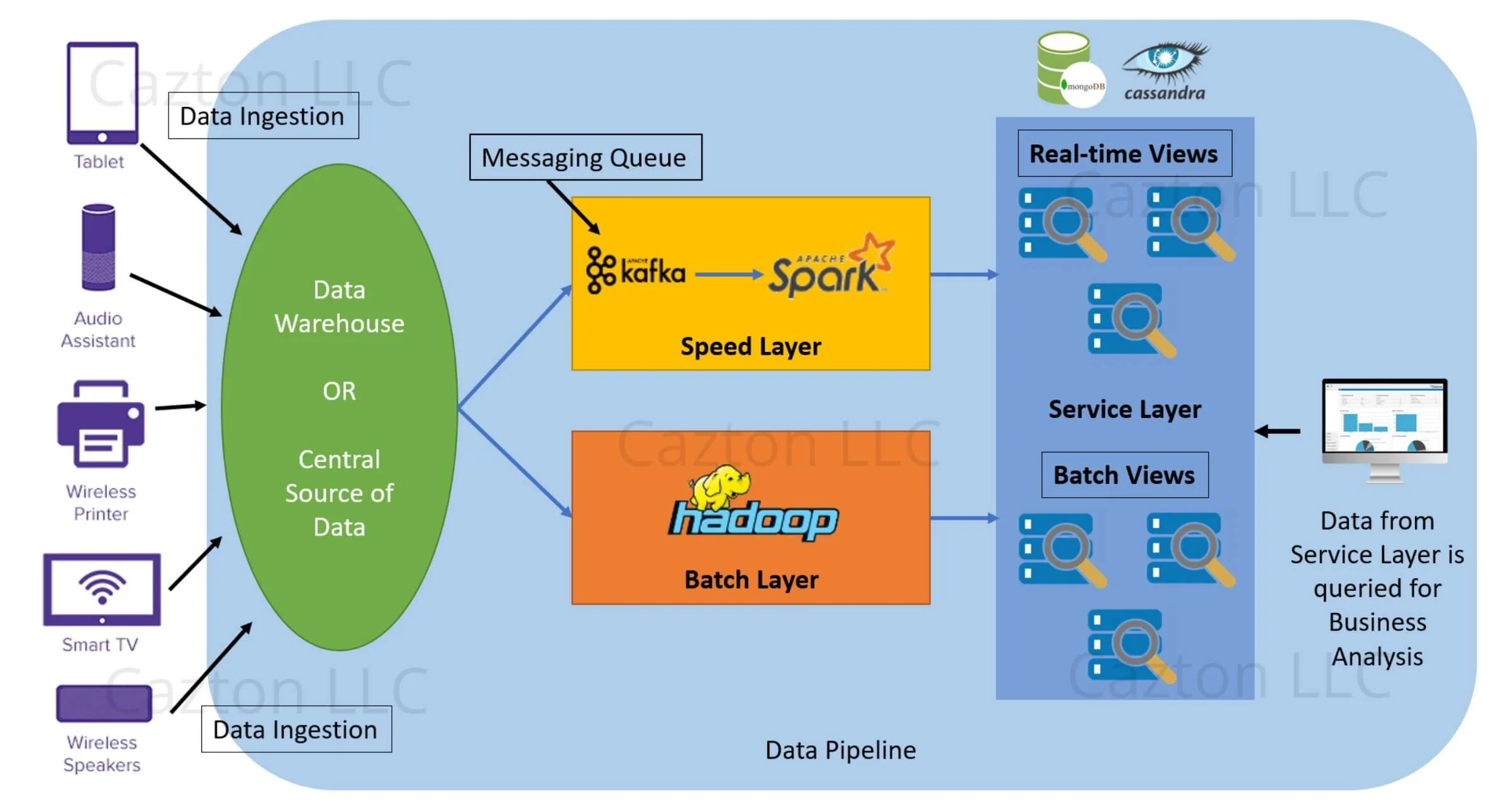
개발 영어 공부1 : https://eyeballs.tistory.com/683
| Spark was compiled for 2.13 | 스파크는 2.13 용으로 컴파일되었다. |
| It determines when to remove and request executors. | 결정하다. |
| If the jobs at the head of the queue don't need to use the whole cluster, later jobs can start to run right away | 대기열의 맨 앞에 있는 jobs 후속 jobs |
| then later jobs may be delayed significantly significant computing resources may be required. |
상당히 지연될 수 있다. 상당한 컴퓨팅 자원이 요구될 수 있다. |
| This feature is disabled by default. | 기본적으로 비활성화되어있다. |
| Newly submitted jobs go into a default pool. | 새롭게 제출된 작업들은 default pool에 들어간다. |
| Jobs run in FIFO order Jobs run in order. Automate A, B, and C in order of importance. data is stored in chronological order |
FIFO 순서로 작업이 실행된다. 순서대로 작업이 실행된다. 중요한 순서대로 자동화하라 시간순으로 저장되어있다 |
| both of these together make up the node Distributed storage refers to a storage architecture made up of multiple computers and disks. |
노드를 만든다. 다양한 컴퓨터와 디스크로 구성된 저장 아키텍처 |
| The same is true of the C node. | C노드도 마찬가지다. |
| Our managers deal with all kinds of clients every day | 매일 다양한 clients 를 상대한다. |
| In my previous project I carried out the responsibilities of... | 나의 이전 프로젝트에서, 이러이러한 책임을 수행했다. |
| Project managers usually estimate new projects by analogy | 유사사례를 통해 신규 프로젝트를 추정한다. |
| I improved my time management and organizational skills. | 시간 관리 및 시간 정리 능력을 향상시켰다. |
| the server performs instructions written in code. | 명령을 수행한다. |
| use only the numbers in given array. Cardinality refers to the number of unique values in a given dataset. |
주어진 배열 내 숫자만 사용하라 카디널리티(Cardinality)는 특정 데이터 집합에서 고유한 값(unique values)의 개수를 의미한다. |
| I assigned the number 33 to age variable. | 나이 변수에 33을 할당했다. |
| I created an array of strings. | 문자열 배열을 생성했다. |
| Debugging is to investigate the program and fix bugs. | 프로그램을 조사하는 것이다. |
| A program crashes when you divide by zero. | 프로그램이 중단된다. |
| I declared a function and implemented it. It works well! | 함수 하나를 선언했고 구현했다. 잘 동작한다. |
| I instantiated another object of the Student class. | 또 다른 학생 클래스 객체를 인스턴스화했다. |
| I iterated(loop) throught every element in the list. | 리스트 내 모든 요소를 순회했다. |
| Processing is manipulation of data by a computer | 컴퓨터에 의한 데이터 조작이다. |
| Raw data can be converted into JSON format. | Josn 형태로 변환될 수 있다. |
| Maintainability : It should be stable when the changes are made | 변경사항이 적용되었을 때 안정적이어야 한다. |
| You need a dedicated work space | 전용 작업 공간 |
| Let's move our meeting back an hour. | 한 시간 미루자 |
| She moved the meeting up a day. | 미팅을 하루 앞당겼다. |
| The meeting was rescheduled for Thursday. | 회의가 목요일로 재조정되었다. |
| From a subjective perspective. | 주관적인 관점에서 |
| We will meet in a week and synchronize on the progress. | 진행 상황을 맞춰보자. |
| Big data enables you to gather data from many sources. | 데이터를 수집할 수 있게 한다. |
| A kafka topic is identified by its name Each broker is identified with its ID. |
카프카 토픽은 이름으로 식별된다. |
| The sequence of messages is called a data stream Sequential messages received messages in sequence. processing data sequentially is necessary |
메세지의 순서를 데이터 스트림이라고 부른다. 연속된 메세지들 순서대로 수신한 메세지들 연속으로 데이터를 처리하는 것이 필요하다. |
