아래서 설명하고 있는 kafka 는 standalone 모드로 돌아감을 밝힙니다.
이 포스트의 주제는 "spark 와 kafka 의 연동" 이기 때문에
kafka 는 standalone 모드로 간단하게 구동시켰습니다.
또한 이 포스트에 이론적인 내용은 없습니다.
일단 내가 테스트한 환경 이러하다.
ubuntu 가 돌아가는 세 대의 각기 다른 서버를 사용하여 spark cluster를 구축하였고
spark 의 master node 가 동작하는 서버위에 zookeeper 와 kafka 를 standalone 모드로 실행시켰다.
즉 아래와 같은 상황임.
| 서버 이름 | server1 (11.11.11.8) | server2 (11.11.11.9) | server3 (11.11.11.10) |
| 동작하는 것들 |
spark master zookeeper (standalone) kafka (standalone) |
spark worker1 | spark worker2 |
spark 는 yarn 을 이용하여 자원을 조율한다.
자 spark 를 kafka 와 연동하기 위해 아래 절차를 따른다.
spark 를 이용하여 kafka에서 읽고 쓰기 위한 코드는 여기를 적극 참고한다. 자세히 나와있다.
1. zookeeper를 설치한다.
zookeeper를 standalone 모드로 설치하기 위해, 나의 zoo.cfg 는 아래처럼 작성하였다.
|
< zoo.cfg >
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/root/apache-zookeeper-3.5.6-bin/zoo_data clientPort=2181
|
보면 server.1=xxx... 부분이 없다.
이 부분이 없으면 standalone 모드로 돌아가게 된다.
2. kafka를 설치한다.
kafka 역시 standalone 모드로 설치하기 위해, server.properties 를 아래처럼 작성하였다.
|
< server.properties >
broker.id=1 ...(중략)... log.dirs=/root/kafka_2.11-2.4.1/data ...(중략)... zookeeper.connect=localhost:2181/localhost
|
정말 localhost 에서 하나만 돌아가도록 만든 것임! ㅎㅎ;;
zookeeper 와 kafka 를 실행시키고 아래 명령어를 통해 port 가 잘 열려있는지, 잘 실행 중인지 확인한다.
Zookeeper 실행 bin/zkServer.sh start Kafka 실행 bin/kafka-server-start.sh ../config/server.properties |
|
주키퍼 포트확인
|

3. kafka의 topic 을 만들어둔다.
아래 명령어를 토대로 tp1 이라는 이름의 topic 을 만든다.
|
./kafka/bin/kafka-topics.sh --zookeeper localhost:2181/localhost --replication-factor 1 --partitions 1 --topic tp1 --create
|
4. 터미널 두 개를 열어두고, 하나는 kafka에 메세지를 전달하는 용도로, 하나는 spark driver를 실행하는 용도로 사용한다.
spark 는 shell 이던 submit 던 상관 없으며, batch 나 streaming 방식으로 kafka 와 연동 가능하다.
첫번째 터미널에서는 아래 명령어를 이용하여 kafka tp1 토픽에 메세지(log)를 입력한다.
|
./kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic tp1
> (여기 입력 후 enter) ....
|
두번째 터미널에서는 (일단) spark-shell 을 열어서 kafka tp1 토픽의 메세지를 batch로 읽어본다.
아래 명령어처럼 --packages 옵션에 spark kafka lib를 넣어줘야 한다.
|
spark-shell --master yarn --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.1
|
shell 이 실행되면 아래 코드를 넣는다.
이 때 kafka 를 구별하기 위해 넣는 kafka.bootstrap.servers 에는 kafka 가 실행되는 서버의 호스트 이름을 적는다. 나의 경우 11.11.11.8
subscribe 에는 읽고싶은 topic name을 넣는다.
|
< batch 코드 >
val kd = spark.read.format("kafka").option("kafka.bootstrap.servers", "11.11.11.8:9092").option("subscribe", "tp1").option("startingOffsets","earliest").load() kd.show
|
아래는 kafka tp1 토픽에서 log 를 읽어서 show 한 모습
batch 로 읽었기 때문에 spark action(kd.show())이 실행될 때 kafka 가 갖고 있는 log 들이 한 번에 읽힌다.

