간혹 Spark 를 사용하다 보면 bianry 라는 데이터 포맷을 읽게 되는 경우가 있다.
가령 아래 df 는 field0 column이 "binary" 라는 형태를 보인다.
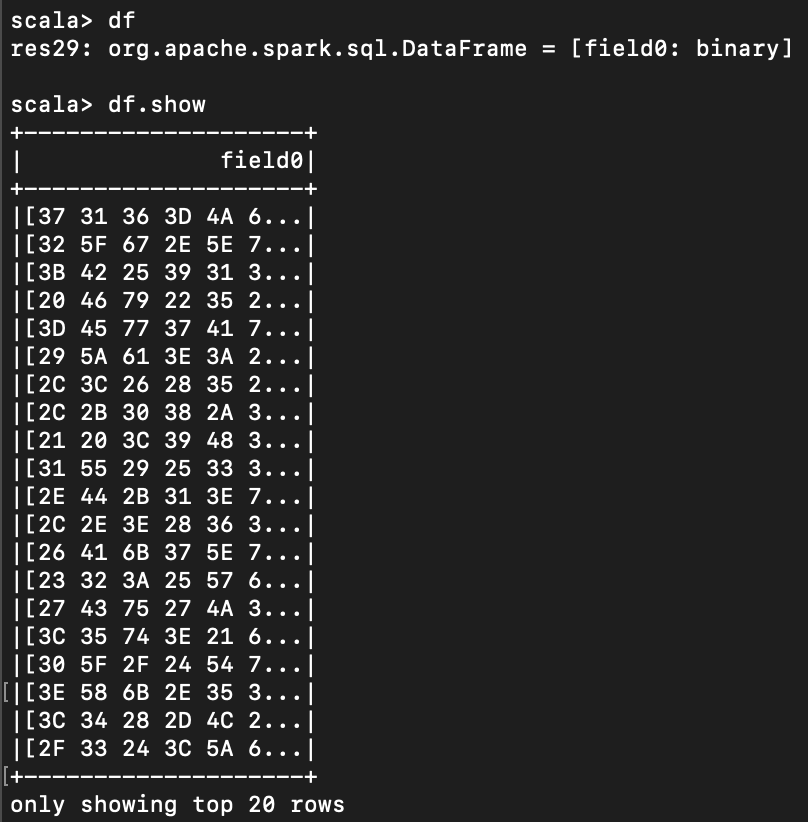
이 값을 읽으려면 아래처럼 udf 를 만들면 된다.
|
import org.apache.spark.sql.functions.udf
val toStr = udf((payload: Array[Byte]) => new String(payload))
|


새로 들어간 "str" column 이 왼쪽 filed0 를 parsing 한 것.
참고
'Spark' 카테고리의 다른 글
| [Spark] executor 개수 늘리는 방법 (0) | 2020.02.15 |
|---|---|
| [Spark] MongoDB connector for Apache Spark 웨비나 링크 (0) | 2020.02.05 |
| [AWS] amazon linux 에 scala, sbt 설치하는 방법 (0) | 2020.01.20 |
| [Spark] Dataframe csv 로 export 하기 (0) | 2020.01.18 |
| [Spark] take 한 값을 일일이 출력하고 싶을 때 (0) | 2020.01.03 |