| Topics are split in partitions. | 토픽은 파티션으로 나뉘어진다. |
| Each message gets an incremental id, called offset. 'Append' adds only the newly arrived data incrementally |
하나씩 증가하는 id 'Append' 는 새로 추가된 데이터를 증분으로 추가한다. |
| Kafka topics are immutable | 토픽들은 불변한다. |
| Data is kept only for a limited time. Data is maintained only for a limited time. Data remained only for a limited time. |
데이터는 제한된 기간 동안만 보관된다. 데이터는 제한된 기간 동안만 유지된다. 데이터는 제한된 기간 동안만 남아 있는다. |
| Over time, the kafka clients have been changed. | 시간이 지남에 따라... |
| The processing of rapidly increasing data is entrusted to Hadoop. I delegated the task to Hadoop |
빠르게 증가하는 데이터 처리를 하둡에게 맡긴다. 하둡에게 그 일을 위임했다. |
| There are two main methods for data transmission. | |
| The "streaming type" continuously transmits data as it is generated, in real time. | 실시간으로 생성되는 데이터를 끊임없이 보내는 방법이다. |
| Data collected over the past 30 minutes is aggregated If you want to graph the event trend over the past hour.. |
지난 30분동안 모은 데이터들이 집계되었다. 과거 1시간의 이벤트 수 추이를 그래프로 만들고 싶으면.. |
| To analyze data from the past 3 years | 지난 3년간의 데이터를 분석하기 위해 |
| Amazon S3 is a representative example of object storage. | 대표적인 객체 스토리지다. |
| it can increase data capacity in the future. | 향후 데이터 용량을 증가시킬 수 있다. |
| Most people are accustomed to using SQL | SQL 사용에 익숙하다. |
| This series of procedures is called the ETL process | 일련의 절차를 ETL 프로세스라고 부른다. |
| Batch processing is executed according to a fixed daily schedule | 고정된 일일 일정에 따라 실행된다. |
| If an error occurs, the administrator is notified. | 관리자에게 알려진다. |
| System failures can occur during big data processing. Therefore, it is necessary to implement functions to handle and retry tasks when errors occur. |
처리하는 기능을 구현하는 것이 필수다. |
| Data collected throughout the day is aggregated overnight to generate reports. | 하룻동안 수집된 데이터들은 밤사이 집계된다. |
| Unprocessed raw data is stored in a data lake, and only the necessary data is retrieved and used later. | 미가공한 원시 데이터가 data lake 에 저장된다. 그리고 필요한 데이터만 추출된다. |
| Data engineers are responsible for building, managing, and automating the systems. | 데이터 엔지니어는 책임을 진다. |
| It’s best to start with a small system and gradually scale it up over time. | 나중에 단계적으로 확장해가는 것이 좋다. |
| In the early stages, manually collecting and analyzing data without automation is called ad hoc analysis. | 시작 단계에서.. |
| Searching for data that meets specific criteria | 특정 기준을 충족하는 데이터 검색하기 |
| values in the 'time' column can be tricky to handle | time 컬럼값은 다루기가 까다롭다 |
| The same aggregation is repeated on a regular schedule—weekly or monthly—to observe trends over time. | 1개월 혹은 1주일마다 정기적인 일정으로 동일한 집계를 반복하고 그 추이를 관찰한다 |
| the number of ad impressions. | 광고 노출 수 |
| The number of customers who used the service in a day. The number of customers who used the service within a day. |
하루에 서비스를 이용한 고객 수 (하루 전체. 통으로) 하루 이내에 서비스를 이용한 고객수 (24시간 이내에) |
| Making decisions based on objective data is called data-driven decision making. | 객관적인 데이터를 근거하여 판단하는 것을 '데이터 기반 의사 결정'이라고 한다. |
| the values in A column are generally higher/lower/similar to the values in B column. | 전체적으로 |
| As long as you have organized numerical data | 정리된 숫자 데이터가 있다면 |
