Nifi 이용하다가 알게 된 유용한 정보들에 대해 적어둔다.
보일 때 마다 업데이트 함.
| the content of a flow file is not stored in memory, only the properties and attributes associated with the physical file in the content repository are held in the JVM heap memory. The only time the content is in memory is when a processor that deals with the content of a file is in the flow. community.cloudera.com/t5/Support-Questions/nifi-node-has-very-high-memory-usage-even-when-no-dataflow/td-p/202396 |
| Nifi 기본 사용법 https://nifi.apache.org/docs/nifi-docs/html/user-guide.html https://www.popit.kr/apache-nifi-overview-and-install/ www.freecodecamp.org/news/nifi-surf-on-your-dataflow-4f3343c50aa2/#d187 |
| Nifi 사용하는 방법을 보여줌 https://blog.autsoft.hu/beginners-guide-to-apache-nifi-flows/ www.youtube.com/channel/UCBHGHVGIihzmuOM86D8IfHQ/videos |
| Docker Apache NiFi 설치하고 실행하는 기본적인 방법 + Registry medium.com/analytics-vidhya/setting-apache-nifi-on-docker-containers-a00e862a8399 |
| resource 제한 및 팁 & 트릭 등 다양한 기초 정보 제공 꼭 읽어보자! marklogic.github.io/nifi/performance-considerations#__RefHeading__796_1654017897 |
| NiFi 의 기본 WebUI 접근 port 번호는 8080 바꾸고싶다면 nifi/conf/nifi.properties 에서 nifi.web.http.port=8080 의 값을 다른 값으로 수정 후 재시작 nifi.apache.org/docs/nifi-docs/html/walkthroughs.html#modification-of-configuration-values |
| nifi 의 로그를 보려면 tail -f logs/nifi-app.log 명령어를 실행 nifi.apache.org/docs/nifi-docs/html/walkthroughs.html#starting-nifi Docker NiFi 에서 log 를 보려면 docker logs -f [nifi container 이름] 명령어를 실행 |
| NiFi 앱을 실행하려면 bin/nifi.sh start NiFi 앱이 실행중인지 확인하려면 bin/nifi.sh status NiFi 앱을 중지하려면 bin/nifi.sh stop |
| NIFI Best practices for setting up a high performance NiFi installation docs.cloudera.com/HDPDocuments/HDF3/HDF-3.5.1/nifi-configuration-best-practices/content/configuration-best-practices.html https://community.cloudera.com/t5/Community-Articles/HDF-CFM-NIFI-Best-practices-for-setting-up-a-high/ta-p/244999 www.youtube.com/watch?v=rF7FV8cCYIc&ab_channel=DataWorksSummit https://benyaakobi.medium.com/optimizing-nifi-with-concurrent-tasks-b49c2e71f700 |
| IO, CPU, memory 최적화 https://community.cloudera.com/t5/Support-Questions/NiFi-Sizing-Benchmark-Conditions-and-Number-of-Source-that/m-p/168348 |
| Nifi 성능 측정 과정을 보여줌 blog.cloudera.com/benchmarking-nifi-performance-and-scalability/ |
| 성능 측정 관련 www.datainmotion.dev/2019/06/performance-testing-apache-nifi-part-1.htmlhttps://pierrevillard.com/tag/benchmark/ |
