읽기 전에
* Hadoop HDFS Cluster 와 Spark Cluster 가 이미 설치되어있다는 전제 하에 아래 내용을 설명한다.
* HBase 와 Zookeeper 가 이미 실행중이라는 전제 하에 아래 내용을 설명한다.
내가 실행한 환경
- Ubuntu 16.04
- Spark 2.4.0
- Hadoop 3.1.1 Cluster Node 2개 (master 1개, slave 1개)
- Scala 2.11.12
- HBase 1.4.10
- Zookeeper 3.5.6
아래 절차를 따르기 전에 이미 HDFS, HBase, Zookeeper 가 실행중이어야 한다.
Master 와 Slave 서버에서 jps 로 현제 실행 중인지 데몬 목록으로 확인해본다.
Master 에서는 HMaster, Slave 서버에서는 HRegionServer 가 실행중이어야 한다.
| < Master 서버에서 jps > | < Slave 서버에서 jps > |
 |
 |
Spark 와 연동하는 방법은 총 세 가지가 있다.
1. Hortenworks Spark HBase Connector(SHC) 를 사용하는 방법 (git)
2. nerdammer Spark Hbase Connector 를 사용하는 방법 (git)
3. Apache HBase Spark Connector 를 사용하는 방법 (git)
여기 포스트에서는 apache 에서 직접 제공하는 세번째 방법을 사용한다.
각자 어떤 connecotr 를 사용할 것인지는 아래 링크들을 참고한다.
1.
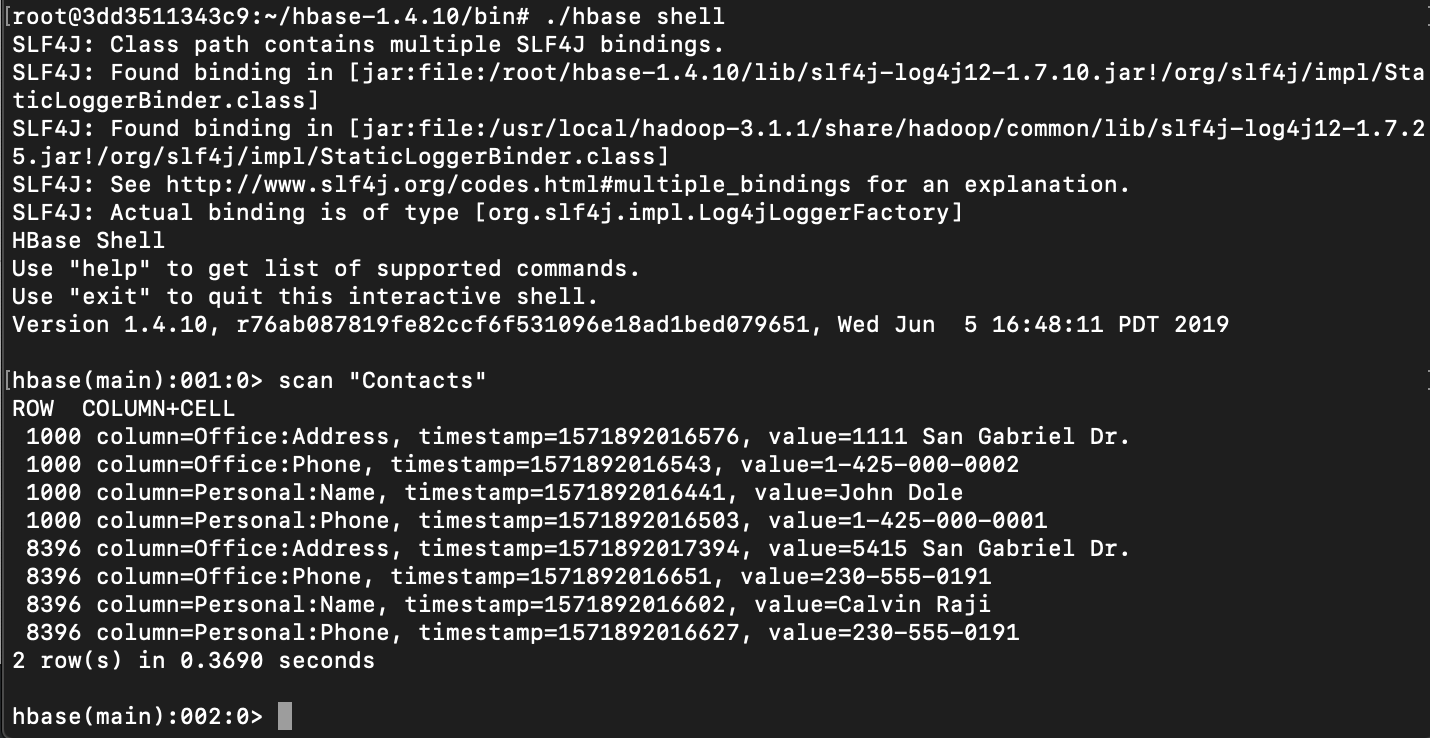
먼저 HBase 에 데이터를 넣는다.
