도커/쿠버네티스를 활용한 컨테이너 개발 실전 입문 <- 이 책 비추천
쿠버네티스 입문 : 90가지 예제로 배우는 컨테이너 관리 자동화 표준 <- 이 책 추천
책을 읽으며
공부한 내용 필기
쿠버네티스란?
컨테이너 운영을 자동화하기 위한 컨테이너 오케스트레이션 도구
많은 수의 컨테이너를 협조적으로 연동시키기 위한 통합 시스템
이 컨테이너를 다루기 위한 API 및 명령행 도구 등이 함께 제공
컨테이너를 이용한 앱 배포 외에도 다양한 운영 관리 업무 자동화 가능
(도커 호스트 관리, 서버 리소스의 여유를 고려한 컨테이너 배치, 스케일링,
여러 개의 컨테이너 그룹에 대한 로드밸런싱, 헬스 체크 등의 기능 제공)
쿠버네티스는 컴포즈/스택/스웜의 기능을 통합해 더 높은 수준의 관리 기능을 제공하는 도구라고 볼 수 있음
쿠버네티스에서 desired state 를 설정해두면 쿠버네티스가 현재 state 와 desired state 를 비교하여
상태가 일치하도록 알아서 바꿔줌.
컨테이너를 추가하거나, 삭제하는 등....
쿠버네티스는 크게 오브젝트와 오브젝트를 관리하는 컨트롤러로 나뉨.
Template 등으로 쿠버네티스에 자원의 desired state 를 정의.
컨트롤러는 desired state 와 current state 가 일치하도록 오브젝트들을 생성/삭제함.
여기서 말하는
오브젝트는 파드, 서비스 ,볼륨, 네임스페이스 등을 말 함
컨트롤러는 레플리카세트, 디플로이먼트, 스테이트풀세트, 데몬세트, 잡 등을 말 함
노드 : 컨테이너가 배치되는 서버
네임스페이스 : 쿠버네티스 클러스터 안의 가상 클러스터
파드 : 컨테이너의 집합 중 가장 작은 단위. 컨테이너의 실행 방법을 정의
디플로이먼트 : 레플리카 세트의 리비전을 관리
서비스 : 파드의 집합에 접근하기 위한 경로를 정의
인그레스 : 서비스를 쿠버네티스 클러스터 외부로 노출
너무 설명을 압축해놔서 무슨 소린지 하나도 모르겠따.
< 네임 스페이스 >
쿠버네티스 클러스터 하나를 여러 개 논리적인 단위로 나누어 사용하는 것.
이 덕분에 쿠버네티스 클러스터 하나를 여러 개 팀이나 사용자가 함께 공유 가능
클러스터 내에서 용도에 따라 실행해야 하는 앱을 구분 할 때도 네임 스페이스를 사용함.
(별도 쿼터를 설정해서) 특정 네임스페이스의 사용량을 제한할 수도 있음.
kubectl 로 네임스페이스 지정해 사용할 때는 --namespace=kube-system 처럼 하면 됨
지정 안 하면 default 네임스페이스가 적용됨 (--namespace=default)
기본 네임스페이스를 다르게 줄 수 있음.
config set-context 명령어를 이용하는데 이건 여기서 다루지 않겠음.
어떤 파드의 기본 네임스페이스를 어떻게 설정했는지 헷갈린다면(갑자기 파드가 툭 튀어나왔네?)
파드의 전체 네임스페이스를 한번에 찾기 위해 아래 명령어 사용
kubectl get pods --all-namespaces
< 템플릿 >
클러스터의 오브젝트나 컨트롤러가 어떤 상태여야 하는지를 적용할 때 YAML 형식의 템플릿을 사용
아래 이미지처럼 세 가지 형태로 표현 가능
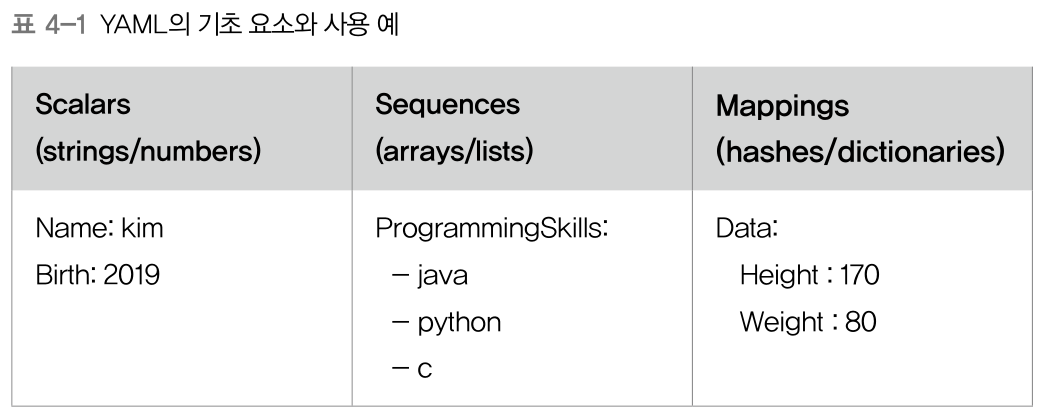
템플릿 기본 형식은 다음과 같음
apiVersion: v1
kind: Pod
metadata:
spec:
apiVersion : 사용하는 쿠버네티스 API 버전을 명시.
kubectl api-versions 명령으로 현재 클러스터에서 사용 가능한 API 버전 확인 가능
kind : 어떤 종류의 오브젝트/컨트롤러에 작업인지 명시
만약 Pod 라고 쓰면 파드에 관한 desired state 를 만듦.
Pod, Deployments, Ingress, ReplicaSet 등이 들어감.
metadata : 메타데이터 설정
오브젝트의 이름이나 레이블 등을 설정
spec : 파드가 어떤 컨테이너를 갖고 실행하며, 실행할 때 어떻게 동작해야 할지 명시
템플릿에 뭘 넣어야 할 지 모르겠다면
kubectl explain pods
kubectl explain pods --recursive
kubectl explain deployments
kubectl explain deployments.metadata
처럼 explain 명령을 사용하여 나오는 정보 확인
< 노드 >
컨테이너는 노드의 리소스 사용 현황 및 배치 전략을 근거로 컨테이너를 적절히 배치함
클러스터에 배치된 노드의 수, 노드의 사양 등에 따라 배치할 수 있는 컨테이너 수가 결정됨
또한 클러스터 처리 능력은 노드에 의해 결정됨
만약 클라우드에서 동작하는 쿠버네티스라면
GCP의 경우 GCE 가 노드가 되고
AWS의 경우 EC2 가 노드가 됨
노드 중에는 Slave 처럼 일을 하는 일반 노드가 있고
Master 처럼 관리를 위한 Master 노드가 있음
Master 노드에는 관리용 컴포넌트가 담긴 파드(컨테이너)만 배포됨
실질적인 작업은 일반 노드에서 이루어지고, 전체 노드의 관리는 Master 노드가 담당함
< 파드 >
쿠버네티스는 파드라는 단위로 컨테이너를 묶어서 관리.
보통 여러 개의 컨테이너가 하나의 파드에 묶임
파드로 컨테이너 여러 개를 한번에 관리할 때는 컨테이너마다 역할을 부여할 수 있음
아래 이미지를 보면, 파드 내에 세 개의 컨테이너가 있고 각각 역할이 다른 걸 볼 수 있음.

