wait() 시스템 콜 >
wait() 은 해당 프로세스를 잠들게(block) 함.
예를 들어 A Process 가 io 를 요청하면 io 응답을 받을 때 까지 wait() 를 통해 A process 를 block 상태로 만든다.
(io 응답이 오면 ready 상태로 바뀜)
좀 더 구체적으로 wait 가 어떻게 동작하는지 알아보자.
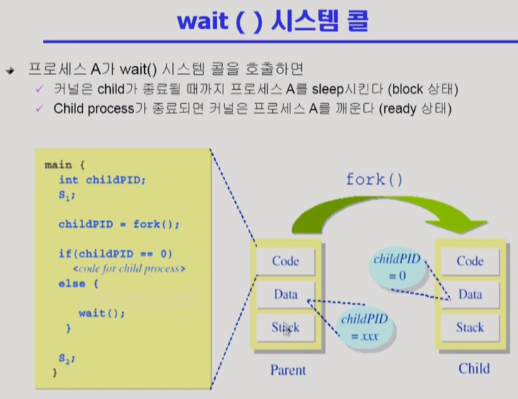
wait 는 다르게 말하면, '자식이 죽을 때 까지 부모가 기다리게 만드는' 함수이다.
위의 이미지를 보면, fork 를 통해 Parent 로부터 Child 가 만들어졌다.
코드를 살펴보면 if(childPID == 0) 즉, 자식일 때 "code for child process" 를 실행하도록 되어있고.
else 즉, 부모일 때 wait() 을 실행하도록 되어있다.
부모 process 는 wait() 을 통해 block 상태가 된다.
자식 process 가 "code for child process" 를 쭉쭉 실행하다가, 다 실행하고 자식이 죽으면
그제서야 부모 process 가 block 상태로부터 깨어나게 된다.
리눅스의 명령 프롬프트를 예로 들어 위의 과정을 설명할 수 있다.
명령 프롬프트는 부모 프로세스이다.
사용자가 명령을 내리면(ls -al 혹은 cat README.md 등)
사용자 명령을 수행하기 위한 자식 프로세스를 생성하고 부모프로세스(명령 프롬프트)는 잠든다.
자식 프로세스는 사용자 명령을 수행하고, 수행이 끝나 죽고 나면
부모 프로세스(명령 프롬프트)가 살아나게 되어 사용자가 다시 명령을 타이핑 할 수 있도록 한다.
궁금한 것은...
굳이 자식에게 일을 맡기고 부모는 기다리는 일을 해야 하는가?
만약 부모 process 에서 io 요청으로 인한 wait() 함수가 실행된다면,
이때도 자식 process 를 낳고 자식이 일을 다 할 때 까지 기다리게 되는건가?
그럼 그 때 자식 process 는 뭘 하고 있나? io device 에서 응답이 올 때 까지 기다려야하기 때문에
아무 일도 못 할텐데?
위의 절차는 단지 모델 중에 하나에 속한다.
아래 이미지를 보자.

위에서 설명한 "부모가 자식의 죽음을 기다리는" 모델은 위에 이미지에서 설명하는 수행 모델임.
io 요청에 의한 wait 는, 단지 다른 프로세스 실행 모델이지 않을까 추측해 봄......
io 요청하는 케이스에 대해서도 설명해주시면 좋을 것 같은데 ㅠㅠ 설명 안 해주심.
< exit() 시스템 콜 >

exit() 은 프로세스를 종료시킬 때 호출한다.
process 가 자발적으로 exit() 을 호출하여 죽을 수 있고,
process 외부의 힘에 의해 비자발적으로 exit() 이 호출되어 죽을 수 있다.
process 가 죽으면 해당 process 가 갖고 있던 메모리 자원 등이 반납(free)된다.
정리하자면,
fork() : 부모를 복사하여 자식 프로세스를 생성
exec() : 새로운 이미지(코드)를 프로세스(메모리)에 덮어 씌움
wait() : 부모는 자식이 죽을 때 까지 block 상태가 됨.
exit() : 프로세스를 죽이고, 프로세스가 갖고 있는 자원을 os 에 반납함.
< 프로세스 간 협력 : IPC >

