공부한 내용이라 틀린 점이 있을 수 있습니다.
틀린 점을 지적해주시면 감사하겠습니다.
이레이저 코딩은 이레이저 코드(Erasure Code)를 이용하여 데이터를 인코딩하고, 데이터 손실시 디코딩 과정을 거쳐 원본 데이터를 복구하는 데이터 복구 기법중 하나
HDFS 가 갖는 장점 중 하나인 fault-tolerance 는 하나의 파일을 이루는 N 개의 블록을 복제하여(기본 3개) 나눠 저장하므로 나타나는데, 이 때 저장 용량을 3배 차지하는 것이 단점.
하둡 3.x 버전에서는 이를 RAID(Redundant Array of Inexpensive Disks)에서 주로 사용하는 Reed-Solomon 알고리즘( 외에 Tahoe-LAFS, Weaver Code 등의 알고리즘)을 사용한 ‘Erasure Coding’이라는 방법으로 개선.
Erasure Coding은 하나의 파일을 n개 블록으로 나누면서, n보다 작거나 같은 k개의 Parity 블록을 생성하여 Fault-tolerance를 보장하는 방식. 결과적으로 n+k 만큼의 적은 용량만 차지하게 됨. 파일이 나눠진 블록 n개와 이에 해당하는 패리티 블록 k 개가 여러 디스크에 임의 분산 저장됨.
기존의 a 개만큼 복제하는 전략대로라면, a-1 개의 블록 장애까지 대응이 가능. 하지만 Erasure Coding 을 하면, 최대 패리티 블록 개수인 k 개의 블록 장애까지만 대응이 가능
XOR 를 사용하는 EC 와 Reed-Solomon 을 사용하는 EC 로 나눌 수 있는데
XOR 는 단 하나의 패리티 블록을 만들 수 밖에 없기에 결함 허용수가 1이다.
Reed-Solomon 은 k 개 패리티 블록 개수만큼 결함을 허용한다.
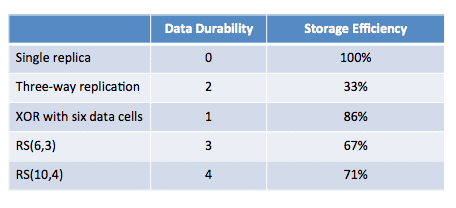
스토리지 효율성은 데이터 블록 개수 n과 복구를 위한 패리티 블록 개수 k 의 비율로 나타낼 수 있다.
스토리지 효율성 = n / (n + k)
예를 들어 데이터 블럭 개수가 6이고 패리티블럭 개수가 3이라면
6/(6+3) = 0.666...% = 0.67%
Data Locality 적용이 안 됨. 하지만 10Gbps 이상의 네트워크 환경 하에선 크게 문제되지 않음.
메모리 기반으로 동작하는 Spark 의 경우 데이터 지역성에 크게 영향을 받지 않음.
data locality 이득을 전혀 볼 수 없기 때문에, 네트워크 환경이 좋은 곳에서 최적의 성능을 낸다고 함.
실제로 여기를 보면, EC(Erasure Coding) 가 data locality 이득을 보는 replication 보다 성능이 좋음.
데이터 지역성이 크지 않으니 데이터를 읽기 위해 네트워크 비용을 소모하여 remote read 를 해야 하는가? 그렇다.
에러 정정 코드를 추가 저장하여, 장애가 났을 때 복구함.
따라서 Erasure Coding 은 데이터를 복구하는 용도(데이터 백업은 아님)
EC 를 사용하면, 복잡성이 추가되고 장애 복구 비용이 더 많이 든다.
Erasure Coding 을 하기 위해 인코딩(복구 데이터 생성시)/디코딩(데이터 복구시)이 필요하고,
이를 위해 CPU 를 사용하게 되므로 성능 오버헤드가 생길 수 있지만,
이것은 Intel 에서 ISA-L 이라는 가속 명령어를 통해 빠르게 처리하여 해결할 수 있다고 함.
‘이레이저’ 라는 말의 의미 : 이레이저 코딩은 데이터 코드 삭제를 위한 기술이 아님.
삭제된(더 이상 접근이 불가능한) 데이터의 규모 및 범위를 파악하여 중복된 영역의 삭제된 블록을 복구 하는 데이터 보호 기술
In case of a failure aka erasure, the data can be reconstructed from this encoding group, known as decoding.
EC의 원리를 이해하려고 봤더니 reed-solomon 알고리즘을 이해해야 함.
이 알고리즘 너무 어려움ㅠㅠ
<replica>
내구성 : 결함 n-1 개까지 허용
스토리지 효율성 : 200% 추가 공간 필요
<ec>
내구성 : 결함 k 패리티비트 개수까지 허용
스토리지 효율성 : 패리티비트의 추가 공간 필요
XOR 방식을 통해 ec 가능
패리티비트는 1개밖에 못 만듦.