파드 하나에 속한 컨테이너들은 모두 노드 하나 안에서 실행(하나의 파드가 여러 노드에 걸쳐있을 순 없음.)
파드의 역할 중 하나가 컨테이너들이 같은 목적으로 자원을 공유하는 것.
파드 하나 안에 있는 컨테이너들은 파드가 갖고 있는 IP(위의 예제에서 192.168.1010)를 모두 공유함.
즉 외부에서 이 파드에 접근할 땐 파드의 IP 로 접근.
파드 안 컨테이너와 통신할 땐 컨테이너마다 다르게 설정한 유니크한 포트 번호 사용
(각 컨테이너가 모두 같은 IP를 갖으므로 컨테이너들을 구분하기 위해 포트를 사용)
대개 관리 효율을 위해 하나의 컨테이너가 하나의 역할을 맡도록 한다고 함
아래 이미지는 파드 설정 예제 yaml 파일임. 이 yaml 설정 파일로 파드를 띄울 수 있음

1) metadata.name : 파드의 이름
2) metadata.labels.app : 오브젝트(파드)를 식별하는 레이블 설정
여기선 해당 파드가 앱 컨테이너이고 kubernetes-simple-pod 라고 식별한다고 설정
(1번처럼 파드 이름이 따로 있는데 식별하려고 label 을 따로 두는 이유는 레플리카 세트 부분에서 나옴.
일단 변경 가능한(나중에 edit 할 수 있음) 추가 식별자가 하나 더 생겼다 라고 이해하자)
3) spec.containers[].name : 파드 내에서 실행할 컨테이너의 이름
여러 개 들어갈 수 있기 때문에 배열로 정의
4) spec.containers[].image : 파드 내에서 실행할 컨테이너에서 사용할 이미지
5) spec.containers[].ports[].containerPort : 해당 컨테이너에 접속할 포트 번호
위에서 설명한 것처럼 컨테이너에 접근하기 위해 컨테이너마다 유니크하게 갖고 있는 포트 번호
위의 yaml 을 아래 명령어로 실행시켜서 파드를 하나 띄움.
kubectl apply -f pod-sample.yaml
아래 명령어로 잘 띄워졌는지 확인
kubectl get pods
파드 생명 주기는 다음 명령어로 확인 가능
kubectl describe pods [파드 이름]
kubectl describe pods kubernetes-simple-pod
나온 결과에서 Status 확인
생명 주기 Status 는 다음과 같음
- Pending : 쿠베에서 파드를 생성하는 중.
컨테이너 이미지 받고 전체 컨테이너 실행하는 중이라 실행까지 시간이 좀 걸림
- Running : 파드 내의 모든 컨테이너가 실행 중.
- Succeeded : 파드 내의 모든 컨테이너가 정상 실행 종료된 상태. 재시작되지 않음
- Failed : 파드 내의 모든 컨테이너 중 정상적으로 실행 종료되지 않은 컨테이너가 존재
컨테이너 종료 코드가 0이면 정상종료
컨테이너 종료 코드가 0이 아니면 비정상 종료(예를 들어 out of memory의 종료 코드는 137) 이거나
시스템이 직접 컨테이너를 종료한 것
- Unknown : 파드의 상태를 확인할 수 없음.
보통 파드가 있는 노드와 통신이 불가할 때 Unknown 이 뜬다고 함
파드에 CPU 와 Memory 자원을 얼마나 줄 지 제한할 수 있음.
파드 템플릿 yaml 파일에
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
와 같은 필드값을 넣어주면 됨.
예를 들어