| 클러스터 로드 밸런싱 cluster load balancing 관련 blogs.apache.org/nifi/entry/load-balancing-across-the-cluster |
| nifi 블로그(한글) 혹시 문제가 생기면 여기 해결방법이 있나 살펴보자. soowan541.tistory.com/category/Nifi아래 블로그에는 나이파이 문서 번역 등이 있다. https://gist.github.com/cheerupdi |
| 사용 방법 동영상 몇 개 나와있지는 않지만 그래도 처음 시작하는 분들한테는 좋을 듯 www.youtube.com/playlist?list=PL55symSEWBbMBSnNW_Aboh2TpYkNIFMgb www.youtube.com/channel/UCwU9S7wfULVPwHCuJnQ3fmw/featured |
| Apache Nifi HTTP/HTTPS 연결 brunch.co.kr/@sokoban/96 |
| Nifi input port , output port 사용법 쉬운 예제를 들어 설명함 youtu.be/-EN42_YMrOU |
| apache nifi docker https://hub.docker.com/r/apache/nifi https://dzone.com/articles/setting-apache-nifi-on-docker-containers |
| apache nifi docker clustering on a single server www.nifi.rocks/apache-nifi-docker-compose-cluster/ |
| Apache NiFi Configuration Best Practices (2018) clustering 에 대해 설명도 잘 되어있다. https://docs.cloudera.com/HDPDocuments/HDF3/HDF-3.3.1/nifi-configuration-best-practices/hdf-nifi-configuration-best-practices.pdf |
| FlowFile 처리 우선순위 정하기 stackoverflow.com/questions/42528993/how-to-specify-priority-attributes-for-individual-flowfiles |
| FlowFile 이란? - 어떻게 memory/disk 에서 처리되는가? https://paulsmooth.tistory.com/204 https://stackoverflow.com/questions/43971968/nifi-how-to-store-flow-data-in-memory-or-disks |
| NiFi는 일반 텍스트 HTTP를 통한 인증 또는 권한 부여 기능을 허용하지 않음 즉, 따로 보안 설정을 하지 않으면 NiFi API 요청을 중간에 가로채어 수정할 수 있고, 데이터 손상 및 도용도 할 수 있고, NiFi 인스턴스를 방해할수 도 있다는 말. 보안 구성을 보려면 아래 링크 참고 nifi.apache.org/docs/nifi-docs/html/administration-guide.html#security_configuration |
| TLS 로 NiFi 보안 자세한 설명 nifi.apache.org/docs/nifi-docs/html/walkthroughs.html#securing-nifi-with-tls |
| Processor 간 FlowFile 을 주고 받는데, 이 때 FF 들은 disk 에 저장된다. nifi.properties 에 지정된 repository 경로 예를 들어 Content Repository : 실제 FlowFile 의 데이터가 저장되는 경로 FlowFile Repository : FlowFile 의 속성값, 상태 등이 저장되는 경로 세팅 방법 : nifi.properties 에서 지정 참고 : https://nifi.apache.org/docs/nifi-docs/html/overview.html#nifi-architecture |
| Apache Nifi 로 cluster 에서 putFile Processor 를 사용하면, 각 노드마다 처리한 파일을 각자의 path(바로 위에 참고) 에 저장함 예를 들어 1번 노드에서 처리한 파일은 1번 노드의 path 에 저장, 2번 노드에서 처리한 파일은 2번 노드의 path 에 저장… getFile Processor 역시 (Primary Processor 가 아니라는 전제 하에) 각 노드의 path 로부터 읽은 파일의 처리를 각 노드가 담당함. 예를 들어 1번 노드에서 읽은 파일 A 는 1번 노드의 Nifi 가 처리, 2번 노드에서 읽은 파일 B 는 2번 노드의 Nifi 가 처리.... 이 과정에서 n번 노드의 path에 데이터가 없다면 무시함. 만약 getFile 이 Primary Processor 라면, 자기 노드 path 에 있는 데이터만 읽어오고 다른 노드 path 에 있는 데이터는 읽지 않음. |