HBase/bin 으로 가서 ./hbase shell 로 hbase shell 에 접속한 후에 아래 put 명령어를 넣는다.
|
create 'Contacts', 'Personal', 'Office'
|
scan "Contacts" 로 잘 들어갔는지 확인
2.
아래 명령으로 Spark shell 에 접속한다.
| spark-shell --master yarn --jars "/root/hbase-1.4.10/lib/*.jar" |
위에 /root/hbase-1.4.10/lib 는 내가 hbase 를 설치한 경로이기 때문에 바로 복붙하면 에러가 날 것이다.
각자 hbase 를 설치한 경로를 찾아서 lib 내의 모든 jar (*.jar) 를 옵션에 넣자.

3.
아래 코드를 넣어본다.
|
import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.hbase.client.Scan;
val conf = HBaseConfiguration.create() val conn = ConnectionFactory.createConnection(conf) val admin = conn.getAdmin() //여기 예제에서는 admin 은 사용하지 않지만, "이렇게 admin 을 얻는다" 고 참고 삼아 넣어둠. val table = conn.getTable(TableName.valueOf("Contacts"))
//Get example. row key 가 8396 인 것만 가져온다. val get = new Get(Bytes.toBytes("8396")) val result = table.get(get) println(result)
//Scan example. Contacts 테이블의 모든 row 를 Scan 하여 iterator 로 뽑아온다. val scan = table.getScanner(new Scan()) val itr = scan.iterator println(itr.next)
|




|
< 범위 scan > val scan = new Scan()
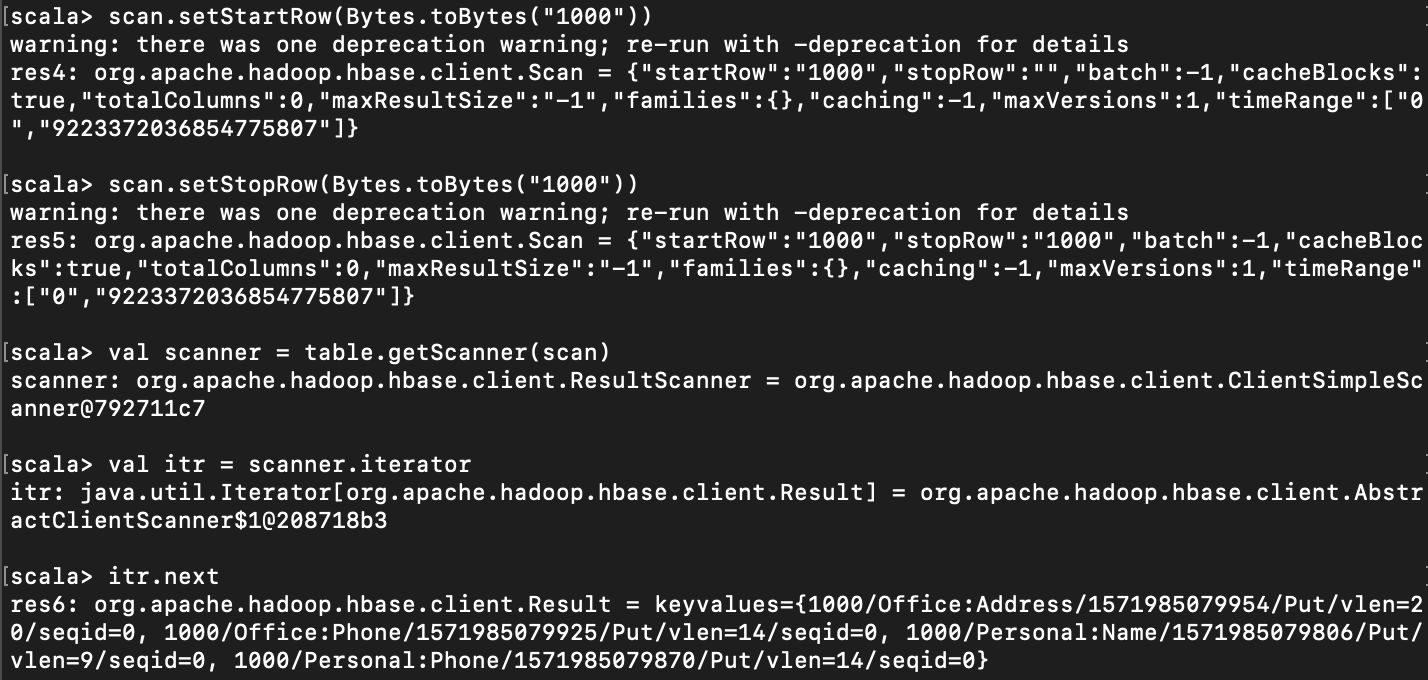 |
여기 포스트에서는 read 하는 것만 소개한다.