request 는 최소 자원 요구량을 나타냄
파드가 실행할 때 최소 request 만큼의 자원 여유가 있는 노드가 있어야 파드를 그곳에 스케줄링함.
request 만큼의 자원이 없다면 파드는 여유 자원이 생길 때까지 Pending 상태로 멈춰있음
limit 은 최대 사용할 수 있는 자원량을 나타냄
limit 이 없으면 노드의 모든 자원을 소모함
쿠버네티스는 파드 스케줄링 할 때 노드의 request 와 limit 을 확인하여 스케줄링 함.
CPU 1 은, 코어 하나의 연산 능력을 온전히 사용할 수 있다는 것을 의미함
CPU 0.5 는, 코어 하나의 50% 연산 능력까지만 활용할 수 있도록 제한하는 것을 의미함
파드를 구성하는 패턴이 있음
- 사이드카 패턴 : 파드 내에 원래 목적의 기능에 충실한 기본 컨테이너와,
추가적으로 기본 컨테이너에 부가 기능을 담당하는 사이드카 컨테이너를 넣음
웹서버를 예로 들어봄.
웹 서버 역할을 하는 기본 컨테이너가 존재하는데 이 컨테이너는 로그를 파일로 남김
여기에 추가적으로 로그 파일을 수집하여 외부 저장소로 옮기는 사이드카 컨테이너를 넣어 사용할 수 있음

- 어댑터 패턴 : 파드 외부로 노출되는 정보를 표준화하는 중간 어댑터 컨테이너를 두어 사용함
주로 어댑터 컨테이너로 파드의 모니터링 지표를 표준화한 형식으로 노출시키고,
외부의 모니터링 시스템에서 해당 데이터를 주기적으로 가져가서 모니터링하는데 이용.

쿠버네티스에선 결합이 강한 컨테이너들(예를 들면 nginx 와 Go 애플리케이션)을
하나의 파드로 묶어 일괄 배포한다고 함.
물론 컨테이너가 하나인 파드도 있음.
하나의 파드에 여러 컨테이너가 들어가는 경우는,
위에서 설명한 것처럼 결합이 강한 컨테이너들
일을 함께 하는 컨테이너들
함께 배포해야 정합성이 유지되는 컨테이너들
등등
노드에는 하나 이상의 파드가 들어감
파드는 노드에 들어가는데, 여러 노드에 여러개 배치할 수 있고,
하나의 노드에 여러개 배치할 수 있음.
크기 : 노드 > 파드 > 컨테이너 라고 생각하면 될 듯.
근데 컨테이너를 '파드'로 묶어서 사용하는 이유는 뭘까?
my-pod 라는 이름의 파드 안의 컨테이너에게 exec 를 사용하여 컨테이너 안에 접근 가능.
마치 docker container 접속시 docker exec -it my-container bash 명령어처럼.
만약 파드 안에 my-nginx라는 이름의 container 가 하나 실행중이라고 하자.
kubectl exec -it [pod 이름] sh
kubectl exec -it my-pod sh
만약 my-pod 라는 이름의 파드 안에
my-nginx 라는 이름의 컨테이너 하나와 your-nginx 라는 이름의 컨테이너 하나가 있다고 하자.
이 때는 -c 명령어를 통해 컨테이너 이름을 직접 지명해줌
kubectl exec -it my-pod sh -c my-nginx
kubectl exec -it my-pod sh -c your-nginx
파드 내 컨테이너의 로그를 보려면 아래 명령어를 사용
kubectl logs -f [pod 이름] -c [컨테이너 이름]
kubectl logs -f my-pod -c my-nginx
pod 삭제하려면 아래 명령어 사용
kubectl delete pod [pod 이름]
kubectl delete pod my-pod
혹은
kubectl delete -f my-yaml.yaml
그럼 my-yaml.yaml 로 생성된 모든 파드가 삭제됨

위에 설명을 보면 알겠지만, 파드마다 각자 할당받은 가상 IP 가 있고 이걸로 파드 내의 컨테이너에 접근 가능함.
파드 간 서로 접근이 가능한다 보다.
파드 내 컨테이너가 노출하고 있는 포트는 겹치면 안 된다.
왼쪽 파드의 첫번째 컨테이너는 80번 포트를 노출시키고 있고
왼쪽 파드의 두번째 컨테이너는 8080 번 포트를 노출시키고 있다. 80번 포트를 사용할 수 없다.
오른쪽 파드의 첫번째 컨테이너는 80번 포트를 노출시키고 있다. 왼쪽 파드와 IP 자체가 다르므로 80번 포트 사용 가능
< 레플리카 세트 >
레플리카 세트는 똑같은 정의를 갖는 파드를 여러 개 생성하고 관리하기 위한 리소스.
지정된 숫자만큼의 파드가 항상 클러스터 안에서 실행되도록 관리함.
다음 이미지는 레플리카 세트를 설정하기 위한 yaml 파일.