| Back Pressure Object Threshold : back pressure 가 적용되기 전까지 큐에 담을 수 있는 FlowFiles 개수. default is 10,000. Back Pressure Data Size Threshold : backpressure 가 적용되기 전까지 큐에 담을 수 있는 데이터 크기. default is 1gb 개수가 1개여도 1gb 를 넘을 수 있고, 크기가 1kb 여도 개수가 10000을 넘을 수 있어서 이렇게 두 가지 값을 지정하도록 만들었음. |
| JVM 에 config 값은 java.arg.N 을 통해 설정. java.arg.2,3 : JVM heap min/max size java.arg.13 : garbage collector java.arg.7,8,9 : code cache 세팅 방법 : bootstrap.conf 에서 지정 참고 : https://marklogic.github.io/nifi/performance-considerations#__RefHeading__776_1654017897 |
| Cluster 에서 데이터를 읽을 때, Primary Node에서만 데이터를 읽게 만드는데 이 때 단독으로 실행됨. 단독으로 데이터를 읽은 후 각 노드들에게 데이터를 넘기는 것이 일반적인 nifi 운용 방법. Primary Node 가 아니면 각 노드에서 모두 읽게 되고 Concurrent Issue 를 야기하게 됨. 세팅 방법 : 읽기 Processor 의 config 에서 execution 을 Primary 로 바꿔주면 됨. 참고 : https://gist.github.com/cheerupdi/bffb331447abc78934ad5a40feb83f16#terminology |
| Penalty Duration : 해당 Processor 가 당장 처리할 수 없는/처리가 불가능한 FlowFile 이 있지만 추후에 처리 할 수 있을 때 Flow File 이 처리 될 때 까지 기다려주는 시간. 예를 들어 한 FlowFile 을 remote Nifi Instance 에 보내야 하는데 그쪽에서 받지를 못한다면 해당 FlowFile 을 처리할 수 없는 상황이 됨. 이 상황에서 Processor 가 Penalty Duration 만큼 FlowFile 의 처리를 기다려줌. 그 기간동안 FlowFile 가 처리되지 않음 default 는 30초 Yield Duration : 어떤 Processor 가 (FlowFile 과 관계 없이) 더 이상 진행이 되지 않는다고 판단되면 Yield Duration 만큼 해당 Processor 가 실행되지 않음 default 는 1초 즉, Processor가 문제가 생겨 더 이상 진행이 불가능하게되면 1초 동안 Processor 가 멈춤. gist.github.com/cheerupdi/87eacaa87b74feee4de0bb5eba0216d2 nifi.apache.org/docs/nifi-docs/html/user-guide.html#settings-tab |
Maximum Timer Driven Threads
|

| FileSize : GenerateFile 에서 생성한 FF의 총 크기 Batch : GenerateFile 에서 생성한 후 Connector 로 내보내는 FF 의 수 Concurrent tasks : GenerateFile 에서 동시에 스케줄되는 task 의 수. 바로 아래 예제에서는 4 대의 노드에서 동시에 32개의 쓰레드를 실행하기 때문에, 결과적으로 32x4 = 128, 총 128개의 쓰레드가 GenerateFile Processor 를 위해 동작 세팅 방법 : 해당 Processor 의 config 에서 세팅 |

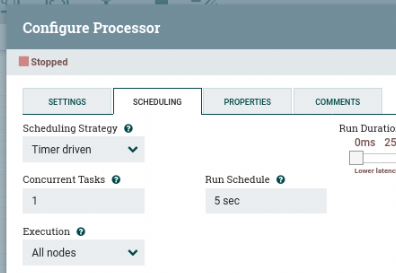

| 스케줄링 관련 항목은 아래 링크 참고 medium.com/@ben2460/nifi-scheduling-a522a1c9e740 |
프로세서는 NiFi가 다시 시작된 후 중단 된 위치에서 다시 시작할 수 있습니다. 또한 프로세서가 일부 정보를 저장하여 프로세서가 클러스터의 모든 다른 노드에서 해당 정보에 액세스 할 수 있도록합니다. 이를 통해 한 노드가 다른 노드가 중단 된 지점을 선택하거나 클러스터의 모든 노드에서 조정할 수 있습니다. nifi.apache.org/docs/nifi-docs/html/administration-guide.html#state_management |
| FlowFile 데이터는 NiFi가 처리하는 동안 디스크에 저장 FlowFile 정보는 메모리 (JVM)에 보관 nifi.apache.org/docs/nifi-docs/html/administration-guide.html |
| NiFi는 작동중인 host 시스템의 기능을 완전히 활용함. host 메모리나 disk, cpu 를 죄다 차지하여 사용할 수 있다는 뜻 nifi.apache.org/docs/nifi-docs/html/overview.html#performance-expectations-and-characteristics-of-nifi |