따라서 1개의 결함까지만 허용
Reed-Solomon 방식을 통해 ec 가능
데이터 k 개수와 패리티비트 m 개수의 비율로
스토리지 효율성이 결정됨.
스토리지 효율성 = k / (k+m)
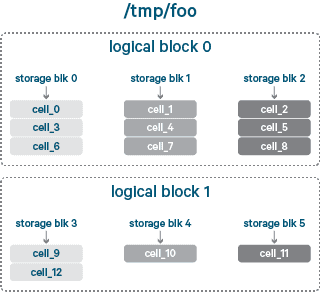
HDFS 에 128mb 단위로 나뉘어져있는 블록이 storage block. 우리가 원래 알고 있는 것.
storage block 들을 논리적으로 나눈 블록이 logical block.
logical block 과 storage block 을 매핑한 것을 contiguous block layout 라고 함.
아래 그림에서 block 0,1,2를 logical block 0 으로 묶었고, block 3,4,5를 logical block 1 로 묶음.
Striped block layout 은 논리적 블럭을 cell 이라고 부르는 작은 storage unit 단위로 쪼갠다.
그리고 storage block 을 round robin 방식으로 반복하여 저장한다.
아래 그림을 보면 logical block 단위로 각 storage block 들을 순회하면서
차례대로 cell0, 1, 2, 3... 이렇게 나누고 있는 것을 볼 수 있음.
< 공부한 내용 >
HDFS에 데이터가 들어오면 128mb 기준으로 데이터가 잘려 저장됩니다.
이 블럭들을 storage blocks 라고 부릅니다.
(RS6-3-1024k 정책을 기준으로) storage blocks 6개를 하나의 그룹으로 묶는데
이 그룹이 logical blocks 입니다.
Contiguous Layout 을 사용하면
6개의 storage blocks 로 구성된 하나의 logical block 을 기준으로
3개의 패리티블럭이 추가로 생성되어 각 DataNode 에 저장됩니다.
(이 경우 패리티 블럭 하나 크기는 storage block 크기(128mb), 총 128mb*3 이 되는 듯)
Striped Layout 을 사용하면 각 logical block 내의 storage blocks 들을
1024kb 단위로 round-robin 방식으로 자릅니다.
잘린 cell 들 6개를 기준으로 3개의 parity block 을 생성하여 각 DN 에 저장합니다.
(이 경우 parity block 하나 크기는 1024kb, 총 1024kb*3 이 되는듯)
Contiguous block layout 를 사용하면 (예를 들어 10-4 정책의 경우) 데이터블록이 10개든 1개든
parity 블럭은 4개(4*128mb)가 된다고 합니다. (링크)
이 말은 (위에 제가 공부한 내용처럼) contiguous block group 이
(최소) 1개에서 (최대) 10개의 storage blocks 를 갖고있는데
storage blocks 가 최소 1개든 최대 10개든 상관없이
하나의 storage block 기반으로 parity block 이 4개(128mb*4) 만들어진다라고 이해하면 될 듯 합니다.
예를 들어 1gb 데이터를 기준으로 replica 와 ec 6-3 정책을 비교해보면 다음과 같습니다.


1gb 는 128mb 블럭 8개로 구성되는데,
그 중에서 6개의 블럭을 기준(logical block)으로 3개의 패리티블럭이 생성됩니다.
(DataBlock: 6, ParityBlock: 3)
남은 2개의 블럭을 기준으로 3개의 패리티 블럭이 생성됩니다.
(따라서 3개의 블럭을 잃는다고 하여도 나머지 블럭들을 이용하여 복구가 가능합니다)
위에 설명 중,
10-4 정책에서, Contiguous block layout 를 사용하면 데이터블록이 10개든 1개든
parity 블럭은 4개(4*128mb)가 된다 라는 의미 역시 마찬가지입니다.
10개의 블럭을 기준(logical block)으로 4개의 패리티 블럭이 생성되는데
블럭 개수가 10개로 나눠 떨어지지 않을 때 생기는 10개 이하의 데이터 블럭에 대해서도
마찬가지로 4개의 패리티 블럭이 생성됩니다.