metadata.name : 레플리카 세트의 이름
1) spec.template : 레플리카 세트가 자동으로 실행할 파드에 관한 정보를 담고 있음.
이 부분이 desired status 라고 이해하자.
여기서는 파드 이름이 nginx-replicaset 이고 오브젝트 식별하는 레이블이 앱 컨테이너고 nginx-replicaset 라고 식별한다고 설정. 마치 파드 템플릿 설정하는 내용과 같음
2) spec.template.spec.containers[] : name, image, ports[], containerPort 등의 필드로 컨테이너의 구체적인 명세를 설정.
여기서는 이름을 nignx-replicaset, 이미지는 nginx, 해당 컨테이너의 포트 번호는 80으로 설정
3) spec.replicas : 파드를 몇 개 유지할지 개수 설정. default 1
4) spec.selector : 어떤 레이블(labels)의 파드를 선택하여 관리할지 설정
이 레이블을 기준으로 파드를 관리하므로 실행 중인 파드를 중단하거나 재시작하지 않고
레플리카 세트가 관리하는 파드를 변경할 수 있음
그래서 처음 레플리카 세트 생성시 spec.template.metadata.labels 의 하위 필드 설정과 spec.selector.matchLabels 의 하위 필드설정이 같아야 함
(다르면 kube-apiserver 에서 유효하지 않은 요청이라 판단하여 파드 변경을 거부한다고)
템플릿에 별도의 spec.selector 설정이 없으면 spec.template.metadata.labels.app 에 있는 내용을 기본값으로 설정.
다시 말하면, 레플리카 세트는 spec.selector 기준에 맞는 파드들을 대상으로 spec.template 기준을 적용하고 있음.
예를 들어 spec.selector 기준에 맞는 파드 개수가 2개인데 spec.replicas 는 3이다? 그러면
spec.template 에 맞는 파드를 하나 실행함.
만약 spec.template 로 생성한 파드 3개가 올라와 있는 상황에서 하나의 파드 레이블을 (edit 을 통해) 다르게 바꾸면
레이블이 바뀐 파드는 spec.selector 기준에 맞지 않게 됨
레플리카 세트 입장에서는 갑자기 파드 하나가 사라진 것 처럼 보일 것임
그래서 레플리카 세트는 spec.template 기준에 맞는 파드를 하나 생성함.
결과적으로 spec.selector 기준에 맞는 파드 3개와 아까 레이블을 바꿨던 파드 1개, 총 4개의 파드가 올라가게 됨.
yaml 파일 내에서
selector 에 정의된 label 에 맞는 파드를 채우기 위해
template 에 정의된 파드를 replicas 개수만큼 만든다.
만약 장애가 나서 파드 중 하나가 끊기거나 꺼지거나 사라지거나 삭제되면
레플리카 세트가 빈 파드 자리를 인지하고 바로 desitred status 가 되도록 하나의 파드를 채운다.
반대로 파드가 하나 더 많아져도, 늘어난 파드 개수 만큼 제거한다.
파드를 직접 실행해서 띄우면, 파드에 이상이 생겨 종료되거나 삭제되었을 때 재시작하기 어려움.
레플레카 세트는 그걸 도와줌.
레플리카세트를 배포하면 파드가 replicas 개수만큼 만들어지는데,
이 때 파드의 이름 뒤에 무작위로 생성된 접미사가 붙어 파드 구분이 가능해짐.
삭제할 때는 다음 명령어 사용
kubectl delete -f my-yaml.yaml
< 디플로이먼트 >
디플로이먼트는 쿠버네티스에서 상태가 없는 stateless 앱을 배포할 때 사용하는 가장 기본적인 컨트롤러
디플로이먼트는 애플리케이션 배포의 기본 단위가 되는 컨트롤러
레플리카세트를 관리하고 다룸
레플리카 세트를 관리하며 앱 배포를 더 세밀하게 관리함
단순 실행시켜야 할 파드 개수를 유지하는 것 뿐 아니라 앱을 배포할 때 롤링 업데이트를 하거나,
앱 배포 도중 잠시 멈췄다가 다시 배포할 수 있음
쿠버네티스는 deployment 를 단위로 애플리케이션을 배포함.
레플리카세트를 직접 만지지 않고 deployment를 사용
디플로이먼트가 관리하는 레플리카세트는
지정된 개수만큼 파드를 확보하거나
파드를 새로운 버전으로 교체하거나
이전 버전으로 롤백하는 등의 중요한 역할을 함.
레플리카 세트 대신 디플로이먼트를 사용하는 이유 중 하나는 rolling-update 옵션 사용 가능
아래 이미지는 디플로이먼트 설정을 위한 yaml 파일 예제임



kind 가 deployment 인 것을 제외하고는 레플리카 세트와 차이가 없음.
위의 yaml 파일을 이용하여 디플로이먼트를 실행하면 아래처럼 됨