binary 로 읽힌다(...)
streaming 으로 읽고 싶다면 아래 코드를 사용한다.
|
< streaming 코드 >
import org.apache.spark.sql.streaming.Trigger val kd = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "11.11.11.8:9092").option("subscribe", "tp1").option("startingOffsets", "earliest").load() val stream = kd.writeStream.trigger(Trigger.ProcessingTime("5 seconds")).outputMode("append").format("console").start().awaitTermination()
|
streaming 코드가 실행된 모습이다. append mode 이기 때문에 이전 값들 말고 새로 입력된 값들만 console 에 출력된다.

여기서 trigger 는 옵션이므로 넣던 안 넣던 개발자 자유임.
5. binary 로 된 log 내용을 string 값으로 파싱한다.
batch 의 경우 아래와 같이 udf 를 이용하여 binary 를 String 값으로 파싱 가능하다.
|
import org.apache.spark.sql.functions.udf val kd = spark.read.format("kafka").option("kafka.bootstrap.servers", "11.11.11.8:9092").option("subscribe", "tp1").option("startingOffsets","earliest").load() val toStr = udf((payload: Array[Byte]) => new String(payload)) val parsing = kd.withColumn("value", toStr(kd("value"))) parsing.show()
|
여기서 "value" 은 파싱된 값이 들어갈 새 column 의 이름.
kd("value") 는 binary 값이 들어있는 dataframe의 column 이름 (kd 객체의 "value" 필드)
결과적으로 기존의 value 값을 새로운 value 가 덮어쓰는 형태가 된다.
아래는 실행된 모습. value filed 를 보면 binary 로 표현되던 값들이 string 값으로 표현되고 있다.

streaming 코드에서도 위와 마찬가지로 udf 를 적용하면 binary 를 파싱하여 읽을 수 있다.
6. 새로운 topic 에 값을 새로 써본다.
아래 코드를 사용하면 된다.
|
parsing.selectExpr("key","value").write.format("kafka").option("kafka.bootstrap.servers", "11.11.11.8:9092").option("topic","newtopic").save()
|
selectExpr 에서 선택한 것은 key 와 value 라는 이름의 column 이 반드시 들어가 있어야한다.
아니면 org.apache.spark.sql.AnalysisException: Required attribute 'value' not found; 같은 error 가 뜨더라.
위의 코드를 실행시킨 후, kafka 에서 직접 consumer 를 실행시켜 newtopic 의 내용을 읽어볼 수 있다.
consumer 를 실행시키기 위해서 아래 코드 참고
|
./kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic newtopic --from-beginning
|
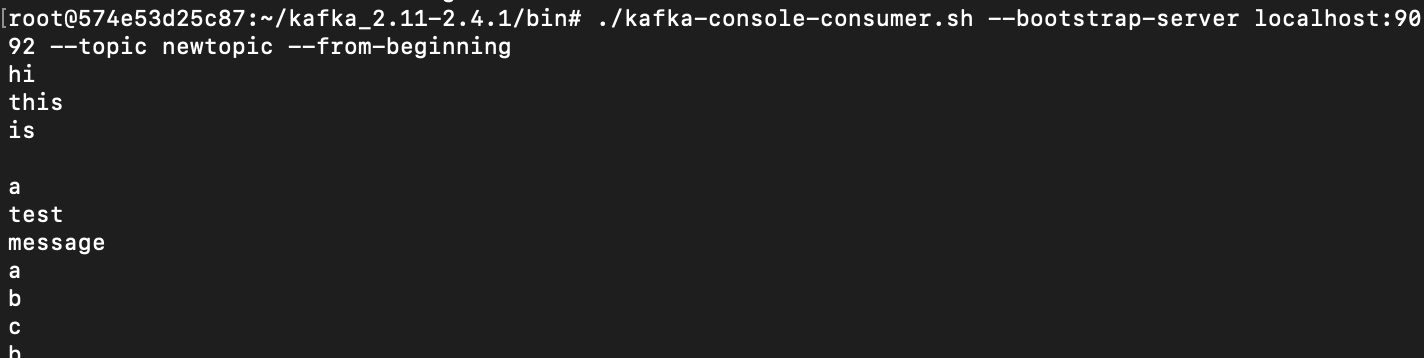
실제로 읽어본 모습은 아래와 같다.
코드 실행한 후