| names are listed in rows, and sales are listed in columns. | 행 방향으로 나열되고, 열 방향으로 나열된다. |
| the numeric data appears at the intersections of rows and columns | 행과 열의 교차점 |
| large datasets that can't fully fit in memory Load all the data into memory. |
메모리에 다 들어가지 못하는 큰 용량의 데이터 모든 데이터를 메모리에 올린다. |
| If the wait time for aggregation increases, all processes slow down. | 대기시간이 늘어나면, 모든 작업들이 느려진다. |
| your system needs to be designed for it from the start. | 처음부터 그렇게 디자인되어야 했다. |
| fast data processing is described as having low latency. | '지연시간(latency)이 적다'고 표현된다. |
| a sharp drop/improvement in performance | 급격한 성능 저하/향상 |
| The amount of data that can be processed within a certain period of time is called "throughput". | 일정 시간 내에 처리할 수 있는 데이터의 양을 처리량(throughput)이라 한다. |
| The time you wait for data processing to complete is called "latency". | 작업이 끝날 때 까지 대기하는 시간을 지연시간(latency)이라 한다. |
| The presence or absence of indexes Which option to choose depends on the situation. |
인덱스 유무 어떤 옵션을 선택할지는 상황에 따라 달라진다. |
| a query is broken down into many smaller tasks | 다수의 작은 태스크로 분해된다. |
| you need to scale both CPU and disk resources in a balanced way. | 균형있게 자원을 늘려야한다. |
| exploring the data through repeated trial and error. | 반복적인 시행착오를 통해 |
| In contrast to ad hoc analysis, you can run queries on a regular schedule to generate reports. | ad hoc 분석과 대조적으로.. |
| you want to take your time and carefully examine the data. | 시간을 갖고 차분히 데이터를 보고 싶다. |
| Metric B is updated once a day. | B 메트릭은 하루에 한 번 업데이트 된다. |
| improvements in computing power | 컴퓨팅 성능 향상 |
| There are more/fewer cases now where building a data mart is unnecessary. | 이러한 경우가 늘어나고/줄어들고 있다. |
| Normalization involves splitting tables as much as possible and linking them using foreign keys. | |
| Denormalization involves combining tables as much as possible. | |
| tables are categorized into fact tables and dimension tables. | |
| Fact tables store data that accumulates over time. | 시간에 따라 증가하는 데이터가 저장된다. |
| Dimension tables typically store attributes used to categorize the data. | |
| A model where a fact table is surrounded by multiple dimension tables is called a star schema. | |
| Files are replicated across multiple machines to increase redundancy. | 중복성을 높이기 위해 파일을 복사한다. |
| jobs are preferably executed on nodes close to the data. | 가급적, 데이터와 가까운 노드에서 실행한다. |
| spontaneously simultaneously |
자발적으로 동시에 |
| resource contention(competition) occurs between jobs | 자원 쟁탈(경쟁) |
| they run only when no one else is using the resources. | 누구도 자원을 사용하지 않을 때만 |
| Spark keeps intermediate data in memory It is safer to process data in an intermediate table first |
중간 데이터를 메모리에 보존한다. 중간 테이블을 만들어 처리하는 게 안전하다. |
| problems arise when aggregating large amounts of data over a long period. | 장기간에 거쳐 |
| data is evenly distributed across all nodes | 균형있게 분산되어있다. |
| storage and compute nodes are tightly coupled | 밀접하게 결합되어있다. |
| it either waits for resources to free up or fails with an error. | 메모리가 생길 때까지 기다리거나 |
| memory usage doesn’t increase proportionally | 비례하여 늘어나지 않는다. |
| memory consumption remains nearly constant | 메모리 사용량은 거의 일정하게 유지된다 |
| You can aggregate data with millions of records in under one second | 수백만 레코드를 갖는 데이터를 1초 미만으로 집계할 수 있다. |
