hortenworks 에서 제공하는 Apache NiFi Crash Course 를 보고 필기한 내용임
- dataflow 에는 byte 를 담아서 보낼 수 있는데, 담기는 byte 는 무엇이든지 될 수 있음
예를 들면 Logs, HTTP, XML, CSV, Images, Video, Telemetry, IoT Signal .... 아무거나 다 담겨서 dataflow 로 이동 가능!
- dataflow 를 받는 주체는 유저가 될 수도, storage system 이 될 수도, 혹은 그 외의 다른 시스템(kafka elasticache.. 등)이 될 수 있음
- 이쪽 플랫폼에서 다른 플랫폼으로 빅데이터를 옮긴다는 것은 쉬운 일이 아님.
이를 해결하기 위해 많은 것들이 필요함
Data 의 포맷, 운반 프로토콜, 스키마에서부터
"Exactly Once" delivery, 암호화, 권한 관리, 네트워크, 시간, 조직 등 신경써야 할 것들이 엄청나게 많음
근데 NiFi 가 이런 것들을 해결해준다는 건가...?
- flowfile 은 flowfile 이 갖는 '데이터' 그 자체와, '데이터에 대한 정보'(메타데이터) 를 둘 다 담고 있다.
마치 HTTP 가 header 와 content 를 담고 있는 것처럼.

- NiFi 가 processor 로 연동 가능한 시스템은 260개 이상이다.
게다가 커스텀 processor 까지 만들 수 있다!

- Reporting Task 는, NiFi 에서 다른 외부 서비스로 data (metrics, provenance 등) 를 push 하는데 사용됨
- Rest API 를 이용하여 외부 사용자들이 NiFi 를 컨트롤 할 수 있도록 할 수 있다.
rest api 를 이용하여 사용자들이 nifi 로부터 정보를 받아가거나, 혹은 행동을 바꾸게 할 수 있다.

- 위는 NiFi 의 standalone 구졸르 보여줌.
NiFi 는 JVM 위에서 동작함
- JVM 은 jetty 를 embedded 하고 있는 Web Server 를 운영함
jetty 는 자바 기반의 HTTP 웹 서버라고 함.
- JVM 은 Flow Contolloer 도 운영하는데, 이 Flow controller 는 프로세싱, 스케줄링 등을 담당함.
또한 프로세서들을 갖고 있음. NiFi WebUI 에서 운영자가 실행을 위해 하나 둘 씩 놓아둔 프로세서 그거 맞음
5개짜리 간단한 프로세서일 수도 있고, enterprise 급 10,000개 짜리 거대한 프로세서일 수도 있음.
- JVM 은 또한 여러 Repository 들을 storage 에 저장하는 역할도 함.
FlowFile Repo 는 FlowFile 로 향하는 정보를 담고 있음. 일종의 포인터를 담고 있다고 보면 되겠다.
현재 NiFi 에서 이용되고 있는 FlowFile 포인터(FlowFile Repo 가 담고있는 것)는 메모리에 올라가있으며, 매우 빠름.
Content Repo 는 FlowFile 의 실제 byte 데이터를 갖고 있음.
때문에 크기는 굉장히 다양함. kb 단위로 작을 수 도 있고 tb 단위로 클 수 있음
처리하는 속력은 느리다고 함. 메모리에 올라가있지 않아서 그런가? 이유는 내가 이해를 못 함
Provenance Repo 는 FlowFile 의 메타데이터를 갖고 있음.
생성 시간이나, 고유값, 데이터 크기 등
게다가 FlowFile 이 어떻게 변화해가는지 그 역사?를 모두 기록함.
발표자가 하는 말이,
FlowFile 은 마치 작은 파리같은 녀석이라고 하고,
Content 는 코끼리, Provenance 는 무슨 일이 있었는지 모두 기록하는 history 같은 녀석이라고 함.
아래, Repo 들의 역할을 예제를 들어 더 자세히 설명하는 부분이 나옴

- 위는 NiFi 클러스터의 구조를 보여줌.
클러스터를 구성하는 노드는 최대 10개 정도로 하는 것을 추천한다고 함.
이유를 말해주었는데 정확하게 이해를 못 함 (하둡같은 cluster 와 다르게, data 를 주고받는데 오버헤드가 있어서 그런가?)