원칙적으로 프로세스 간에는 서로 영향을 주고 받지 않음.
(물론 부모가 죽으면 자식이 죽는 케이스가 있어서 영향이 절대 없다라고는 말 할 수 없지만....)
프로세스는 자기 자신의 주소 공간만 볼 수 있고,
다른 프로세스에게 어떤 정보(메세지)를 '직접' 전달할 수 있는 방법은 없음.
하지만 IPC(Interprocess Communication) 을 통해 프로세스 간 소통이 가능함.
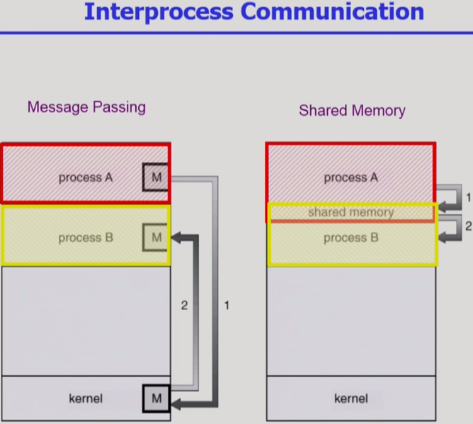
message passing : 프로세스 끼리 메세지를 주고받으면서 서로 영향을 끼치는 것.
프로세스끼리 메세지를 주고 받을 수 없으므로, 커널이 중간에서 메세지를 전달해 줌.
shaed memory : 일부 메모리 공간을 두 process 가 공유함.
원칙적으로 process 들은 자기 자신의 메모리 공간만 볼 수 있지만, shared memory 를 사용하여
두 process 가 똑같은 메모리 공간(즉, 똑같은 값/데이터/코드)을 볼 수 있고 공유할 수 있게 함.
먼저 message passing 부터 자세히 살펴보자.
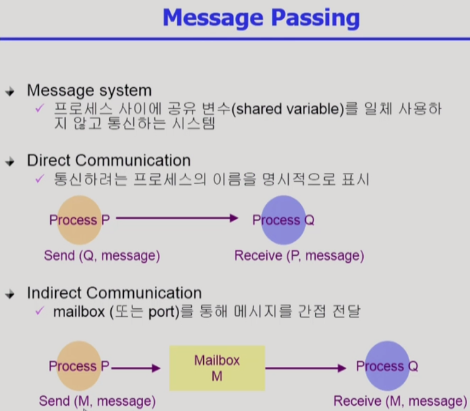
message passing 방법은 두 가지가 있음.
메세지를 받는 process 를 명시하느냐 명시하지 않느냐의 차이.
Direct Communication : process P 가 직접 process Q 를 지정해서 메세지를 보내는 방법
process P 는 커널에게 "Q 에게 이런 message 를 보내고 싶어. 전달해 줘" 라고 말하면
커널이 해당 메세지를 process Q 에게 전달해줌.
Indirect Communication : Process P 가 직접 process Q 에게 전달하는 것이 아니라,
그냥 M 이라는 박스에 넣음. 그러면 Process Q 가 해당 박스를 열어보고 메세지를 받음.
process P 는 커널에게 "M 박스에 이런 message 를 넣고 싶어. 전달해 줘" 라고 말하면
커널이 해당 메세지를 M 박스에 넣음
(지금 설명하는 부분은 불명확한 부분) Process Q 는 커널에게 "M 박스에 있는 메세지 좀 줘" 라고 말하면
커널이 해당 메세지를 M 박스로부터 Process Q 에게 전달함.
여기서 말하는 M 박스라는 것은 받는 process 가 지정되어있지 않음.
따라서 위의 케이스에서 process Q 가 받을 때 만약 또 다른 Process R 이 존재한다면,
R 역시 M 박스에서 메세지를 꺼내 볼 수 있음
그 다음으로 shaed memory 에 대해 자세히 알아보자.
process 들이 자발적으로 shared memory 공간을 만들 순 없다.
kernel 에게 process A와 B 가 공유 가능한 shared memory 공간을 만들어달라고 요청한다.
커널은 해당 공간을 만들어준다.
그 뒤로 process A, B 는 공유되어있는 공간을 사용하여 서로 영향을 주고 받는다.
두 process 가 서로 신뢰할 수 있는 관계에서 사용해야 함. 그렇지 않으면 치명적인 오류가 발생할 수도 ㅎㄷㄷ
참고로 thread 간의 협력은 커널의 도움 없이 자연스럽게 이루어진다.
왜냐하면 thread 들은 하나의 process 내의 메모리 공간을 다같이 공유하고 있기 때문에.
이후부터는 CPU Scheduling 에 대해 설명하심.
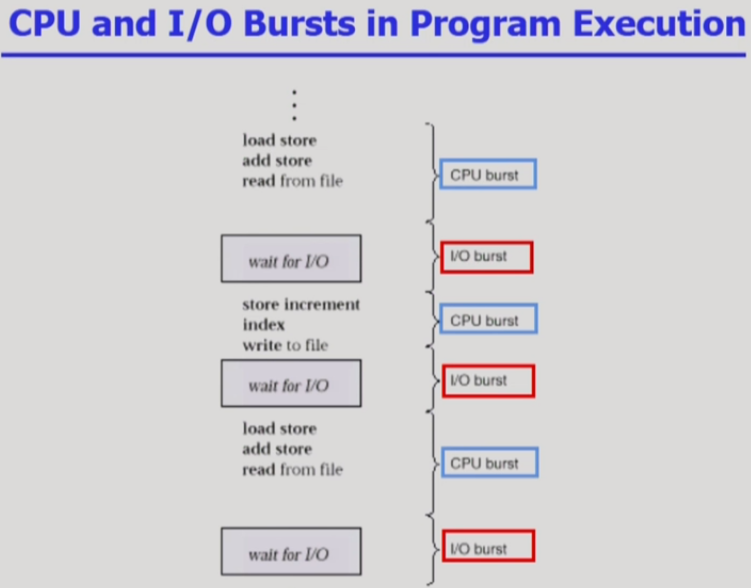
위의 이미지처럼, Process 를 실행하면
CPU 가 사용되는 부분이 있고, IO 가 사용되는 부분이 있음.
CPU 를 사용하는 단계를 CPU burst,
IO 를 사용하는 단계를 IO burst 라고 함.
process 가 실행된다는 것은, CPU burst 와 IO burst 를 반복하며 실행한다는 것.