| Even if a partial failure occurs, processing can continue as a whole | 부분적으로 장애가 발생해도, 전체적으로 처리를 계속할 수 있다. |
| Tez is a replacement for MapReduce and inherits its fault tolerance. Tez is an alternative to MapReduce. |
Tez 는 MapReduce 를 대체하는 것이며, 그 내결함성을 계승하고 있다. |
| Presto is the complete opposite of Hive | presto 는 hive 와 완전히 반대입니다 |
| Presto is specialized for executing interactive queries. | Presto 는 대화식 쿼리의 실행에 특화되어 있다. |
| excessive usage can prevent other queries from running. Excessively reducing cardinality can lead to significant information loss |
무리한 사용 카디널리티를 무리하게 낮추면 원래 있던 정보가 크게 손실된다 |
| it handles schema changes more flexibly. | 스키마 변동에도 유연하게 대처할 수 있다. |
| frequent read/write operations on small amounts of data | 빈번하게 소량의 데이터를 읽고 쓰는 것 |
| It increases the rate of unexpected errors. the likelihood of unexpected errors increases. |
예상치 못한 오류 발생률을 높인다. |
| It's a design issue rather than a performance problem. Massive data should be divided and processed in parts rather than all at once |
성능 문제라기보다는 설계 문제이다. 한 번에 처리하기보다는 부분으로 나눠서 처리해야한다. |
| What is the optimal file size for efficient processing? | 효율적으로 처리할 수 있는 파일이 크기는 얼마나 될까? |
| These two differ entirely in both technical characteristics and tools used, so you must understand their nature and use them accordingly. | 이 둘은 기술적인 특성도, 사용되는 도구도 전혀 다르므로 그 성질을 이해한 다음에 구분해서 사용해야 한다. |
| When handling large volumes of data, break tasks into monthly or daily units to prevent any single task from becoming too large. | 한 달 혹은 하루 단위로 전송하도록 태스크를 분해하여, 너무 커지지 않도록 막는다. |
| Fluentd only sends messages in one direction | 일방적으로 발송하는 것밖에 하지 못한다 |
| mobile apps often go offline the device is back online. |
모바일 앱은 오프라인이 되는 경우가 종종 있다. 다시 온라인 상태가 된다. |
| It can focus solely on its own tasks while leaving the rest to the shared system. | 작업에만 오롯이 전념할 수 있고, 나머지 작업은 공통 시스템에 맡길 수 있다. |
| the two are in a trade-off relationship | 둘은 트레이드오프 관계에 있다. |
| you just reached a performance limit | 성능 한계에 도달했다. |
| regulate the data write rate. | 데이터 쓰기 속도를 조절하라 |
| you need to decide in advance how to operate the system in its absence. | 그것이 없을 때 어떻게 시스템을 운용할지 미리 결정해야한다. |
| Only keep the IDs received within the last hour, and allow duplicates that arrived later. Allow duplicates for late-arriving messages. |
최근 1 시간 동안 받은 ID 만 기억해두고, 그보다 늦게 온 메세지의 중복은 허용한다. |
| The time a message is generated on the client is called “event time,” (on the client side) | |
| the time the server processes the message is called “process time.” | |
| the data is arranged in a contiguous layout. | 데이터가 연속적으로 배치되어있다. |
| Eventual consistency guarantees that all replicas will eventually converge to the same value over time. | 시간이 지나면 결국 동일한 값으로 귀결된다. |
| Strong consistency guarantees that all read operations reflect the most recent write. | 가장 최근의 쓰기를 반영한다. |
| a human intervenes to resolve the issue. | 사람이 개입하여 문제를 해결한다. |
| Some tasks can cause new problems if they are not completed by the scheduled time | 예정된 시간까지 끝내지 않으면 새로운 문제를 일으키는 태스크도 있다. |
| Let's finish it within the allotted time. | 정해진(할당된) 시간 내에 끝내자. |
