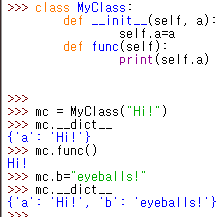
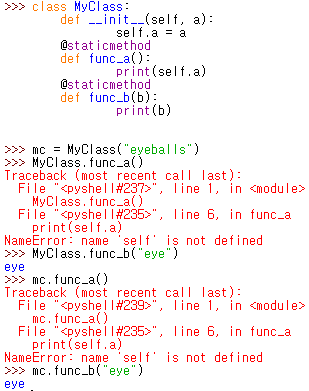
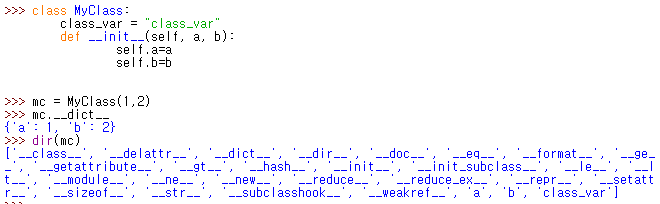
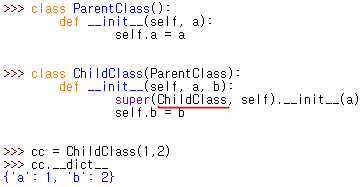
Gradle 은 application 의 빌드와 배포 문제를 해결하기 위한 framework 임 Java 의 경우, java class files, doc files, XML files, property files, 그 외 resources 등 하나의 프로젝트(application)에 굉장히 다양한 파일들을 담고 있음 게다가 각 프로젝트마다 각기 다른 구조 및 버전을 갖고 있어서 빌드하기가 굉장히 까다로움 Gradle 이 이러한 문제 해결에 도움을 줌
Gradle 이 하는 것 - 프로젝트 빌드하고 배포 - 의존성 관리
Gradle 이 사용하는 build file 의 default 명은 "build.gradle"
Gradle 은 Domain-Specific Language (DSL) 을 정의함 (DSL : 어떤 도메인에서 특정 목적만을 달성하기 위해 사용되는 언어) 예를 들어 프로젝트는 Java 지만, build.gradle 은 Groovy 나 Kotlin 으로 쓰여질 수 있음
Gradle 이 진행하는 작업 단위 하나하나를 "task" 라고 부름 build.gradle 파일을 파싱해서 task 를 뽑아내고 작업을 진행함
task 들은 DAG 를 구성함. 따라서 모든 task 는 실행의 순서가 있으며 반복 실행되지 않음
먼저 실행된 task 의 output 이 나중에 실행된 task 의 input 이 되기도 함
Gradle 은 각 task 의 output 을 저장함 어떤 task 의 input 및 output 이 동일하다면, 다음에 동작할 때 해당 task 는 실행하지 않음으로써 리소스를 아낄 수 있음
Gradle 은 자기 자신을 자동으로 업데이트 할 수 있음 Gradle 은 의존성을 야기하는 lib 들 또한 자동으로 업데이트 할 수 있음
Gradle 의 핵심 구조는 다음과 같음
- Project : 소프트웨어 요소들의 능력(?) 이나 범위를 정의 - build script : "build.gradle". build 하기 위한 지시사항들(task)을 갖추고 있음 - task : 실질적인 작업 사항
hello world 를 프린트하는 굉장히 간단한 build.gradle 예제 (Groovy)
kubectl apply -f=users-deployment.yaml 명령어로 kube 위에 pod 를 띄움
그리고 kubectl get pods, kubectl get deployments 로 pods , deployments 가 잘 떴는지 확인
users API 앱이 올라온 뒤
외부 세계(즉 Client) 에서 Users API 에 접근할 수 있도록
Service 를 추가로 설정해야 함
Service 를 설정하여 Service 의 두 가지 기능을 사용
- Service 는 항상 변경되지 않는 안정적이고 고정된 주소를 제공
(Pod 자체가 default IP (ClusterIP) 를 갖고 있긴 하지만, Pod 가 재실행되면 바뀌게 됨)
- Service 는 외부 세계에서 pod 내부 앱으로의 접근을 허용하도록 구성 가능케 함
Service 추가를 위해 Service yaml 파일을 새로 생성
이름은 users-service.yaml
< users-service.yaml >
apiVersion: v1 kind: Service metadata: name: users-service spec: selector: app: users #위 deployment 에서 생성한 모든 users pods 에 service 를 할당함 type: LoadBalancer #외부 세계에서 접근 가능한 ip 를 제공하는 유일한 type ports: - protocol: TCP port: 8080 # 외부 세계에서 접근 가능한 포트 targetPort: 8080 #내부 앱에서 받는 포트
아래 명령어를 사용하여 service yaml 를 kube 에 띄움
kubectl apply -f=users-service.yaml
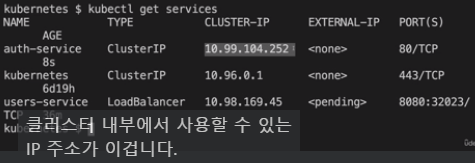
그 후 kubectl get services 로 제대로 떴는지 확인
만약 Cloud Provider 를 이용하여 Service 를 띄웠다면
Cloud Provider 에서 제공하는 Service 의 IP를 얻을 수 있지만,
강의에서는 minikube 를 사용하기 때문에
아래 명령어를 사용하여 Service 의 IP 를 확인
minikube service users-service
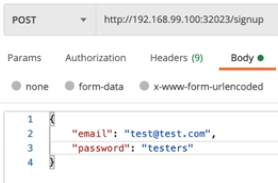
위 스샷에서 보이는 것처럼 192.168.99.100:32023 이 Service 가 제공하는 IP 같은데...