- 각 노드의 구조는 위에서 설명한 standalone 구조를 갖고 있음.
이미지를 보면 각 노드마다 standalone 에서 설명한 이미지를 그대로 담고 있는 것을 볼 수 있음
- 각 노드들은 Zookeeper 에 의해 연결되어있음.
각 노드들 중 Coordinator 와 Primary Node 역할을 하는 노드가 있음.
이 역할은 한 노드가 둘 다 맡을 수도 있고, 각기 다른 노드가 맡을 수 있음.
이 역할을 맡은 노드가 죽으면, 대신 다른 살아있는 노드 중 하나가 역할을 맡는데, 이 과정을 Zookeeper가 도와줌
- Repo 가 담고있는 정보가 무엇인지, 상황을 가정하여 이해해보자.
flowfile 의 흐름에 따라 FlowFile, Content, Provenance Repo 에 어떤 정보가 쌓이는지 살펴봄
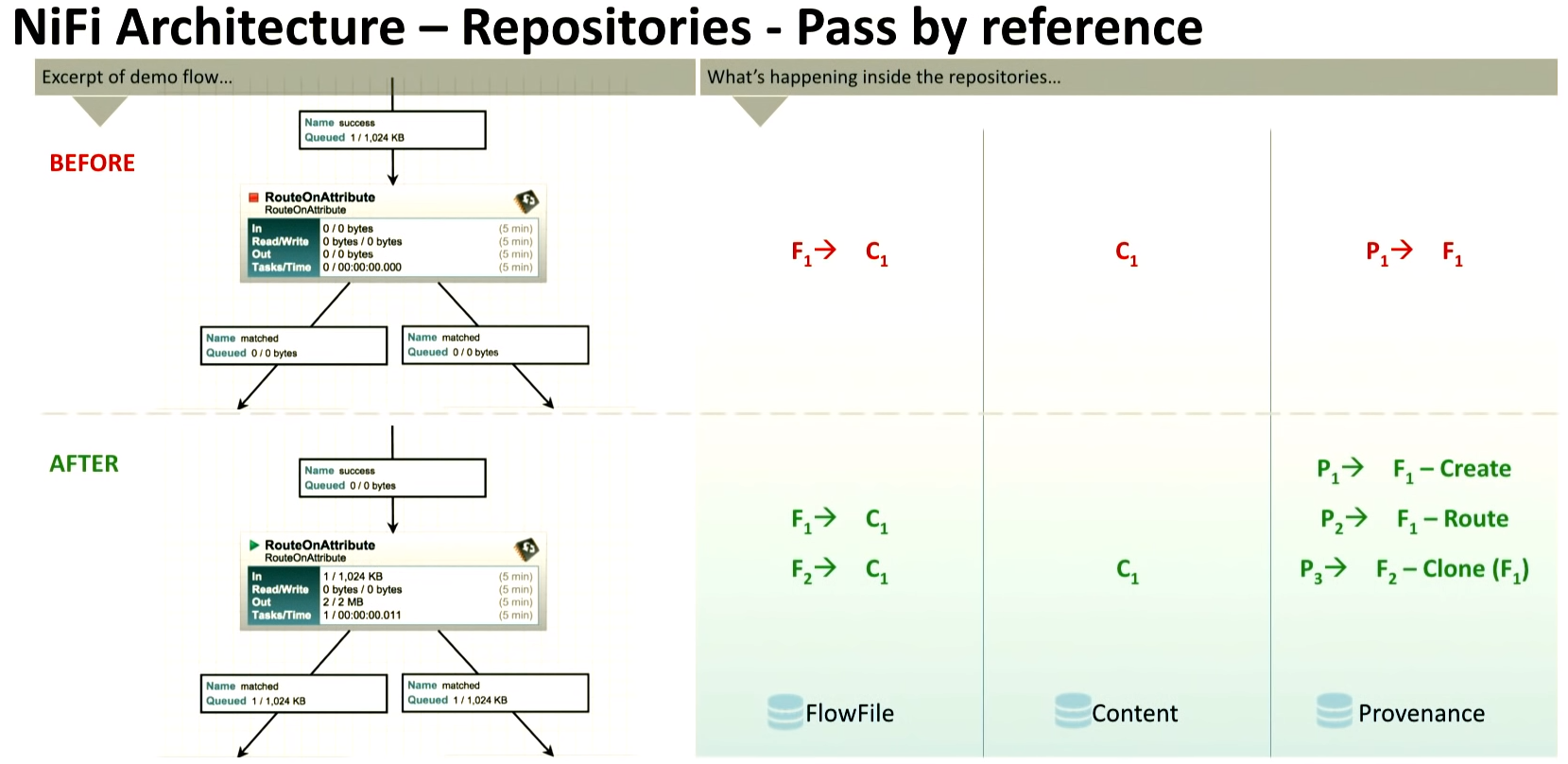
| <Before> - FlowFile Repo : 존재하는 하나의 FlowFile 의 내용(C1)을 포인팅하는 F1 을 담고 있음 - Content Repo : 존재하는 하나의 FlowFile 의 내용 C1 을 담고 있음 - Provenance Repo : F1의 정보를 담고 있음. |
| <After> - FlowFile Repo : RouteOnAttribute 를 지난 후 FlowFile 이 2개가 되었음. 이 프로세서는 똑같은 내용을 복사하는 역할을 함. 따라서 FlowFile Repo 는 존재하는 하나의 FlowFile 의 내용(C1)을 포인팅하는 F1, F2 을 담게 됨 왜냐하면 C1은 바뀌지 않았고 하나가 유지되지만, FlowFile 은 2개가 되었으니까. - Content Repo : 존재하는 하나의 FlowFile 의 내용 C1 을 담고 있음 - Provenance Repo : F1의 정보를 담고 있음. 