위의 표에서 x 축은 CPU burst 실행 시간, y 축은 빈도
컴퓨터 내에서 돌아가는 process 들을 살펴봤더니,
CPU burst 가 짧고 IO burst 가 자주 끼어드는 process 들도 있고,
CPU burst 가 긴 process 도 있음.
CPU 를 짧게 쓰고 IO 를 주로 쓰는 작업을 IO bound job,
CPU 를 오랫동안 쓰는 작업을 CPU bound job 이라고 함.
"IO/CPU 를 주로 사용하는 process job 의 종류가 위와 같이 섞여 있다"
정도로만 이해하고 넘어가면 될 듯.
사람과 상호작용하는 job (interactive job) 이 IO bound job 인 경우가 많음
왜냐면 모니터에 출력도 해야하고 사용자로부터 입력도 받아야 하니까.
때문에 사용자 입장에서 오랫동안 기다리지 않게 하기 위해
CPU 를 IO bound job 에게 자주 주는 것이 좋다는 교수님의 말.
따라서 IO bound job 에 CPU 를 자주 주도록 CPU 스케줄링이 필요하다는 것이 결론.
CPU Scheduler : 어떤 process 에게 CPU 를 줄 지 선택하는 녀석
ready 상태인 process 중에 한 녀석을 골라 CPU 를 줄꺼야.
CPU scheduler 는 os 내부의 CPU 를 스케줄링하는 커널 코드를 말 하는 거임.
Dispatcher : CPU Scheduler 가 CPU 를 줄 process 를 선택하면,
해당 process 에게 CPU 제어권을 실제로 넘겨주는 녀석
Dispatccher 가 CPU 제어권을 넘기는 이 작업을 context switching 이라고 함.
Dispatcher 역시 CPU Scheduler 처럼 os 내부의 kernel code를 말 함.

위 이미지에는, CPU 스케줄링이 필요한 경우(CPU 를 잡는 프로세스가 바뀌는 경우)를 몇 가지 예시로 들어봄.
예 1. Process 가 IO 요청하는 경우.
process 가 IO 를 요청했기 때문에 CPU 를 사용하지 못하는 상황
예 2. Timer interrupt 가 걸린 경우.
CPU 신나게 쓰고 있다가 시간이 다 되어서 CPU 를 돌려줘야 하는 상황
예 3. 요청했던 IO 응답이 와서 CPU 를 사용해야 하는 상황
배우기로는 IO 응답이 와도 곧바로 CPU 를 사용하는게 아니라 ready 상태가
된다고 배웠는데, CPU 를 곧바로 사용하여 running 상태가 되는 경우도 있음.
바로, IO 응답받은 process 의 우선순위가 기존에 CPU 를 잡고 있던 process 보다 높을 때.
우선순위가 높은 process(IO 응답받은 녀석) 에게 CPU 를 양호하는 상황이 벌어짐.
즉, 우선순위가 높은 process 에게 CPU 를 빼앗기는 경우
예 4. process 가 일을 다 마치고 terminated 되는 경우
더 이상 CPU 를 사용하지 않지.
위의 1, 4번 경우는 "자신이 자발적으로 CPU 를 반납하는 상황", nonpreemptive 라고 하고,
2, 3 번 경우는 "CPU 를 반납하고 싶지 않지만 강제로 빼앗기는 상황", preemptive 라고 함.
위에 말한 용어 중요하다고 함.


'Linux' 카테고리의 다른 글
| [운영체제] 이화여대 반효경 교수님 수업 필기 CPU Scheduling 1,2 (0) | 2020.10.21 |
|---|---|
| [Linux] memory cache 삭제하는 방법 (2) | 2020.10.15 |
| sysbench 사용법 링크 (0) | 2020.10.06 |
| [운영체제] 이화여대 반효경 교수님 수업 필기 Process2,3 (0) | 2020.10.03 |
| [운영체제] 이화여대 반효경 교수님 수업 필기 Process1 (0) | 2020.10.02 |