yaml 에 넣어준 8080은 앞에 따로 표기되어있음
32023 은 무슨 의미지(????)
게다가 실제로 IP 에 접근할 때 8080 대신 32023 을 사용하고 있음
8080 은 왜 넣은거야 (???)
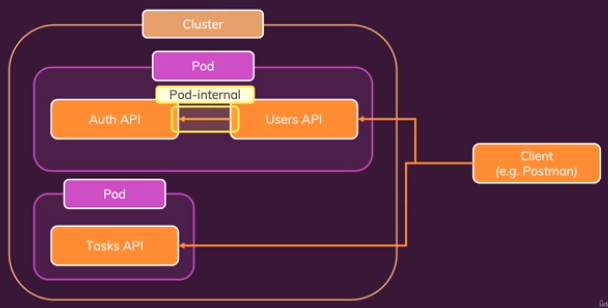
가장 위의 아키텍처에서 설명했듯이,
하나의 Pod 내에 두 가지 UserAPI Container, AuthAPI Container두 개를 각각 띄우려고 함
apiVersion: v1 kind: Service metadata: name: auth-service spec: selector: app: auth type: ClusterIP # pod 주소 고정 및 Load Balancer 역할을 해주지만 외부 세계로 노출은 막아주는 타입. 오직 Cluster 내부 세계로부터만 auth pod 에 접근 가능하게 됨 ports: - protocol: TCP port: 80 targetPort: 80
위와 같이 ClusterIP 타입을 사용하는 auth service 를 만들고
kubectl apply 명령 진행하고 kubectl get services 로 확인하면
ClusterIP 타입 Service 가 제공하는 (Cluster 내부에서만 사용 가능한) IP 를 확인 가능
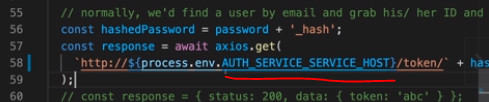
그리고 아래와 같이 users deployment 에서 auth Service 의 IP 를 사용할 수 있도록 업데이트
CSI (Container Storage Interface)는 Kubernetes에서 다양한 스토리지 솔루션을 쉽게 사용할 수 있도록 설계된 추상화임 다양한 스토리지 공급업체는 CSI 표준을 구현하는 자체 드라이버를 개발하여 스토리지 솔루션이 Kubernetes와 함께 작동하도록 할 수 있음 (연결되는 스토리지 솔루션의 내부에 관계없이) AWS는 Amazon EBS , Amazon EFS 및 Amazon FSx for Lustre 용 CSI 플러그인을 제공함
hostPath 를 사용하는 Persistent Volume 샘플을 만들어서 이해도를 높여봄
(Persistent Volume 에서 hostPath 를 사용한다는 말은,
Cluster 를 단일 노드 하나에서만 정의한다는 말이 됨)
host-pv.yaml 이라는 이름의 yaml 파일을 새로 만들어서 Persistent Volume 을 정의해 봄
< host-pv.yaml >
apiVersion: v1 kind: PersistentVolume metadata: name: host-pv spec: capacity: storage: 4Gi volumeMode: Filesystem #Filesystem 과 Block 으로 나뉨 storageClassName: standard #default sc 이름이 standard 라서 standard 를 넣음 accessModes: - ReadWriteOnce hostPath: path: /data #노드의 /data 가 PV 에 연결됨 type: DirectortOrCreate
accessModes 는 아래와 같은 mode 를 제공함
- ReadWriteOnce : 단일 노드로부터의 rw 요청을 받을 수 있도록 mount 되는 Volume - ReadOnlyMany : 여러 노드로부터의 r 요청만 받을 수 있도록 mount 되는 Volume - ReadWriteMany : 여러 노드로부터의 rw 요청을 받을 수 있도록 mount 되는 Volume
(위 예제에서 hostPath 는 단일 노드 환경에서만 사용 가능하므로
사용할 수 있는 mode 는 오직 ReadWriteOnce 뿐임)
Kube 는 Storage Class 라는 개념을 갖고 있음
kubectl get sc 명령으로 확인 가능하며default sc 도 존재함
Storage Class 는 kube 에서 관리자에게
Storage 관리 방법과 Volume 구성 방법을 세부적으로 제어할 수 있게 해주는 개념임
SC 는 hostPath Storage 를 프로비저닝 해야하는 정확한 Storage 를 정의함 (?뭔말임?)