| There are tools that notify you when a task exceeds its expected execution time. | 작업이 예상 실행 시간을 초과할 때 알려주는 도구가 있다. |
| It is important to anticipate potential unexpected errors in advance | 예기치 못한 오류 발생 가능성을 예상하는 것은 중요하다. |
| Setting the retry interval of a task to 10 minutes | 작업의 재시도 간격을 10분으로 설정 |
| “Backfill” refers to rerunning tasks over a specific period by changing the date parameter in sequence. | ‘백필’이란 파라미터에 포함된 날짜를 순서대로 바꿔가면서 일정 기간의 태스크를 다시 실행함을 의미한다. |
| You can test backfill gradually | 테스트 삼아 조금씩 백필을 실행할 수 있다. |
| In Airflow, scripts must be written with atomicity and idempotency | Airflow 에서는 원자성과 멱등성을 갖춘 스크립트를 작성해야 한다. |
| it helps improve stability. | 안정성을 높인다. |
| An execution with this property is called an idempotent operation. |
이런 특성을 지닌 실행을 idempotent operation 이라고 한다. |
| 'replacement' yields the same result even when repeated | '치환'은 반복해서 실행해도 동일한 결과를 산출한다. |
| Increase the number of retries while gradually expanding the interval between them | 재시도 횟수를 늘림과 동시에, 조금씩 재시도 간격을 넓혀나가라 |
| automatic retries must be disabled, and recovery should be done manually in case of failure. |
자동 재시도는 반드시 무효로 하고, 오류 발생 시 수작업으로 복구한다. |
| Adjust each task so that it has an appropriate size. | 각 태스크가 적절한 크기가 될 수 있도록 조정한다. |
| nodes are connected by arrows, and these connections never form cycles. |
노드와 노드가 화살표로 연결되며 각 노드 연결이 순환되지 않는다. |
| We can reprocess data starting from 7 days ago. | 7일 전 데이터부터 재처리할 수 있다. |
| A fast-response database is placed in the serving layer | 서빙 레이어에 응답이 빠른 데이터베이스를 설치한다 |
| Since the results of stream processing are used only temporarily, slight inaccuracies are acceptable. | 스트림 처리의 결과는 일시적으로만 사용되며, 정확하지 않아도 큰 문제가 없다. |
| Handling messages with a large gap between processing time and event time is referred to as the out-of-order data problem. | 프로세스 시간과 이벤트 시간의 차이가 큰 메세지를 처리하는 것을 ‘out of order’ 데이터 문제라고 불린다. |
| they must be sorted by event time before aggregation | 이벤트 시간 순서로 정렬하고 집계한다. |
| Therefore, the system must retain the state of past events and re-aggregate the corresponding window whenever new data arrives. |
때문에 과거 이벤트의 상태를 보존하면서, 데이터가 도달할 때마다 해당 윈도우를 재집계한다. |
| Since data cannot be stored indefinitely, data that arrives too late beyond a certain time threshold is ignored. |
데이터를 무한히 계속 보관할 순 없으므로 일정 시간 이상 늦게 온 데이터는 무시한다. |
| In ad hoc data analysis, interpreters are preferred. | ad hoc 데이터 분석에서는 인터프리터를 선호한다. |
| Each tweet is formatted as JSON data with a variable length. |
각 트윗은 길이가 일정하지 않은 json 데이터로 되어 있다. |
| Virtual machines allow the entire team to share a consistent setup | 팀 전원이 같은 환경을 공유할 수 있게 해준다. |
| extracting data for a specified period The error occurred under the specified conditions. |
명시된 기간 만큼의 데이터 추출하기 명시된 조건에서 발생했다. |
| overwriting a designated partition | 지정된 파티션 덮어쓰기 |
| As long as the parameters remain the same | 파라미터만 같다면 |
| The functions executed at this time are serialized and lazily evaluated | 이 때 실행되는 함수는 직렬화되어 지연 평가된다. |
| If the schedule is set to @daily, the task for January 1st is executed at the moment January 2nd begins. there is a one-day gap |
스케줄이 @daily 라면, 1월 1일의 태스크가 실행되는 것은 다음 날 1월 2일이 되는 순간이다. 1일의 차이가 있다. |