과거(Before) 의 F1 정보와, 현재(After)의 두 가지 FlowFile 의 정보(F1,F2)를 모두 갖고 있음 |
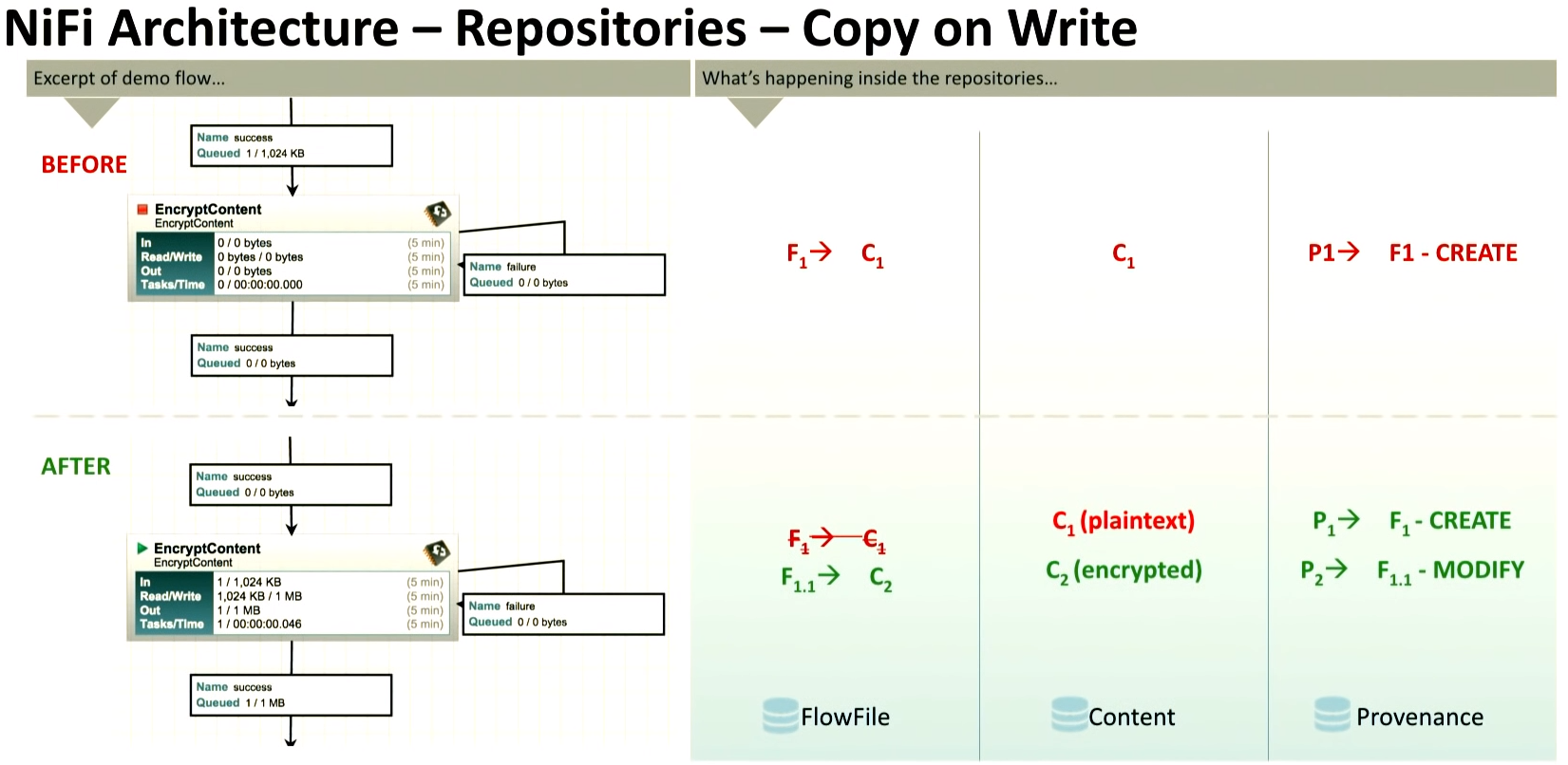
| <Before> - FlowFile Repo : 존재하는 하나의 FlowFile 의 내용(C1)을 포인팅하는 F1 을 담고 있음 - Content Repo : 존재하는 하나의 FlowFile 의 내용 C1 을 담고 있음 - Provenance Repo : F1의 정보를 담고 있음. |
| <After> - FlowFile Repo : EncryptContent 를 지난 후의 데이터(C2 를 포인팅하는 F1.1 을 담고 있음 과거 데이터 C1 을 포인팅하지는 않음. FlowFile Repo 는 현재 Content Repo 의 데이터만 포인팅하는 F 들만 담음 - Content Repo : 암호화되기 이전에 C1과 암호화 된 후 C2를 모두 보관함. 따라서 크기가 C2 만큼 커짐. - Provenance Repo : F1의 정보를 담고 있음. 과거(Before) 의 F1 정보와, 현재(After)의 FlowFile 의 정보(F1.1)를 모두 갖고 있음 |
- 데이터를 처리할 때, 데이터를 처리하기 전 Content + 데이터를 처리한 후 Content 이렇게 둘 다 Content Repo 에 남아있어서
용량을 많이 차지했는데, 1.2 버전 이후로는 Reader, Writer Controller Service 를 사용해서 그런 중복 저장을 하지 않는다고 함.
그래서 performance 을 내는데도 큰 영향을 끼침