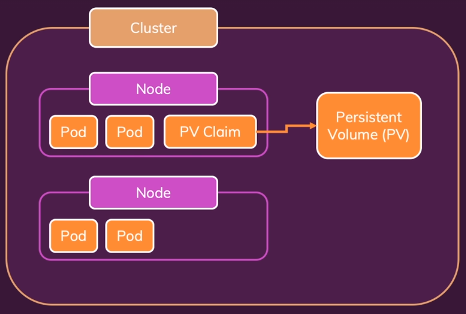
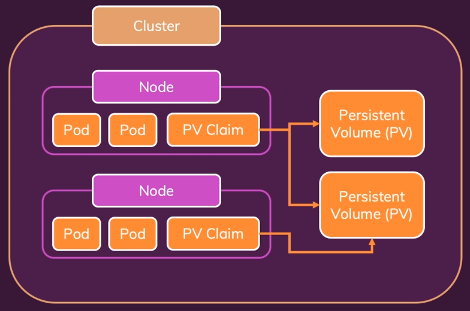
PV 는 한 번만 설정하면(심지어 다른 사람이 설정해도 됨)
여러 pods 에서 함께 접근하여 사용 가능한 저장소가 됨
이렇게 생성한 PV 를 Pods 가 접근해서 사용 가능하게 만들려면
pods 가 PV 에 접근하는 것을 도와주는 PV Claim 을 생성해야 함
두 가지를 추가 설정하면 됨
1. PV Claim 을 생성하는 yaml
2. (PV 를 사용하려는) pods 의 yaml 에서 PV Claim 사용하도록 설정
1번(PV Claim 을 위한 yaml)을 생성해보자.
이름은 host-pvc.yaml
< host-pvc.yaml >
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: host-pvc spec: volumeName: host-pv #위에 PV 를 정의할 때 설정한 이름을 여기 넣어서, 해당 PV 와 PVC를 연결함 accessModes: - ReadWriteOnce storageClassName: standard #default sc 이름이 standard 라서 standard 를 넣음 resources: requests: storage: 4Gi #PVC 에서 요청하는 크기는, PV 의 stoage 이하만 가능
2번(pods 의 yaml 에 PVC 사용 설정)을 추가 설정해보자
deployment yaml 에서 pods 의 spec 을 정의하는 부분에 volumes 를 아래와 같이 설정
.... spec: containers: - name: demo image: demo volumeMounts: - mountPath: /app/demo name: demo-volume volumes: - name: demo-volume persistentVolumeClaim: claimName: host-pvc#위에서 PVC 를 정의할 때 사용한 이름을 가져다가 설정함
PV 가 데이터를 저장하는 곳은 어디이기에 Nodes 와 Pods 로부터 독립적인걸까?
PVC 가 필요한 이유는 무엇일까?
왜 PV 와 Pods 사이에 중간다리 역할이 필요한거지?
PV 의 권한과 PVC 의 권한은 왜 구분되어있는걸까?
위에서 만든 PV yaml 와 PVC yaml 및 업데이트한 deployment yaml 을 kube 에 띄움
kubectl apply -f=host-pv.yaml
kubectl apply -f=host-pvc.yaml
kubectl apply -f=deployment.yaml
PV, PVC 가 잘 올라왔는지 아래 명령어로 확인
kubectl get pv
kubectl get pvc
일반 Volume 와 Persistent Volume 의 차이를 알아봄
일반 Volumes
Persistent Volumes
Container 의존성
Container 재시작, 제거 되어도 데이터 유지
Container 재시작, 제거 되어도 데이터 유지
Pod 의존성
emptyDir 타입이라면, Pods 가 사라지면 데이터도 사라짐 hostPath 를 사용한다면 Pods 가 사라져도 데이터가 사라지진 않지만, Nodes 에 종속되기 때문에 (Nodes 가 내려가면 사용 불가, 단일 Node 에서만 사용 등에 이유로) 글로벌 수준에서 관리하기 어려움
Pod 의존성 없음 Node 의존성 없음
설정 위치
Pods 를 정의하는 deployment yaml 에 설정
PV 를 위한 yaml 에 설정 구성이 하나의 파일에 standalone 으로 존재하므로 재사용하거나 관리하기 용이함
프로젝트 크기
소규모 프로젝트에서 사용하기에 용이
대규모 프로젝트에서 사용하기에 용이
deployment yaml 에 설정된 값을 (Container 내에서 동작하는) application code 내에서 사용 가능