디플로이먼트(nginx-deployment) 가 있고
이 디플로이먼트가 관리하는 레플리카세트(nginx-deployment-795f6645f5) 도 있고
파드도 3개(nginx-deployment-795f6645f5-XXXXX) 잘 실행되었음
yaml 파일을 어떤 kubectl 명령으로 실행했는지 기록을 남기는 옵션은 --record
예를 들면
kubectl apply -f my-yaml.yaml --record
디플로이먼트를 수정하면 레플리카세트가 새로 생성되고 기존 레플리카 세트와 교체됨
디플로이먼트에 의해 레플리카 세트가 교체되면 리비전 번호가 올라감
예를 들어 yaml 에서 컨테이너 이미지를 다른 것으로 수정한 후
kubectl apply -f my-yaml.yaml --record
명령어를 수행하면 바뀐 부분이 새로 적용되면서 기존의 파드가 정지되고 새로운 파드가 생성됨
이 후 아래 명령어를 통해 리비전 번호를 확인하면 올라가 있는 것을 확인 가능
kubectl rollout history deployment [디플로이먼트 이름]
kubectl rollout history deployment my-deployment
아래 명령어를 통해 리비전의 내용을 확인 가능
예를 들어 4번 리비전의 내용을 보고 싶다면
kubectl rollout history deployment my-deployment --revision=4
undo 명령을 통해 바로 직전 리비전으로 rollback 가능
kubectl rollout undo deployment my-deployment
특정 ㅅ리비전으로 가려면 --to-revision=[리비전 숫자] 옵션을 사용
kubectl rollout undo deployment my-deployment --to-revision=3
근데 undo 로 rollback 하게 되면 상태는 직접 리비전으로 가지만 리비전 번호는 하나 올라감
예를 들어 리비전 번호 1,2,3 이 있었고 내가 3>2로 가고 싶어서 undo 를 하면
상태는 리비전 2 때의 상태가 되지만 리비전은 1,3,4 가 됨.
추가로 --to-revision 으로 3으로 갔다면? 리비전은 1,4,5 가 됨.
디플로이먼트는 kubectl rollout 명령으로 진행중인 배포를 잠시 멈췄다가 다시 시작할 수 있음.
멈췄을 때는 파드가 하나 사라져도 채우지 않음
kubectl rollout pause deployment [디플로이먼트 이름]
다시 resume 시키면 그제서야 사라진 파드 하나를 채우게 됨.
kubectl rollout resum deployment [디플로이먼트 이름]
모든 파드를 재시작 할 수 있음.
kubectl rollout restart deployment [디플로이먼트 이름]
디플로이먼트를 삭제하려면 아래 명령어 사용
kubectl delete -f my-yaml.yaml
디플로이먼트가 배포 중 실패하는 케이스는 대개 다음과 같음.
- 쿼터 부족
- readinessProbe 진단 실패
- 컨테이너 이미지 가져오기 에러
- 권한 부족
- 제한 범위 초과
- 앱 실행 조건을 잘못 지정
< 데몬 세트 >
데몬세트는 클러스터 전체 노드에 '특정 파드(로그 수집기 등)'를 실행할 때 사용하는 컨트롤러
로그 수집기나 모니터링하는 데몬 등, 클러스터 전체에 항상 실행시켜둬야 하는 파드에 사용

클러스터 안에 새롭게 노드 추가시, 데몬 세트가 자동으로 해당 노드에 파드를 실행
반대로 노드가 클러스터에서 삭제되면 해당 노드에 있던 파드는 사라질 뿐 다른 곳으로 옮겨가 실행되거나 하진 않음
즉, 데몬 세트가 항상 실행되어야 하는 파드를 실행시킴. 노드가 추가되면 추가된 노드에서 실행시킴



아직은 이해가 안 되서 일단 설명을 가져옴.
< 스테이트풀세트 >
앞서 보았던 레플리카 세트, 디플로이먼트는 상태가 없는 stateless 파드들을 관리하는 용도
지금 살펴볼 스테이트풀 세트는 상태가 있는 파드들을 관리하는 컨트롤러
스테이트풀 세트를 사용하면 볼륨을 사용하여 특정 데이터를 저장한 후, 파드를 재시작했을 때 해당 데이터 유지
여러 개의 파드 사이에 순서를 지정하여 실행되도록 할 수도 있음
이런 식으로 어떤 상태가 있어야 할 때 사용함
다음은 스테이트풀 세트를 사용하는 설정 예



스테이트풀 세트를 실행하면, 파드가 순서대로 하나씩 실행
kubectl get pods 명령어 결과가 다음과 같이 나타남

기존과 다르게 파드 이름에 UUID 형식 접미사 대신 web-n 처럼 숫자가 순서대로 붙음
파드 실행시 작은 숫자부터 순서대로 실행
앞 순번 파드가 제대로 실행되지 않으면 뒷 순번 파드들은 실행되지 않음.
예를 들어 0번이 제대로 실행되지 않았다면 1번은 실행되지 않음.
파드 삭제시엔 큰 숫자의 파드부터 순서대로(2-1-0) 삭제됨
만약 spec.replicas 값을 1로 줄이면 2, 1 순으로 파드가 삭제됨
spec.podManagementPolicy 를 변경하여 순서를 없애고 병렬로 실행되거나 종료되도록 할 수 있음.
기본 값은 OrderedReady 이고, Parallel 로 바꿀 수 있음.
spec.updateStrategy.type 필드를 설정하여 스테이트풀 세트의 업데이트 방법을 바꿀 수 있음
기본값은 RollingUpdate.
템플릿을 변경했을 때 자동으로 예전 파드를 삭제하고 새로운 파드를 실행
spec.updateStrategy.rollingUpdate.partition 필드 값을 바꾸면 스테이트풀 세트에 변경 사항이 생길 때 마다
해당 필드의 값 이상의 큰 번호를 가진 파드(예를 들어 필드 값이 3이라고 하면 web-3, web-4... ) 들만 업데이트.
작은 번호를 갖는 파드들은 업데이트가 되지 않음.
해당 필드는 말 그대로 partition 되는 기준임
spec.updateStrategy.type 필드값을 OnDelete 로 설정하면 스테이트풀 세트의 템플릿이 변경되어도
바로 반영되지 않음.
그럼 언제 적용되느냐? 수동으로 스테이트풀 세트에 속한 파드들을 삭제했을 때(OnDelete)
새로운 설정이 있는 파드가 실행됨.
< 잡 >
잡은 실행된 후 종료해야 하는 성격의 작업 실행시 사용함
특정 개수만큼의 파드를 정상적으로 실행하고 종료함을 보장
잡이 파드 하나를 실행하고 파드가 정상적으로 종료됐는지 확인하는 상황에서 잡을 사용
실행 도중에 파드가 실행에 실패하거나 하드웨어 장애가 발생하거나 노드가 재시작 하는 등의
문제가 발생하면 다시 파드를 실행함.
잡 하나가 파드를 여러 개 실행할 수도 있음
자세한 내용은 나중에 다시 공부하기로 하고 일단 넘어감
< 서비스 >
지금까지 쿠베 클러스터 안에 컨트롤러를 이용하여 파드를 실행하는 방법을 익힘
지금부터는 해당 파드에 접근하는 방법을 알아봄.
파드는 컨트롤러가 관리함. 따라서 한군데에 고정해서 실행되지 않고 클러스터 안을 옮겨다님.
파드는 노드를 옮기면서 실행되기도 하고 클러스터 안 파드의 IP 가 변경되기도 함
이렇게 동적으로 변하는 파드들에 고정적으로 접근할 때 사용하는 방법이 바로 쿠버네티스의 서비스임.
서비스를 사용하면 파드가 클러스터 안의 어디에 있든 고정 주소를 이용해 접근 가능
클러스터 외부에서 클러스터 안의 파드에 접근할 수도 있음