write 외에 creat table, delete 등의 쿼리를 보내는 명령어들은 차후에 업데이트 하기로 한다.
공식 github 내의 코드에 좋은 예제들이 많으니 응용해서 사용할 수 있겠다.
이 youtube 비디오 에서 insert, read, update, delete 명령어를 어떻게 사용하는지 실제 예제로 볼 수 있다.
Spark 의 RDD 를 사용하려면 HBaseContext 를 사용해야 한다.
여기에서 jar 를 받아 --jars 옵션에 넣어 사용하면 HBaseContext 를 사용할 수 있다.
HBaseContext 를 import 할 때
"Symbol term org.apache.yetus is missing from the classpath."
에러가 난다면,
HBase 가 설치된 곳 $HBASE_HOME/lib/client-facing-thirdparty 에 있는 audience-annotations-*.jar 를
spark 가 설치된 곳 $SPARK_HOME/jars/ 로 옮긴다.
여기 HBase book 참고.
API 사용 방법은 여기 참고
잡담
git을 보면 shc 가 가장 많은 star 를 갖고 있는 걸 볼 수 있다.
shc 은 hbase 의 데이터를 dataframes 나 datasets 로 바로 갖고 올 수 있고 또
2,3번 connector 보다 훨씬 많은 인기를 누리고 있기 때문에
나는 처음에 shc 를 이용하여 hbase 와 spark 를 연동시키려고 하였다....
....... 그렇게 삽질을 했더랬다.
shc 는 dependencies 와 version 맞추는 문제가 너무 크기 때문에 손보기가 정말 까다롭다.
왜 이렇게 만들어두었는지 모르겠다.
참고로 Hortenworks Connector 를 구글링 하다보면 Cloudera 가 많이 등장하는데, 왜냐하면 두 회사가 합병했기 때문이다. 따라서 Hortenworks 시절에 만든 blog 나 article 에 나온 code 들은 오래되었고 업데이트가 되지 않았기 때문에, 동작하지 않을 수 있다.
참고한 곳들
https://hbase.apache.org/book.html#spark
https://sparkbyexamples.com/hbase/spark-hbase-connectors-which-one-to-use
https://stackoverflow.com/a/38220562/5868252
https://www.programcreek.com/scala/org.apache.hadoop.hbase.TableName
https://gist.github.com/ishassan/c4d5770f4163e13a3e5a9b072e18ce7d#file-scalahbaseexample-scala
http://khodeprasad.ml/blog/read-records-from-hbase-table-using-java/
https://www.quora.com/How-do-I-integrate-HBase-on-Spark
https://acadgild.com/blog/apache-spark-hbase
https://dzone.com/articles/spark-streaming-1
'HBase' 카테고리의 다른 글
| [HBase] Spark 와 연동해서 데이터 읽는 방법 - hortonworks shc (0) | 2019.11.01 |
|---|---|
| [HBase] log 보는 방법 (0) | 2019.10.31 |
| [HBase] 기본 개념 (0) | 2019.10.21 |
| [HBase] linux 에 Fully Distributed mode 설치하는 방법 (0) | 2019.10.21 |
| [HBase] Zookeeper 설치하는 방법 (0) | 2019.10.18 |