| if more tasks are queued, they are put on hold until slots become available. | 그 이상의 태스크가 등록되면 빈 자리가 생길 때까지 실행이 보류된다. |
| Adjust task durations so that each one doesn’t take too long | 각 태스크의 실행 시간이 길어지지 않도록 조절하라 |
| It hasn't been that long. | 그렇게 오래되진 않았어. |
| keep the system in a relaxed state. |
항상 여유 있는 상태를 유지하라 |
| By automating what was previously a manual reprocessing task | 이전에 수동으로 처리해야 했던 작업을 자동화함으로써 |
| a single re-run handles all necessary steps | 필요한 모든 과정을 처리했다. |
| If I were asked to handle tuning, my approach would be: first, measure and identify the bottleneck by profiling, then research best practices or consult documentation, and validate improvements step by step. |
|
| I’d definitely want to confirm the original intent before making any changes. | 반드시 원래 의도를 확인하겠다. |
| I was tasked with building a data pipeline | 데이터 파이프를 구축하게 되었음 |
| To ensure idempotency, it deletes existing data for each date and regenerates it |
날짜 단위로 기존 데이터를 삭제하고 새로 데이터를 만듦 |
| there was no process in place to verify data quality. |
데이터 품질 검사를 위한 프로세스가 마련되어 있지 않았다. |
| I identified and resolved the root causes of the inconsistency | 원인을 발견하고 해결하였다. |
| The source team’s table had a different primary key (PK) configuration, causing duplicate records. | 데이터 복제를 발생시켰다. |
| Some data was missing because their encryption logic malfunctioned during transmission |
암호화 로직이 잘못 적용되어있었다. |
| we began receiving accurate data consistently. |
정합성있는 데이터를 받을 수 있게 되었다. |
| I carried out a data cleansing process to remove or obscure PII where it would not affect business decisions. |
PII 를 제거하거나 가리기 위해 클렌징 작업을 수행했다. |
| I masked the middle part of names with stars to obfuscate the PII. | 모호하게 하기 위해 이름 중간 부분을 별표로 가렸다. |
| I applied a retention policy to PII, performing a soft delete for any PII older than three months from the current date. | PII 에 retention policy 를 적용하여 현재 날짜로부터 3개월이 지난 모든 PII에 대해 소프트 삭제를 수행했다. |
| I checked cross-version backward compatibility within the EMR environment to ensure there would be no issues after the upgrade. | 업그레이드 후 문제가 발생하지 않도록 EMR 환경 내에서 버전 간 하위 호환성을 확인했다. |
| I then provisioned a new EMR cluster with the latest version | 그런 다음 최신 버전으로 새 EMR 클러스터를 프로비저닝했다. |
| There were KTLO (Keep The Lights On) jobs scheduled by time, similar to crontab |
crontab 처럼, 시간으로 스케줄링 해 둔 KTLO 작업들이 존재함 |
| if an upstream job failed, it caused downstream failures. |
상위 작업이 실패하면 하위 작업의 실패를 초래했다. |
| I modified the code to be idempotent | 코드를 멱등성을 갖도록 수정했다 |
| This reduced human error and improved operational efficiency. | 인적 오류도 감소하고 운영 효율성이 향상되었다. |
| I will proactively seek out and learn technologies I haven't used before. | 사용해 보지 않은 기술을 적극적으로 찾아 배울 것이다. |
| I will invest time to take online courses, research best practices, and get hands-on experimentation. | 온라인 강좌 수강, 모범 사례 연구, 그리고 직접적인 실험을 위해 시간을 투자할 것임 |
| I will ensure no disruption to my work. | 업무에 차질이 없도록 하겠다. |
| work with BA and DS teams, and respond to their requests. |
업무요청 대응하기 |
| I took over the task of synchronizing data | 데이터 동기화 작업을 인수인계 받았다 |
| Occasionally, incorrect data would come in from the source table | 가끔씩 소스 테이블에서 잘못된 데이터가 들어오곤 했다 |
| we only found out days later. | 우리는 며칠이 지나서야 알게 되었다. |