그림을 보면 파드가 옮겨지면서 IP 가 192.168.10.10 > 192.168.10.11 로 변함
하지만 사용자는 서비스를 사용하고 있기 때문에 IP 가 변한 것과 상관 없이 파드에 접근이 가능함
서비스는 여러 파드에 접근 가능한 IP 하나를 제공
서비스는 본질적으로 로드밸런서 역할을 함
서비스는 4가지 타입을 갖고 있음
- ClusterIP : 서비스의 기본 타입. 쿠버네티스 클러스터 안에서만 사용 가능
클러스터 안 노드나 파드에서 ClusterIP 를 이용하여 서비스에 연결된 파드에 접근
하지만 클러스터 외부에서는 접근이 불가
- NodePort : 서비스 하나에 모든 노드의 지정된 포트를 할당
node1:8080, node2:8080 처럼 '노드 상관없이' 서비스에 지정된 포트 번호(여기선 8080)만 사용하면 파드에 접근 가능
노드의 포트를 사용하기 때문에 클러스터 안 뿐 아니라 클러스터 외부에서도 접근 가능
재밌는 것은, 파드가 node1 에서만 실행되어 있고 node2 에서는 실행되지 않더라도
node2:8080 으로 접근하면 알아서 node1:8080 의 파드로 연결한다는 것
클러스터 외부에서 클러스터 안 파드로 접근할 때 사용하는 가장 간단한 방법
- LoadBalancer : AWS, GCP 같은 클라우드 서비스 내의, 쿠버네티스를 지원하는 로드밸런서 장비에서 사용
클라우드 서비스의 로드밸런서와 파드 연결 후 해당 로드밸런서의 IP 이용하여 클러스터 외부에서 파드에 접근 할 수 있도록 함.
- ExternalName : 서비스를 spec.externalName 필드값과 연결함
클러스터 안에서 외부에 접근할 때 사용
아래는 서비스의 기본적인 템플릿 yaml 파일 구조임

1) spec.type 에 서비스 타입을 적음. default 는 ClusterIP
2) spec.ClusterIP : ClusterIP 값을 직접 설정 가능. 적지 않으면 자동으로 IP 값이 할당됨.
이 IP 값은 서비스의 IP 임. ClusterIP 를 이용하여 서비스에 접근함. 아래 이미지 보면 이해가 됨
3) spec.selector : 서비스와 연결할 파드에 설정한 labels 필드 값을 설정.
이 selector 와 동일한 파드에 해당 서비스가 연결!
4) spec.ports[] : 배열 형태임. 서비스에서 한꺼번에 포트 여러개를 외부에 제공할 때는 spec.ports[] 하위에 필드 값을 설정하면 됨.
여기서 port 는 서비스 IP 에 접근할 때 사용함. 위의 yaml 기준으로 서비스에 접근하려면 10.0.10.10:80 사용
targetPort 는 서비스와 연결된 Pods 에서 사용하는 포드 번호.
사용자는 10.0.10.10:80(서비스)으로 접근하지만, 서비스에 의해 실직적으로 [Pod IP]:9376 으로 접근(라우팅)하게 된다.

위의 이미지를 이용한 예를 하나 들어봄
나는 디플로이먼트를 이용하여 파드를 2개 생성함
2개 파드는, port는 80이고 labels.app=nginx-for-svc 라고 정의함
서비스도 하나 생성함. 각 파드의 IP 는 10.1.1.196, 10.1.1.197 임
이 서비스는 spec.type=ClusterIP 이고 selector.app=nginx-for-svc, spec.ports[].port=80, spec.ports[].targetPort=80 으로 정의함
이 서비스의 ClusterIP 는 10.105.216.244 이고 ,이 서비스는 selector 의 labels 를 갖는 파드에 연결됨.
즉 위에서 생성한 두 개의 파드에 연결됨
이 서비스는 ClusterIP 타입이기 때문에 클러스터 내에서만 접근 가능하므로,
nicolaka/netshoot 이라는 파드를 하나 만들어서 서비스의 ClusterIP(10.105.216.244) 로 접근해 봄
접근이 잘 됨. curl 10.105.216.244 이라고 명령을 내리면, 서비스를 통해 두 개의 파드에 접근하게 되고 html 마크업을 출력하게 됨
두 개의 파드 중 어떤 것에 접근했을까?
서비스가 Pod들에 부하를 분산할때 디폴트 알고리즘은 Pod 간에 랜덤으로 부하를 분산하도록 한다고 함
만약에 특정 클라이언트가 특정 Pod로 지속적으로 연결이 되게 하려면
Session Affinity를 사용하면 되는데, 서비스의 spec 부분에 sessionAffinity: ClientIP로 주면 된다고 함
위에 이미지에서 오른쪽 사용자는 외부에서 접근하려고 하지만 서비스가 ClusterIP 타입이기 때문에 접근이 불가
만약 NodePort 타입이었으면 접근 가능한 NodePort 번호가 생성되어 외부에서도 접근이 가능해지게 됨.
아래 그림처럼.