| Nifi 는 JVM 위에서 실행됨. 다음과 같이, JVM 위에 Web Server, Flow Controller, Repositories 가 있음(물론 repo 는 disk 에 있음). Flow Controller : 작업 thread 제공, 리소스 스케줄링 관리 FlowFile Repo : 현재 flow 에서 활성화 된 FlowFile 의 상태를 저장하는 곳(ff 의 메타데이터 인 듯) 디스크에 저장되며 영구 Write-Ahead Log 임. Content Repo : FlowFile 의 실제 데이터를 저장하는 곳. filesystem 에 데이터 블록을 저장하는 방식. 단일 스토리지 뿐 아니라, 여러 스토리지에 저장할 수 있음. Provenance Repo : 모든 출처 이벤트 데이터를 저장하는 곳. 이를테면 어떤 데이터가 A Processor 에서 나왔는지, B Processor 가 어떤 flow 를 타고 진행되었는지 등. 하나 이상의 스토리지에 저장 가능 이 repo 내의 데이터는 indexing 되어있어 검색이 가능함. nifi.apache.org/docs/nifi-docs/html/overview.html#nifi-architecture |

FlowFile Repository Write-Ahead-Log로 FlowFile의 상태와 속성값들을 저장하는 곳이다. 일반적으로 Raid 10으로 디스크를 구성하여 저장해, 시스템 장애 때 유실되지 않게 한다. Content Repository FlowFile의 실제 데이터(Content)가 저장되는 곳. 일반적으로 Raid 10으로 디스크를 구성해 저장하며, 여러 디렉토리에 분석 저장이 가능하다. 이 때문에 용량이 큰 데이터를 저장할 수 있으며, 단일 디스크의 처리량보다 많은 양을 처리할 수 있다. Nifi 시스템의 역할을 봤을 때, 일반적으로 여러 파티션을 사용할 경우가 많지는 않을 것이다. Provenance Repository 데이터의 처리 단계별로 FlowFile 변화(원천) 데이터(FlowFile 들의 history)를 보관하는 곳으로, 여러 디스크를 지원하며, 각 데이터는 인덱스 되어 검색할 수 있다. www.popit.kr/apache-nifi-overview-and-install/ 만약 Repository 를 변경하고 싶다면 아래 링크 참고 nifi.apache.org/docs/nifi-docs/html/administration-guide.html#content-repository |
NIFi UI 내에서 적용하는 모든 구성은 NiFi 클러스터의 모든 노드에 적용됨. 어떤 설정도 클러스터 자체에 총계로 적용되지 않음. community.cloudera.com/t5/Community-Articles/Understanding-NiFi-max-thread-pools-and-processor-concurrent/ta-p/248920 |
| Nifi Registry 사용 방법 Registry 는 Flow의 버전 관리를 위해 사용됨 git 을 사용하는 것처럼, 다른 곳에 버전이 저장되고 flow 가 변경되면 변경된 내용을 다른 이름으로 commit 가능 commit 된 내용을 다른 Nifi 가 가져올 수 도 있음. 아래 동영상을 보면 바로 이해가 될 것임. www.youtube.com/watch?v=X_qhRVChjZY&ab_channel=AndrewLim |
| Parameter 는 Nifi instance 에 전역에서 사용 가능한 값. #{} 기호를 사용하여 사용 가능하며, Processor 의 property 의 값을, parameter 를 사용하여 넣을 수 있음. 비밀번호 같은 민감한 property 에 넣을 수 있는 parameter 가 있고, 일반적인 텍스트 property 에 넣을 수 있는 parameter 가 있음. config 에서 설정해야 Processor 에서 사용 가능 설명 및 사용 방법 : nifi.apache.org/docs/nifi-docs/html/user-guide.html#parameter-contexts Variable 은 해당 Process Group 내에서 사용이 가능한 값. 프로세스 그룹에 Variable 이 지정되었다면 그 그룹 내에서 사용 가능 ${} 기호를 사용하여 사용 가능. 마치 FlowFile 의 attribute 를 사용하는 것 처럼. Variable 을 갖는 프로세스 그룹 내에 또 다른 프로세스 그룹이 있고 이름이 같은 Variable 이 있다면, 바깥쪽 프로세스 그룹의 Variable 이 안쪽 프로세스 그룹의 Variable 에 의해 덮어씌워짐. 마치 전역 변수가 지역 변수에 의해 덮어씌워지는 것처럼. Variable 을 사용할 수 있는 Processor property 가 있고, 사용할 수 없는 property 가 있음. 설명 및 사용 방법 : nifi.apache.org/docs/nifi-docs/html/user-guide.html#Variables 자세한 내용 : community.cloudera.com/t5/Community-Articles/Introduction-into-Process-Group-Variables/ta-p/247625 참고로 $ 기호를 사용하는 FlowFile 의 attritube 는 아래 링크에서 볼 수 있음 nifi.apache.org/docs/nifi-docs/html/developer-guide.html#flowfile |