2.8gb 데이터를 3-2 정책 기준으로 HDFS 에 업로드 한 뒤 fsck 로 확인해보면 다음과 같은 결과를 볼 수 있습니다.
| 정상적으로 3-2 정책으로 쓴 데이터를 fsck 를 통해 확인해보면 다음과 같은 결과가 나옵니다. Status: HEALTHY Number of data-nodes: 6 Number of racks: 1 Total dirs: 0 Total symlinks: 0 Replicated Blocks: Total size: 0 B Total files: 0 Total blocks (validated): 0 Minimally replicated blocks: 0 Over-replicated blocks: 0 Under-replicated blocks: 0 Mis-replicated blocks: 0 Default replication factor: 3 Average block replication: 0.0 Missing blocks: 0 Corrupt blocks: 0 Missing replicas: 0 Erasure Coded Block Groups: Total size: 2841660403 B Total files: 1 Total block groups (validated): 8 (avg. block group size 355207550 B) Minimally erasure-coded block groups: 8 (100.0 %) Over-erasure-coded block groups: 0 (0.0 %) Under-erasure-coded block groups: 0 (0.0 %) Unsatisfactory placement block groups: 0 (0.0 %) Average block group size: 5.0 Missing block groups: 0 Corrupt block groups: 0 Missing internal blocks: 0 (0.0 %) FSCK ended at Sun Aug 23 10:08:05 KST 2020 in 2 milliseconds |
중간에 total block groups 이 8이 나온 이유는,
logical block 하나 크기 = storage block(128) * 3 = 약 380 mb
전체 데이터 2.8gb / 380mb = 대략 8
6-3 정책의 경우 fsck 로 확인하면 4개 블럭 그룹이 나오는데,
이 역시
logical block 하나 크기 = storage block(128) * 6 = 약 760 mb
전체 데이터 2.8gb / 760mb = 대략 4
또한 ec 정책을 적용하여 HDFS 에 저장했을 때
데이터블럭과 (생성된) 패리티 블럭의 크기 모두를 구하는 방법을 따로 찾지 못하여
(위에 fsck 명령어도 보면 알겠지만 데이터 블럭 크기만 보여주고 패리티 블럭 크기는 보여주지 않음)
hdfs dfs -df 명령어를 사용하여
HDFS에 데이터를 저장하지 않았을 때 크기와
HDFS에 ec 정책을 적용한 데이터를 저장했을 때 크기를 비교했습니다.
전체 데이터 공간이 얼마나 줄었는지를 보고 데이터블럭과 패리티블럭 크기를 측정하였습니다.
그 밖에 EC 관련 조사한 자료를 pdf 로 올렸습니다.
작은 크기의 데이터에 대해 블럭 개수가 늘어난다는 내용에 대해서는 여기 링크 아래쪽에
File Size and Block Size 부분을 읽어보세요.
* 추가
6-3-1024K 의 의미 : 데이터를 1024kb 로 자른 것을 6개로 나눠 저장. 또 3개로 나눠 패리티비트를 저장. 총 9개의 노드에 6개, 3개를 나눠 저장하는 것이 필요.
RS : read solution
자세한 설명
https://blog.cloudera.com/introduction-to-hdfs-erasure-coding-in-apache-hadoop/
https://towardsdatascience.com/simplifying-hdfs-erasure-coding-9d9588975113
https://www.backblaze.com/blog/reed-solomon/
https://www.samsungsds.com/global/ko/support/insights/Hadoop3-coding.html
https://www.popit.kr/hadoop-3-0%EA%B3%BC-erasure-coding-%ED%8E%B8%EC%A7%91%EC%A6%9D/
https://clouderatemp.wpengine.com/blog/2015/09/introduction-to-hdfs-erasure-coding-in-apache-hadoop/
https://www.idata.co.il/2019/01/hadoop-3-erasure-coding-examined/
기본적인 설명
https://blog.knoldus.com/hdfs-erasure-coding-hadoop-3-0/
https://www.intel.com/content/www/us/en/products/docs/storage/erasure-code-isa-l-solution-video.html
https://www.youtube.com/watch?v=CryhjBWQHvM
https://dzone.com/articles/hdfs-erasure-coding-in-hadoop-30
적용 방법
https://heum-story.tistory.com/110
성능 테스트
https://blog.cloudera.com/hdfs-erasure-coding-in-production/ (영어)
https://joonyon.tistory.com/67 (한글)
reed solomon 알고리즘에 대한 대략적인 설명
'Hadoop' 카테고리의 다른 글
| [Hadoop] 기술 질문 대비 적어두는 것들 (0) | 2020.07.15 |
|---|---|
| [Hadoop3] 버전 2 vs 버전 3 새로운 기능 설명 및 링크 (0) | 2020.07.15 |
| [Hadoop] 네이버의 멀티테넌트 하둡 클러스터 운영 경험기 (0) | 2020.07.14 |
| [ZooKeeper] 간단한 설명 및 참고 링크 (0) | 2020.07.14 |
| [Hadoop3] CentOS 위에서 HA Hadoop Cluster 설치 방법 (0) | 2020.07.14 |