| he told me to retrieve the data for that date again and move it to the target table. |
그 날짜의 데이터를 다시 가져와서 옮기라고 말했다. |
| arbitrarily moving past date data would break consistency. | 임의로 과거 날짜 데이터를 이동하면 일관성이 깨질 수 있다. |
| I learned that rather than just following instructions blindly, I must double-check whether my work is correct |
맹목적으로 따라하지 말고, 내가 하는 일이 잘 하는게 맞는지 재확인 |
| To minimize risk, I created isolated test resources like a dedicated EMR cluster. | 전용 EMR cluster 같이, 분리된 테스트 리소스를 생성했다 |
| Once validated, I safely switched over | 테스트가 마무리 된 이후 새로운 테이블을 기존 테이블로 안전하게 교체하였다 |
| All team members wanted to switch directly to Spark 3 without testing | |
| This could lead to a dangerous situation where the entire operation halts | 이는 전체 작업이 중단되는 위험한 상황으로 이어질 수 있다. |
| once I was assigned to handle WebUI processing using Spring. I was assigned the task of adding functionality to display different screens based on user permissions |
Spring을 사용한 WebUI 처리를 담당하도록 배정받았다. 사용자 권한에 따라 다른 화면을 표시하는 기능을 추가하는 작업을 맡게 되었다. |
| I conducted code reviews with team members to double-check for any shortcomings. | 부족한 점이 없는지 다시 한번 확인했다. |
| I performed a staging deployment to verify that the screens displayed correctly for users with different permissions. | 화면이 올바르게 표시되는지 확인하기 위해 스테이징 배포를 수행했다. |
| I received negative feedback regarding time management. | 시간 관리에 대해 부정적인 피드백을 받았다. |
| I missed the deadline while waiting for approval and received feedback that I failed to meet timelines. |
승인을 기다리다 마감일을 놓쳤고 일정을 지키지 못했다는 피드백을 받았다. |
| I need approval to proceed with my work I applied for approval in advance and requested it multiple times but the response came late |
업무 진행을 위해 승인이 필요하다. 사전에 승인을 신청하고 여러 차례 요청했다 하지만 답은 늦게 도착했다. |
| I will be comfortable working independently and handling tasks reliably. |
독립적으로 업무를 수행하고 신뢰할 수 있게 업무를 처리하는 데 익숙해 질 것이다. |
| I want to participate in decisions about future direction and contribute to the team's future. | 향후 방향에 관한 결정에 참여하고 팀의 미래에 기여하고 싶다. |
| My biggest strength is identifying inefficiencies in systems and improving them. |
|
| I’ve developed a strong habit of documentation and logging. |
|
| I'll share my thoughts along with the materials I researched and gathered beforehand. |
사전에 조사하고 수집한 자료와 함께 내 생각을 공유할 것이다. |
| ROW_NUMBER() assigns a unique sequential number to each row, regardless of whether the values are the same. |
값이 같은지 아닌지 상관 없이 |
| DENSE_RANK() assigns the same rank to rows with the same value, and the next rank is assigned without gaps. | 다음은 갭 없이 랭크가 부여된다 |
| RANK() assigns the same rank to rows with the same value, but it leaves gaps in the ranking sequence after ties. | 같은 값을 갖는 랭크 이후 갭이 있다 |
| Window functions are functions that preserve the context of the original data and do not reduce the number of rows after aggregation. | 집계 후에 원본 데이터 맥락을 유지한다. |
| JOIN combines columns horizontally based on a condition, while UNION combines rows vertically and requires schema compatibility. |
|
| EXISTS ignores null values because it determines whether a row exists. (The existence of a row) |
EXISTS 는 행 존재 여부를 판단하기 때문에 null 을 무시함 |
| but I understand the concept and have worked on similar problems | |