| Controller Service 는, 미리 정보를 담아둔 property 세트 이다. 100개의 PutSQL Processor 를 만들고 a,b,c,d,e property 를 넣어야 하는 상황이라고 하자. 여기서 a,b,c,d 는 100개의 PutSQL 이 같은 값을 갖지만 e 는 서로 다른 값을 갖는다. 내가 일일이 PutSQL 하나하나의 property 를 수정하는 것은 cool하고 fun하지 sexy하지 않다. 대신 Controller Service 를 만든다. 내가 만드는 Controller Service 에는 a,b,c,d 값이 미리 들어가있다. 내가 할 일은 PutSQL 의 property 로 미리 만들어 둔 Controller Service 를 지정하기만 하면 된다. (그리고 서로 다른 e 값을 넣어주는 거지) Controller Service 를 사용하면 여러 프로세서가 데이터를 직접 로드 할 필요가 없음 데이터는 한 번만 로드함. 그리고 Controller Service 를 통해 모든 프로세서가 해당 데이터를 사용 가능. 사용할 Controller Service는 해당 서비스가 사용될 루트 프로세스 그룹 또는 하위 프로세스 그룹의 구성에서 정의되어야 함. 아래 이미지는 PutSQL 에 Controller Service 를 지정하는 모습 gist.github.com/cheerupdi/9e53f8a7a396bce0a947a9d2919570c2 |
| Round Robin 으로 Load Balancing 하는 도중 노드 하나가 멈춰버려서 처리가 불가하게 되면, 해당 노드 큐에 쌓여있던 데이터들이 다시 다른 활성 노드들로 재분배 된다. Round robin: FlowFiles will be distributed to nodes in the cluster in a round-robin fashion. If a node is disconnected from the cluster or if unable to communicate with a node, the data that is queued for that node will be automatically redistributed to another node(s) nifi.apache.org/docs/nifi-docs/html/user-guide.html#load_balance_strategy 근데 엄청 느리게 재분배된다고 함. 왜냐면 다시 연결될 것을 기대하고 있기 때문에. the data is rebalanced fairly slowly, though. Up to 1,000 FlowFiles, or 10 MB of data, will be rebalanced per second. This is done so that if the node reconnects to the cluster or is able to communicate again momentarily, that the data is not immediately redistributed to other nodes. But if that does not happen, the data is still redistributed throughout the cluster in a timely manner. 그렇다면 다른 load balancing 전략에서 노드 중 하나가 멈춰버리면 어떻게 될까? Round Robin 전략에서는 멈춘 노드의 데이터를 다시 분배하지만, Partition by Attribute 혹은 Single Node 전략에서는 멈춘 노드의 데이터를 재분배하지 않음. 그냥 그대로 멈춰버린 해당 노드에 둔다. 왜냐하면 Round Robin 은 데이터를 클러스터 전체에 분산하기 위한 전략이고 Partition by Attribute 혹은 Single Node 는 데이터를 특정 노드에 보내는 전략이기 때문. If the "Partition by Attribute" or "Single Node" strategy is used, then the data will just queue up, waiting to send, until the node is reconnected and able to communicate. This is because these strategies expect that a given piece of data go to a specific node, whereas "Round Robin" just expects that data gets spread across the cluster. blogs.apache.org/nifi/entry/load-balancing-across-the-cluster |