뭔 말인지 모르겠따 위에 예는 그럼 1.2 이전 버전을 보여준건가? 굳이??
- 모든 Provenance event record (Provenance Repo 내에 저장되는 데이터) 는 AES G/CM 으로 암호화된다고 함.
언제 복호화 되느냐? NiFi 에서 query 를 하거나 history 검색을 할 때 복호화 되어 우리가 읽을 수 있게 됨.
- NiFi Registry 의 도입 개기는 다음과 같음.
Registry 가 없던 이전에는 flow 를 XML template 으로 저장하고 가져오곤 했음
이 방법으로는 sensitive values 를 유지할 수 없었고,
동작중일 때 업데이트 할 수 없었고(? Couldn't be updated in-place 이 부분은 영어 해석 못 하겠네)
시스템을 트래킹 할 수 없었음(? 이건 무슨 의민지 모르겠따)
여튼 불편한 부분이 많아서 flow 를 git처럼 version control 할 수 있도록 Registry 를 만듦
이후에는 실제 NiFi 를 이용한 데모를 보여줌.
'NiFi' 카테고리의 다른 글
| [NiFi] Elasticsearch 와 연동하는 flow 작성 (0) | 2021.02.04 |
|---|---|
| [NiFi] 처음 flow 생성시 도움되는 참고 링크(영어) (0) | 2021.02.04 |
| [NiFi] putHDFS, getHDFS 연결 및 권한 문제 (0) | 2021.01.28 |
| [NiFi] HA 관련하여 찾아본 정보 및 내 생각 (0) | 2021.01.15 |
| [NiFi] Kerberos protocol 동작 순서 및 NiFi 적용 방법 링크 (0) | 2020.12.30 |