위의 그림은 [서비스의 IP]:[NodePort 번호]를 사용하여 외부에서 서비스에 접근하는 모습을 보여줌.
조대협님 블로그에 따르면, 저 NodePort 라는 것은 Pod 에도 붙는 Port Number 라고 함.
예를 들어 아래와 같은 yaml 파일로 실행했을 때
apiVersion: v1
kind: Service
metadata:
name: hello-node-svc
spec:
selector:
app: hello-node
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 30036
다음과 같이, 클러스터 내부에서 [서비스 IP]:[port 80] 혹은 [서비스 이름]:[port 80] 으로 서비스에 접근 가능하고,
클러스터 외부에서 [Node IP]:[Node Port 30036] 로 pod 에 직접 접근이 가능하다고 함.
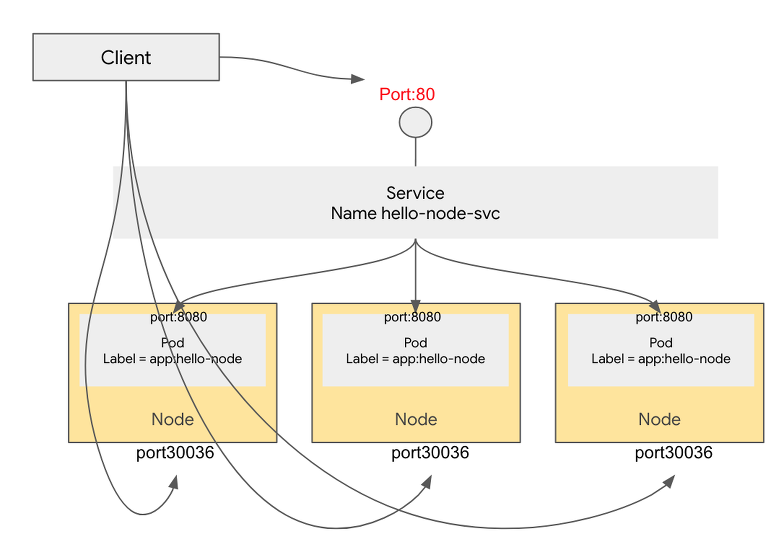
재밌는 것은, pod가 node1에만 떠 있고 node2에는 없다고 하더라도
node2:30036으로 접근하면 node1에 떠 있는 포드로 연결된다고 함
클러스터외부에서 클러스터내부의 pod로 접근할때 사용할 수 있는 가장 간단한 방법이라고.
더 이해하기 쉬운 그림이 아래 있다.
NodePort는 모든 Node에 특정 포트를 열어 두고, 이 포트로 보내지는 모든 트래픽을 서비스로 포워딩한단다.

서비스는 서비스의 selector 와 일치하는 파드와 연결되는데
끈끈하게 연결된다기 보다는 그냥 서비스를 이용할 때 해당 selector 와 일치하는 파드와
그때 그때 연결함
내가 이해하기로, 서비스는 네트워크 통로를 새로 개통하는 것과 같음.
컨테이너 이름이 my-con이고 release 가 각각 a, b, c 인 파드 3개가 있고
selector 의 app:my-con, release:b 인 서비스가 있다고 하자.
사용자는 my-con 컨테이너에 접속이 되는지 보려고 ping 을 날리면
서비스가 먼저 받고(!) 그것을 서비스의 selector 와 일치하는 파드들에게 보냄.
즉 release 가 b 인 파드에게만 보냄.
큰 틀에서 이해하자면 이렇고, 세부적으로 다시 적겠음.
서비스는 기본적으로 쿠버네티스 클러스터 안에서만 접근 가능(왜냐면 기본 서비스 종류가 ClusterIP 라서)
그래서 사용자가 클러스터 바깥에서 (서비스를 통해) 파드에 ping 을 날릴 순 없고
클러스터 내의 temp 파드를 새로 만들어서 거기서 ping 을 날리면
서비스가 먼저 받고 서비스의 selector 와 일치하는 파드들에게 ping 을 보냄.
즉, 어떤 파드에서 다른 파드 그룹으로 접근할 때 서비스를 거쳐 가도록 할 수 있음
< kube-proxy >
나중에 다시 보겠음.
일단 스킵
< 인그레스 >
인그레스는 클러스터 외부에서 안으로 접근하는 요청들을 어떻게 처리할지 정의해둔 규칙 모음
- 클러스터 외부에서 접근해야 할 URL 사용할 수 있도록 함
- 트래픽 로드밸런싱
- SSL 인증서 처리
- 도메인 기반 가상 호스팅
인그레스는 위와 같은 규칙들을 정의해둔 자원
실제로 동작시키는 것은 인그레스 컨트롤러
만약 클라우드 서비스를 사용한다면 자체 로드 밸런서 서비스와 연동하여 인그레스를 사용할 수 있지만,
클라우드 서비스 없이 직접 클러스터 구축했다면 ....ㅠㅠ
인그레스 컨트롤러를 직접 인그레스와 연동해야 함
ingress-nginx 가 가장 많이 사용되는 컨트롤러.
ingress-nginx 컨트롤러는 인그레스에 설정한 내용을 nginx 환경 설정으로 변경하여 nginx 에 적용
외부에서 eyeballs.blog/nifi 혹은 eyeballs.blog/kube 같이 특정 url 로 접근할 때
인그레스가 라우팅을 해 줌.
< 레이블 >
레이블은 키-값 쌍으로 구성됨
사용자가 클러스터 내에 오브젝트를 만들 때, 메타데이터로 설정 가능.
레이블이 생성된 다음에도 언제든지 수정 가능
레이블의 키는 쿠버네티스 안에서 컨트롤러들이 파드를 관리할 때 자신이 관리해야 할 파드를 구분하는 역할.
마치 deployment 가 spec.labels 을 통해 관리할 파드들을 구분짓는 것 처럼!
쿠버네티스는 레이블만으로 관리 대상을 구분
노드에도 레이블을 붙일 수 있음.
그래서 특정 레이블이 있는 노드에만 자원을 할당해 실행하는 것이 가능
"kubernetes.io/" 접두어가 있는 레이블의 키는 쿠버네티스 시스템에서 사용하는 레이블들임.