| Cluster 구성시 Zookeeper 의 도움으로 노드들 중 하나가 Primary, Coordinator 가 된다. 내가 원하는 노드를 Primary 로 만드는 방법은 없다. when running a cluster, one of the node is randomly designated as the “Primary node”. The election takes place when the cluster starts, and there is no way to decide which node will be the primary node. pierrevillard.com/2017/02/23/listfetch-pattern-and-remote-process-group-in-apache-nifi/ |
| Primary 동작이 없는 일반 Cluster 에서 getSFTP 를 실행하면, 모든 노드가 똑같은 데이터를 읽어온다. 각 노드마다 똑같은 데이터를 읽어서 노드 수 만큼의 데이터를 가져오게 된다. When you use GetSFTP in a cluster you are duplicating your data. Each node will ingest the same data. community.cloudera.com/t5/Support-Questions/GETSFTP-with-NiFi-cluster/m-p/220629#M182514 만약 Delete Original 옵션을 true 로 했다면, FPT 서버상의 데이터를 읽고 지우기까지 하므로 Access 오류가 발생할 수 있다. if the processor is configured to delete the file once retrieved (default behavior) you will have errors showing up. pierrevillard.com/2017/02/23/listfetch-pattern-and-remote-process-group-in-apache-nifi/ 따라서 getSFTP 를 사용해야 한다면, 똑같은 데이터를 읽어오지 않도록 Primary 로 동작하게 만들어야 한다. in a NiFi cluster it should be set to run on "primary node only" so that every node in the cluster is not competing to pull the same data. community.cloudera.com/t5/Community-Articles/How-to-Retrieve-files-from-a-SFTP-server-using-NiFi-GetSFTP/ta-p/245430 하지만 위와 같이 Primary 로 동작하게 만들면, 효율적이지 않다. 왜냐면 하나의 노드에서만 데이터를 가져오기 때문에, 그리고 데이터는 데이터를 가져온 해당 노드에서만 처리될 것이기 때문에. (물론 load balancing 이나 원격 포트를 이용하여 데이터를 각 노드로 퍼뜨릴 수 있을 것임) it’s not efficient at all. First reason is that you get data from only one node (this does not scale at all), and, in the end, only the primary node of your cluster is actually handling the data. Why? Because, unless you explicitly use a remote process group, the data will remain on the same node from the beginning to the end. pierrevillard.com/2017/02/23/listfetch-pattern-and-remote-process-group-in-apache-nifi/ 위와 같은 연유로 getSFTP 대신 ListSFTP/fetchSFTP 를 사용하는 것이 좋다. ListSFTP 를 통해 FTP 서버에서 파일들의 메타데이터를 가져옴. 이 때는 listSFTP는 Primary 로 동작함 listSFTP 는 Processor 자체적으로 Primary 에서만 돌아가게 설계되어있음. All Nodes 동작은 선택조차 되지 않음. 만약 Primary 노드가 새로 선출되어도, 이전에 가져온 메타데이터는 가져오지 않음. 