consumer 에서 방금 저장한 message 를 읽어본 모습
만약 streaming 으로 실시간 값을 kafka 에 쓰고 싶다면 아래 절차를 따른다.
먼저 hdfs 에 checkpointLocation 으로 사용할 path 를 만든다.
|
hdfs dfs -mkdir -p /streaming/checkpointLocation
|
위의 streaming 코드에서 writeStream 부분의 format을 console 에서 kafka 로 바꾸고
여러 옵션들과 key, value 들을 select 하여 write 한다.
|
import org.apache.spark.sql.streaming.Trigger val kd = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "11.11.11.8:9092").option("subscribe", "tp1").option("startingOffsets", "earliest").load() //여기까지 읽는 코드 import org.apache.spark.sql.functions.udf val toStr = udf((payload: Array[Byte]) => new String(payload)) val parsing = kd.withColumn("value", toStr(kd("value"))) parsing.withColumn("key",lit("null")).selectExpr("key","value").writeStream.trigger(Trigger.ProcessingTime("5 seconds")).format("kafka").option("kafka.bootstrap.servers","11.11.11.8:9092").option("checkpointLocation","/streaming/checkpointLocation").option("topic","newtopic").start().awaitTermination()
|
withColumn 을 이용하여, 내용은 null 이고 "key" 라는 이름의 column 을 새로 만들어주었다.
이게 없으면 "key" column 이 계속 없다고 뜨기 때문(에러 내용 : org.apache.spark.sql.AnalysisException: cannot resolve '`key`' given input columns: [value];;)
위의 writeStream 코드를 실행시킨 결과. 실시간으로 받은 데이터를 kafka 에 다시 쓰고 있기 때문에 console 에 아무것도 찍히지 않는다.

위의 streaming 이 실행되고 있는 도중에 아래처럼 kafka topic(tp1) 에 a, b, c 를 입력하였다.

streaming 이 a, b, c 를 받고 kafka newtopic 에 값을 그대로 쓰는 것을 아래처럼 확인하였다.

7. 만약 spark-submit 으로 코드를 실행시키고 싶다면, sbt dependencies에 아래를 추가한다.
|
< build.sbt >
.... libraryDependencies += "org.apache.spark" %% "spark-sql-kafka-0-10" % "2.4.1" ....
|
spark-streaming-kafka lib 위치 : https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10
sample code : https://mapr.com/docs/61/Spark/StructuredStreamingWordCountApplication.html
IO 코드 공식 문서 : https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
간단한 IO 코드 참고 (batch, streaming) : https://docs.microsoft.com/ko-kr/azure/hdinsight/hdinsight-apache-kafka-spark-structured-streaming
kafka + spark streaming : https://alphahackerhan.tistory.com/14
11번가 kafka 컨슈머 애플리케이션 배포 전략 : https://medium.com/11st-pe-techblog/%EC%B9%B4%ED%94%84%EC%B9%B4-%EC%BB%A8%EC%8A%88%EB%A8%B8-%EC%95%A0%ED%94%8C%EB%A6%AC%EC%BC%80%EC%9D%B4%EC%85%98-%EB%B0%B0%ED%8F%AC-%EC%A0%84%EB%9E%B5-4cb2c7550a72
'Spark' 카테고리의 다른 글
| [Spark] 아파치 스파크 기본 설명 링크 (0) | 2020.07.15 |
|---|---|
| [Spark] Dataframe 만드는 여러가지 방법 링크 (0) | 2020.03.26 |
| [Spark Steaming] kafka 를 이용하여 Data pipeline 만들어보기 (1) | 2020.03.23 |
| [Spark Streaming] HDFS 를 이용하여 Data pipeline 만들어보기 (0) | 2020.03.20 |
| [Spark] 기술 질문 대비 적어두는 것들 (0) | 2020.03.07 |