위의 템플릿은 디플로이먼트 yaml 파일의 일부로 사용된 것임
보면 레이블의 키 app, environment, release 에 각각 nginx, develop, beta 의 값을 갖음
해당 값이 달라지면 디플로이먼트로 생성하는 파드마다 다른 값을 가질 수 있지.
그리고 파드가 생성되면
kubectl get pods -l app=nginx
kubectl get pods -l environment=develop, release=stable
kubectl get pods -l "app=nginx, environment notin (develop)"
처럼 get pods 할 때 레이블들을 필터로 사용할 수 있음.

위와 같은 식으로 annotations 라고, 그냥 메모용?으로 적어두는 것이 있음.
위의 예제에서는 관리자 이름이랑 번호랑 버전을 적어둠.
< 컨피그맵 >
컨피그맵은 컨테이너에 필요한 환경 설정을 컨테이너와 분리하여 제공하는 기능
개발 컨테이너와 상용 컨테이너 설정을 다르게 해야 할 때가 많음.
사용하는 DB나 로깅 레벨 등이 다를 수 있음
이렇게 다른 설정으로 컨테이너를 실행해야 할 때 사용하는 것이 컨피그맵
컨피그맵을 컨테이너와 분리하면 컨테이너 하나를 개발용, 사용 전 테스트용, 상용 서비스용으로 사용 가능
컨피그맵 템플릿 yaml 파일 살펴보자
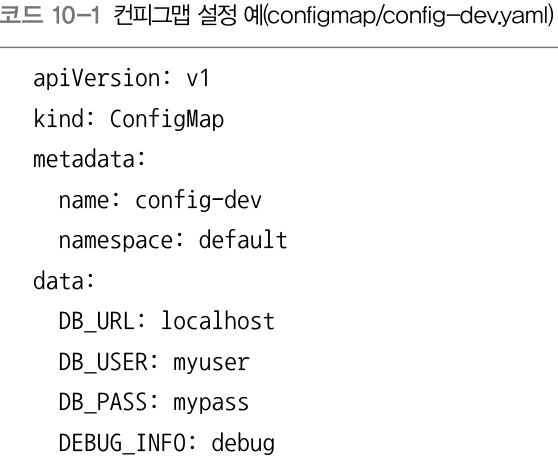
data 의 하위 필드에는 사용하려는 환경 설정값을 넣음.
이 예제에선 DB 환경 변수값들을 넣음(DB_URL, DB_USER, DB_PASS, DEBUG_INFO)
이 컨피그맵을 컨테이너 적용할 때
- 컨피그맵 설정 중 일부만 불러와서 사용
- 컨피그맵 설정 전체를 한번에 불러와서 사용
- 컨피그맵을 볼륨에 불러와서 사용
하는 방법들이 있음
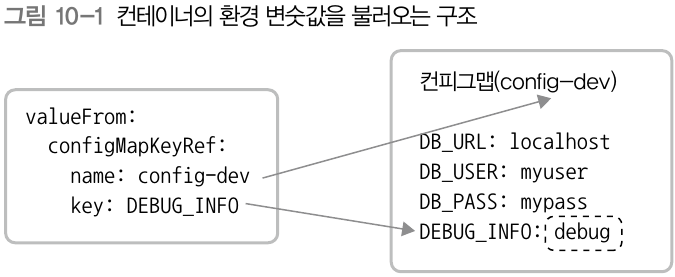
아래는 디플로이먼트 yaml 파일에서 위의 컨피그맵의 DEBUG_INFO 정보만 가져와서 사용하는 것을 보여줌

name 에는 컨피그맵의 metadata.name 이 들어갔고
key 에는 컨피그맵의 data 가 들어갔음.
위와 같이 하면, 해당 디플로이먼트의 DEBUG_LEVEL(env.name 부분) 은 컨피그맵에서 가져온 debug 가 될 것임.
컨피그맵 전체를 가져올 땐 다음과 같이 하면 됨.


참고로 이미 컨피그맵의 값을 디플로이먼트 등에서 불러왔다고 하더라도,
컨피그맵의 값을 수정한 후 apply 하면 디플로이먼트에도 수정한 값이 적용됨
'Docker' 카테고리의 다른 글
| [Docker] Ubuntu 에 Docker 설치하는 방법 (0) | 2020.11.12 |
|---|---|
| [Docker] Kubernetes 공부 Part 3 필기 (0) | 2020.11.10 |
| [Docker] Container 내부에서 host ip 찾는 방법 (0) | 2020.11.03 |
| [Docker] DC/OS vs Kubernetes 비교 (0) | 2020.10.29 |
| [Kubernetes] 기본 설명 링크 (0) | 2020.09.16 |