즉, listSFTP 는 중복없이 FTP 서버 데이터의 메타데이터를 가져오는 역할을 함. this Processor can be run on Primary Node only and if a new Primary Node is selected, the new node will not duplicate the data that was listed by the previous Primary Node. nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.5.0/org.apache.nifi.processors.standard.ListSFTP/ 그 후 FetchSFTP 를 통해 각 메타데이터에 맞는 실제 데이터를 FTP 서버로부터 가져옴. 위의 설명은 ListSFTP/fetchSFTP 패턴의 동작 과정을 굉장히 간략하게 설명한 부분임. 자세한 내용은 아래 링크 참고. pierrevillard.com/2017/02/23/listfetch-pattern-and-remote-process-group-in-apache-nifi/ 아래 링크에서 ListSFTP/fetchSFTP 사용 방법을 알려줌 soowan541.tistory.com/9 |
| 바로 위에서 신나게 RPG 를 이용하여 클러스터의 각 노드로 데이터를 분배하고 fetchSFTP 를 사용하는 예제를 봤는데, 각 노드로 데이터를 분배하기 위해서 RPG 를 사용하지 말라고 함. RPG 는 다른 클러스터에 배포하는데만 사용해야 한다고 함. 이유는 아직 모르겠지만, 알게되면 업데이트 하겠음. Remote Process Groups are no longer necessary for load balancing! Use actual load balanced connections instead! Remote Process Groups should only be used for distributing to other clusters. dev.to/tspannhw/apache-nifi-load-balancing-via-load-balanced-connections-593m |
| NiFi 는 들어오는 데이터를 zero-master 클러스터링 방법을 사용하여 나눈다. 데이터는 청크 단위로 나뉘어지며, 클러스터 내의 각 노드들은 각자 나눠받은 청크를 대상으로 똑같은 작업을 실행한다. help.hcltechsw.com/commerce/9.1.0/search/refs/rsdelasticperformance.html#rsdelasticperformance__section_shh_jnt_rlb |
| 로그 레벨을 바꾸려면, conf/logback.xml 을 편집한다. 만약 INFO 에서 DEBUG 로 바꾸고 싶다면 <logger name="org.apache.nifi.web.api.config" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> 위의 level 을 DEBUG 로 바꿔준다. <logger name="org.apache.nifi.web.api.config" level="DEBUG" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> nifi.apache.org/docs/nifi-docs/html/administration-guide.html#troubleshooting |
| nifi 노드가 처리하는 데이터는 local disk 의 contents repo 위치에 저장되고 nifi 가 처리하는데, 만약 nifi 가 disconnect 가 되어버리면 local disk 에 있는 그 데이터는 고립이 되어버린다. 이를 해결하려면 nifi 를 connect 시키던가 아니면 offload 시켜야 한다고 한다. by NiFI 를 사용하시는 다른 개발자 |
| nifi 노드를 offload 하면, 해당 nifi 가 갖고 있던 데이터는 다른 nifi 로 보내어진다. 그래서 다른 nifi 노드들이 해당 데이터를 처리한다. 즉, nifi 노드를 offload 하면 해당 노드의 contents repo 는 텅텅 비게 된다. |
offload 절차 [참고]
|
| disk 의 파티션을 총 3개로 나눈 후, 각각의 파티션에 각 repo 들(flowfile, provenance, content)을 저장하는 것이 권장된다고 한다. nifi doc 에 있다고 하는데... 찾으면 업데이트 하겠음. |
'NiFi' 카테고리의 다른 글
| [Nifi] Clustering 의 필요성 (0) | 2020.09.16 |
|---|---|
| [Nifi] Docker 로 Zookeeper + Nifi Cluster 구축하는 방법 연구 (1) | 2020.09.08 |
| [Nifi] sample templates 링크 (0) | 2020.09.07 |
| [Nifi] external zookeeper 로 Nifi Cluster 설치하는 방법 (0) | 2020.08.31 |
| [Apache Nifi] 간단한 설명 링크 (0) | 2020.08.25 |