| I’m not familiar with that term, so I don’t want to give an incorrect explanation. | |
| If it’s something I’ve encountered before under a different term, I’d be happy to explain from that perspective. |
혹시 제가 알고있는 개념이라면 보충해서 이야기를 할 수 있을 것 같다 |
| I haven’t worked with Streaming System yet, so I wouldn’t want to explain it inaccurately. |
|
| If your team uses Streaming System in production, I’d make sure to study by watching online lectures, understand how I can use and why it was chosen here, and get hands-on experience so I can work with it safely in a production environment. |
|
| I haven’t had hands-on experience with performance tuning yet. However, I have similar experience in terms of tuning. | |
| I can’t say for certain what the exact reasoning was. |
정확한 이유가 무엇이었는지 단정할 수 없다. |
| However, based on my understanding of the system, one possible reason could be cost efficiency in this part |
하지만 제가 이해한 시스템 구조상 이 부분에서는 비용 효율성이 한 가지 이유가 될 수 있다 |
| I didn’t design it myself, so I’d avoid making assumptions. | |
| The requester wanted data processed with the desired transformation and wished to receive the data via SFTP according to a set schedule. Throughout this process, the requester and I discussed how to handle duplicate data, the final number of files, and how to notify us if issues occur. |
요청자는 원하는 변환 방식으로 처리된 데이터를 원했으며, 정해진 일정에 따라 SFTP를 통해 데이터를 수신하기를 원했다. 이 과정 전반에 걸쳐 요청자와 저는 중복 데이터 처리 방법, 최종 파일 수, 문제 발생 시 통보 방식에 대해 논의했다. |
| We conducted many tests and completed the work as the requester wanted. As a result, I successfully built the data pipeline, and the requester received the desired data. |
우리는 여러 차례 테스트를 수행하고 요청자가 원하는 대로 작업을 완료했습니다. 그 결과, 데이터 파이프라인 구축에 성공했으며 요청자는 원하는 데이터를 수령했습니다. |
| Just retrieve the data for the date the issue was created | 이슈를 만든 날짜의 데이터를 찾아라. |
| I proceeded with the task that way | 그 방식으로 작업을 진행했다. |
| Therefore, arbitrarily moving past date data would break consistency. |
따라서 과거 날짜 데이터를 임의로 이동하면 일관성이 깨질 것이다. |
| We only discovered this much later. |
그제서야, 나중에야, 뒤늦게서야...(아쉬움) |
| S3 doesn't have the concept of directories. | s3 는 디렉토리 개념이 없다 |
| Durability refers to the potential for data loss. Durability refers to the likelihood of not lossing data. Availability refers to the probability of being able to read data without issues. |
Durability : 데이터를 잃어버릴 가능성. 99.999999999% Availability : 데이터를 문제없이 읽을 수 있는 확률 |
| We can use tags as indicators for distinguishing pusrposes when settling accounts later. |
s3 bucket 에 tag 를 달면, 나중에 정산할 때 구분을 위한 지표로 사용 가능함 |
| Glue Crawlers parse and infer from the csv file |
Glue Crawlers 는 이 csv 파일의 정보를 분석하고 추론함 |
| It remembers how far it previously collected data and resumes collection from the point where it stopped. |
이것은 이전에 데이터를 수집한 지점을 기억하고 중단된 지점부터 수집을 재개한다. |
| There are spaces before and after the name. |
고객명 앞뒤 공백 있음 |
'English' 카테고리의 다른 글
| [English] technical expressions in Spark (0) | 2025.08.12 |
|---|---|
| [Eng] 소설책에서 가져온 좋은 표현들 (0) | 2025.08.05 |
| [IT] 견고한 데이터 엔지니어링 정리 및 영어 공부 6 (0) | 2025.07.01 |
| [IT] 견고한 데이터 엔지니어링 정리 및 영어 공부 5 (0) | 2025.06.27 |
| [IT] 견고한 데이터 엔지니어링 정리 및 영어 공부 2 (1) | 2025.06.24 |